

Se um equipamento falha durante a madrugada, o estrago pode ser grande se o problema só for descoberto horas depois, no início do próximo turno. Esse é um cenário mais comum do que muitas equipes de manutenção imaginam. Atrasos na detecção, repetidos dia após dia, somam milhões de reais em reparos que poderiam ter sido evitados e em horas de produção perdidas.
É para medir exatamente esse “vazio” entre falha e identificação que surgiu o indicador Mean Time to Detect (MTTD) - ou Tempo Médio de Detecção.
Em termos simples, o MTTD mostra quanto tempo os problemas ficam ocultos depois que começam. Quanto mais rápido você identifica uma anomalia, menor é o impacto e mais barato é corrigi-la. Mas acelerar a detecção não depende apenas de boa vontade ou de aumentar o número de inspeções.
Neste guia, você vai entender como calcular o MTTD, identificar o que atrasa o processo de detecção e aplicar estratégias que comprovadamente ajudam equipes de manutenção a flagrar falhas antes que elas se transformem em paradas críticas e reparos milionários.
O que é o Mean Time to Detect
O MTTD mede o tempo médio entre a ocorrência de uma falha e o momento em que a equipe de manutenção a identifica. Em outras palavras, mostra o quão rápido sua equipe consegue perceber que algo saiu do normal, desde o início da falha até que alguém registre oficialmente o problema.
Imagine a cena: um rolamento da linha principal começa a superaquecer durante a noite. Ninguém percebe até que, horas depois, o próximo turno escuta um ruído estranho e decide investigar. Esse intervalo entre o surgimento da falha e sua descoberta é justamente o que o MTTD captura.
Quando esse tipo de atraso se repete em diferentes ativos, o indicador revela em média quanto tempo as falhas passam despercebidas. A fórmula é direta:
MTTD = Tempo total entre falha e detecção ÷ Número total de falhas
Por exemplo, se em vários eventos o atraso médio entre a falha e a identificação foi de algumas horas, a média desses atrasos será o seu MTTD.
Cada minuto que uma falha permanece oculta, o risco aumenta. O que começa como uma vibração leve pode evoluir para uma quebra catastrófica. Diferente de áreas como TI ou cibersegurança, onde o MTTD mede a identificação de ameaças digitais, na manutenção industrial ele foca exclusivamente em falhas físicas dos equipamentos.
Um evento de falha começa no exato instante em que o ativo sai de seu padrão normal de operação. Já o tempo até a detecção vai desse momento inicial até quando a equipe de manutenção identifica e registra a ocorrência.
Por que o MTTD é Importante para as Equipes de Manutenção
Se uma bomba crítica em uma planta química opera por horas com uma vedação comprometida antes que alguém perceba, o custo do reparo dispara em comparação com o que seria gasto se o problema fosse identificado logo no início. Em resumo: detectar rápido significa impedir que falhas pequenas virem desastres caros.
Mas o impacto financeiro não se resume a um único reparo. Quanto maior o tempo de detecção, maior o efeito dominó: componentes em falha passam a sobrecarregar outros, gerando danos secundários.
Um rolamento desgastado que permanece invisível pode comprometer o eixo, o alojamento e até equipamentos conectados, elevando drasticamente o custo - algo muito além da simples troca de peça. É por isso que técnicas como a análise de vibração em rolamentos são tão eficazes para identificar sinais precoces de desgaste.
Detecção ágil também encurta as janelas de parada. E, quando somada ao monitoramento preditivo, reduz ainda mais os custos não planejados. Quanto antes você enxerga o problema, mais simples é o reparo: menos peças, menos horas de trabalho, e, em muitos casos, a possibilidade de encaixar a correção em uma preventiva já programada, sem precisar de uma parada emergencial.
Reduzir o MTTD traz ganhos concretos para sua operação:
- Menor custo de reparo: identificar cedo evita que falhas simples evoluam para quebras complexas que exigem peças caras e mão de obra intensiva.
- Menos tempo de máquina parada: problemas resolvidos rápido não chegam a provocar paradas completas de equipamentos.
- Maior vida útil dos ativos: ao tratar a causa raiz antes do ponto de não retorno, você evita a substituição prematura de máquinas.
- Planejamento de manutenção mais eficiente: com tempos de detecção consistentes, fica mais fácil prever janelas de intervenção e alocar recursos de forma assertiva.
Essa base de detecção rápida é o que sustenta a virada de chave: sair do modo reativo (ou seja, sempre “apagando incêndios”) e avançar rumo a uma manutenção realmente preditiva e estratégica.
Como Calcular e Acompanhar o MTTD
Calcular o MTTD exige uma coleta sistemática de dados e métodos consistentes de registro, algo que a maioria das equipes de manutenção já consegue implementar com seus sistemas atuais. O processo tem três etapas críticas que se complementam e formam uma métrica de detecção confiável.
Veja abaixo:
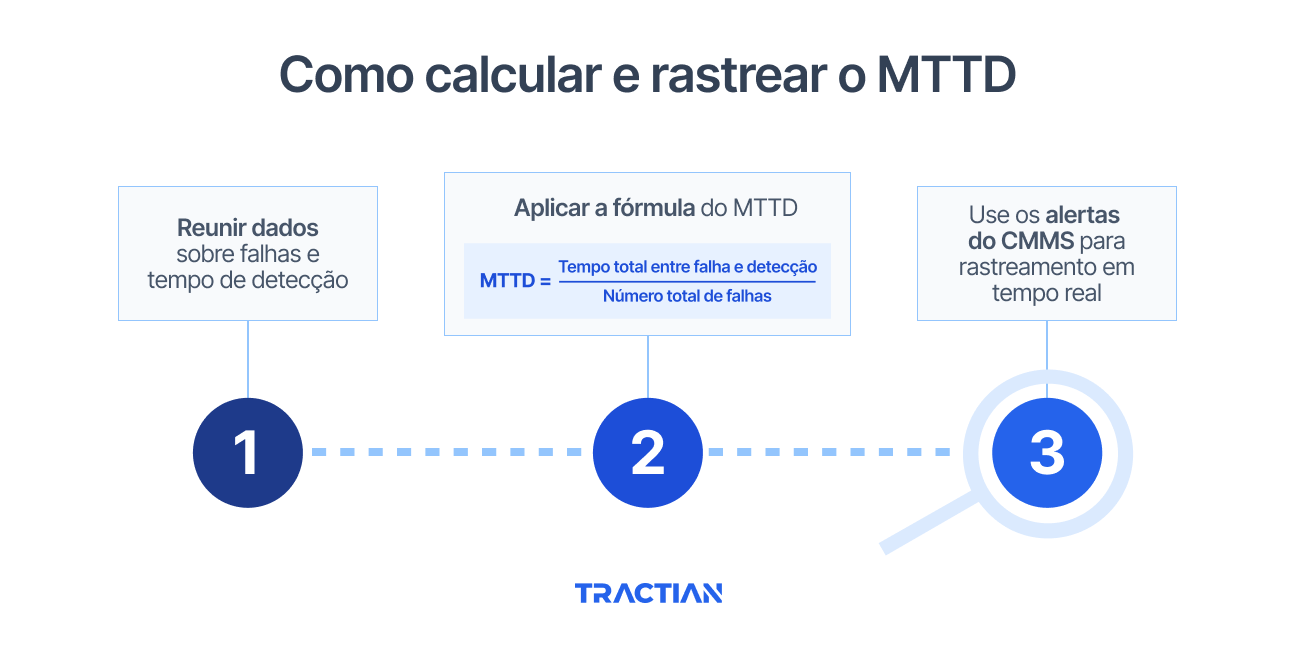
1. Reunir Dados de Falha e Tempo de Detecção
O cálculo começa com a marcação precisa dos horários de ocorrência da falha e da sua identificação. Muitas vezes, o momento real em que a falha acontece é diferente daquele em que alguém percebe o problema. Por isso, é necessário combinar múltiplas fontes para montar a linha do tempo com precisão.
Registros de produção, leituras de sensores e apontamentos de operadores ajudam a identificar quando o equipamento começou a sair do padrão normal de operação. Altas repentinas de temperatura, aumento de vibração ou quedas de pressão registradas no histórico muitas vezes revelam o início real da falha, mesmo que ela não tenha sido percebida de imediato.
O tempo de detecção, por sua vez, é registrado quando a equipe de manutenção identifica e documenta o problema. Isso pode acontecer durante uma inspeção de rotina, quando um operador relata um ruído incomum ou a partir de um alerta automático. O ponto-chave é manter consistência nos registros de toda a equipe.
2. Aplicar a Fórmula do MTTD
Depois de levantar os dados de diversos eventos de falha, a fórmula é simples:

Onde:
- Tempo de Detecção = quando o problema foi identificado e registrado.
- Tempo de Ocorrência da Falha = quando o ativo começou a operar fora do padrão.
O resultado pode ser expresso em minutos ou horas, dependendo do nível de detalhe dos registros.
Exemplo prático: Imagine que você analisa cinco falhas e encontra os seguintes atrasos de detecção (em horas): 1,5 | 2 | 1 | 3 | 1,2.

O cálculo da média desses atrasos define o seu MTTD.
Ou seja, quanto menor o MTTD, mais rápido sua equipe ou sistema identifica problemas. Mas o contexto importa: um MTTD de 4 horas pode ser aceitável em um motor secundário de baixo risco, mas seria catastrófico em uma bomba crítica de processo.
3. Usar Alertas do CMMS para Acompanhamento em Tempo Real
Plataformas modernas de CMMS automatizam boa parte do acompanhamento do MTTD, registrando com precisão tanto os eventos de falha quanto o momento em que a detecção acontece. Configuradas corretamente, elas capturam o instante exato em que um alerta é disparado e quando a equipe de manutenção o reconhece.
Alertas automáticos eliminam a demora humana nesse processo. Em vez de esperar pela próxima ronda de inspeção, os alertas baseados em condição notificam imediatamente as pessoas certas quando parâmetros ultrapassam os limites. Isso reduz o tempo de detecção de horas para minutos.
Além disso, os relatórios do CMMS revelam padrões: alguns ativos, turnos ou tipos de falha tendem a apresentar atrasos maiores na detecção. Por exemplo, pode ser que falhas em sistemas hidráulicos demorem mais para serem notadas que falhas elétricas, ou que o turno da noite tenha tempos de detecção mais longos que o do dia.
Desafios que Atrasam a Detecção
A maioria das equipes de manutenção enfrenta obstáculos previsíveis que aumentam o tempo de detecção. Identificar esses gargalos é o primeiro passo para reagir mais rápido. E, quase sempre, os atrasos mais comuns estão ligados a lacunas de monitoramento e a sistemas de informação que não se comunicam entre si.
Monitoramento Automatizado Insuficiente
Confiar apenas em inspeções periódicas cria atrasos inevitáveis, porque as falhas não esperam a próxima ronda. Se um rolamento começa a falhar entre duas inspeções programadas, o problema pode passar despercebido por horas - tempo suficiente para que o dano se acumule até a próxima checagem.
O fator humano reforça esse desafio. Inspetores podem deixar passar mudanças sutis no comportamento do equipamento, especialmente quando estão sobrecarregados ou distraídos com outras prioridades. Mesmo técnicos experientes podem não perceber sinais iniciais se não estiverem atentos a indicadores específicos.
Esse tipo de abordagem tradicional gera pontos cegos entre os intervalos de inspeção. O ativo pode falhar, se recuperar parcialmente e falhar de novo sem que ninguém perceba o padrão. Esse comportamento intermitente costuma indicar problemas graves de fundo que rondas manuais simplesmente não conseguem capturar.
Dados Fragmentados Entre Sistemas
Quando os dados de produção estão em um sistema, os registros de manutenção em outro e as leituras de sensores em um terceiro, sinais de alerta críticos acabam se perdendo nesses “vazios”. Um operador pode notar uma vibração anormal, mas se essa observação só chega à equipe de manutenção na reunião do próximo turno, o tempo de detecção já foi desnecessariamente ampliado.
A fragmentação de dados também impede o reconhecimento de padrões. Tendências de temperatura que, vistas em conjunto, mostrariam claramente o desgaste de um rolamento podem parecer normais quando espalhadas por sistemas diferentes ou analisadas isoladamente.
Além disso, atrasos de comunicação entre turnos e departamentos adicionam outra camada de lentidão. Quando a operação percebe algo estranho mas não aciona a manutenção de imediato, toda a resposta é comprometida.
Principais obstáculos de detecção
- Inspeções manuais infrequentes, que deixam falhas passarem entre as rondas programadas.
- Ausência de sensores em componentes críticos, que podem falhar sem cobertura de monitoramento.
- Comunicação deficiente entre turnos ou áreas, que atrasa a transferência de informações.
- Treinamento insuficiente sobre sinais de falha, fazendo com que a equipe ignore indicadores importantes.
- Excesso de alarmes falsos, que leva técnicos a desconsiderar alertas realmente relevantes.

3 Estratégias para Reduzir o MTTD
Construir uma capacidade de detecção mais rápida exige uma abordagem sistemática que combine tecnologia, processos e expertise humana. As estratégias mais eficazes atacam tanto os fatores técnicos quanto os organizacionais que influenciam a velocidade de identificação das falhas - veja abaixo:
1. Implementar Sensores de Manutenção Preditiva
A tecnologia de sensores transforma a detecção de algo pontual e esporádico em um monitoramento contínuo, capaz de capturar problemas no exato momento em que começam a surgir.
- Sensores de vibração detectam desgaste em rolamentos.
- Sensores de temperatura identificam superaquecimento.
- Sensores acústicos captam sons anormais que indicam falhas mecânicas.
Cada tipo de equipamento exige um conjunto específico de sensores. Máquinas rotativas se beneficiam de vibração e temperatura, sistemas hidráulicos demandam sensores de pressão e vazão, enquanto equipamentos elétricos precisam de monitoramento de corrente e tensão para flagrar falhas antes que se tornem críticas.
O segredo está em interpretar corretamente os dados: leituras de referência definem a faixa normal de operação, e a análise de tendências revela mudanças graduais que indicam desgaste ou degradação. Esse monitoramento contínuo reduz o tempo de detecção de horas para minutos.
2. Integrar Alertas e Notificações em Tempo Real
Sistemas de alerta automatizados eliminam a lentidão humana no processo de detecção, notificando imediatamente as pessoas certas quando algo sai do padrão. Os alertas baseados em condição disparam quando leituras de sensores ultrapassam limites configurados, garantindo atenção a problemas em desenvolvimento antes que eles se transformem em falhas completas.
O ajuste dos limiares de alarme precisa ser equilibrado: se muito baixos, geram sobrecarga de falsos positivos; se muito altos, deixam escapar sinais importantes. A prática mais eficiente é trabalhar com múltiplos níveis de severidade.
As notificações móveis chegam aos times de manutenção em qualquer ponto da planta, eliminando atrasos causados pela distância física. Push notifications em smartphones ou tablets garantem que os alertas críticos recebam atenção imediata, independentemente da localização.
3. Padronizar Treinamentos e Procedimentos
Mesmo com sistemas automatizados, o fator humano continua determinante na velocidade da detecção. Por isso, equipes de manutenção precisam de procedimentos padronizados para monitorar equipamentos, diretrizes claras para identificar sinais de falha e treinamentos consistentes sobre responsabilidades de detecção.
Os programas de capacitação devem focar em indicadores precoces específicos de cada ativo:
- Falhas em rolamentos geram padrões característicos de vibração.
- Cavitação em bombas produz sons distintos.
- Defeitos elétricos se manifestam em assinaturas térmicas bem definidas.
Equipes treinadas para reconhecer esses sinais conseguem detectar problemas antes mesmo de os sistemas automáticos dispararem um alerta.
A combinação de monitoramento contínuo por sensores com a expertise do time de manutenção cria o sistema de detecção mais robusto possível, em que a tecnologia captura o que o olho humano não vê, e os técnicos experientes oferecem o contexto e o julgamento que os algoritmos ainda não conseguem entregar.
Comparando o MTTD com o MTTR e Outros Indicadores
Entender como o Tempo Médio de Detecção (MTTD) se relaciona com outros indicadores de manutenção é essencial para ter uma visão completa da performance da sua equipe. Cada métrica mede um aspecto específico do processo, mas, juntas, revelam onde estão as maiores oportunidades de melhoria.
A relação entre MTTD e MTTR (Mean Time to Repair, ou Tempo Médio de Reparo) mostra claramente onde otimizar:
- Se o MTTD é baixo, mas o MTTR é alto, significa que os problemas são identificados rapidamente, mas os reparos ainda enfrentam dificuldades.
- Já quando o MTBF (Mean Time Between Failures - Tempo Médio Entre Falhas) cai enquanto o MTTD permanece estável, sua capacidade de detecção está consistente, mas o plano de manutenção preventiva precisa de atenção.
Focar na redução do MTTD costuma gerar efeitos em cascata nos demais indicadores. Detectar cedo geralmente significa reparos mais simples, menos danos secundários e maior confiabilidade dos ativos. Por isso, o MTTD é considerado uma métrica de alto impacto na evolução da manutenção como um todo.
Como o Monitoramento de Condição da Tractian Pode Transformar Sua Indústria
Não importa o quão experiente seja sua equipe de manutenção: extrair valor real da detecção depende de ter as ferramentas e processos certos. A detecção rápida traz estrutura, visibilidade e controle para a operação, transformando o trabalho reativo de “apagar incêndios” em uma gestão de ativos verdadeiramente proativa.
O problema é que a maioria dos sistemas de monitoramento do mercado ou é complexa demais para ser implantada rapidamente, ou é simples demais para gerar insights acionáveis. O que se ganha em sofisticação se perde na prática e acaba-se com sensores disparando falsos alarmes, dados presos em silos e equipes que deixam de confiar nos alertas.
O monitoramento de condição da Tractian foi desenvolvido exatamente para eliminar esses pontos de frustração. Desde o primeiro dia, ele entrega insights precisos e acionáveis, que sua equipe pode usar com confiança. Análise de vibração, monitoramento de temperatura e diagnósticos automatizados são apresentados de forma clara, acessível e diretamente alinhada ao processo real de manutenção.
Nossa plataforma vai além do simples disparo de alertas: ela oferece contexto e recomendações práticas. Com tecnologia de IA patenteada para detecção de falhas, análise automática de causa raiz e integração fluida ao seu fluxo de trabalho existente, você não está apenas detectando falhas mais rápido, mas também evita que elas aconteçam.
Quer ver na prática? Solicite seu teste gratuito e descubra como o monitoramento de condição da Tractian ajuda sua operação a ser mais confiável, eficiente e preditiva.
