

Un sensor solo no es un sistema de monitoreo. Es el punto de partida. Lo que convierte la medición de vibraciones en una herramienta de mantenimiento real son los cuatro componentes que trabajan en conjunto: el sensor, la conectividad, la plataforma de análisis y el proceso de respuesta.
Si uno falla o está mal configurado, los otros tres no sirven de nada. Un sensor excelente que transmite datos a una plataforma sin capacidad de diagnóstico produce números que nadie sabe interpretar. Una plataforma con IA precisa que genera alertas que nadie atiende no evita un solo paro.
Este artículo describe cada componente, qué determina su calidad y cómo interactúan para formar un sistema que realmente reduce paros no programados. Entender el sistema completo es lo que separa una implementación exitosa de una inversión en hardware que no generó resultados.
Por qué importa entender el sistema completo, no solo el sensor
La conversación en planta suele empezar y terminar en el hardware. Qué sensor, de qué marca, con qué rango de frecuencia. El sensor es lo más tangible y lo más fácil de comparar entre opciones.
Pero las plantas que implementaron sensores y no obtuvieron resultados no fallaron por el sensor. Fallaron porque el sistema alrededor del sensor no estaba bien construido: la conectividad era intermitente, la plataforma no generaba diagnósticos accionables o el equipo no tenía un proceso claro para responder a las alertas.
El sensor es necesario pero no suficiente. Igual que un laboratorio de análisis de sangre no ayuda a nadie si los resultados no llegan al médico, o si el médico no tiene protocolo para actuar sobre ellos, un sensor de vibración sin sistema completo solo genera datos que se acumulan sin impacto.
La evaluación de un sistema de monitoreo debe hacerse componente por componente, preguntando qué tan bien funciona cada uno y qué pasa cuando alguno falla. Esa evaluación sistemática es lo que predice si el sistema va a generar valor o si va a convertirse en otro proyecto de tecnología que el equipo termina ignorando.
Componente 1. El sensor: la fuente de datos
El sensor es el punto de contacto con la máquina. Captura la señal vibratoria y la convierte en datos procesables. Su calidad determina qué fallas pueden detectarse y con cuánta anticipación.
Un sensor con rango de frecuencia insuficiente no detecta mal las fallas tempranas en rodamientos: directamente no las ve. La señal existe en la máquina, pero el sensor no tiene la capacidad de captarla. Y como no genera alerta, el equipo opera con la falsa seguridad de que todo está bien.
Qué define la calidad del dato que genera un sensor
Rango de frecuencia. Determina qué modos de falla son visibles. Para fallas tempranas en rodamientos, se necesita rango de al menos 10 kHz. Para desbalance y desalineación, hasta 1 kHz es suficiente.
Número de ejes de medición. Un sensor triaxial captura vibración radial, axial y vertical simultáneamente. Un sensor uniaxial solo captura la dirección en que está orientado. En activos con múltiples modos de falla posibles, el triaxial ofrece cobertura diagnóstica más completa.
Frecuencia de muestreo. Define la resolución temporal de los datos. Una frecuencia alta permite detectar eventos de corta duración que una frecuencia baja simplemente no registra.
Punto de montaje y método de fijación. La señal que llega al sensor depende del contacto con la máquina. Un sensor atornillado directamente a la carcasa transmite la señal con mucha más fidelidad que uno adherido con magneto sobre una superficie pintada u oxidada.
Sensor de vibración solo vs. sensor con ultrasonido integrado
El ultrasonido detecta fallas en etapas más tempranas que la vibración clásica, especialmente en rodamientos y problemas de lubricación. Las señales acústicas de alta frecuencia generadas por fricción o impacto en un rodamiento en etapa inicial de desgaste son visibles en ultrasonido semanas antes de que aparezcan en el espectro de vibración.
Un sensor que combina ambas tecnologías amplía la ventana de detección sin necesidad de dos dispositivos separados. En la práctica, esto significa más tiempo disponible para planificar la intervención y menor probabilidad de que la falla llegue al punto F antes de que el equipo actúe.
La combinación también reduce el número de puntos de instalación necesarios. En lugar de instalar un sensor de vibración y un sensor de ultrasonido separados en el mismo activo, un dispositivo integrado cubre ambos rangos con una sola instalación y una sola fuente de datos en la plataforma.
Componente 2. La conectividad: cómo llegan los datos de la máquina a la plataforma
Un sensor que no transmite sus datos de forma confiable y continua no aporta más que una medición puntual. La conectividad define si el sistema puede operar sin interrupciones, sin depender de infraestructura de red de la planta y sin perder lecturas críticas.
La conectividad es el componente que más frecuentemente se subestima en la evaluación inicial. En el piloto, todo funciona bien porque el sensor está cerca del gateway y la señal es buena. El problema aparece al escalar: cuando el sensor está en una zona de la planta con interferencia electromagnética alta, con estructuras metálicas que bloquean la señal o lejos del punto de acceso.
Opciones de conectividad y sus implicaciones en planta
Redes celulares 3G/4G/LTE. Independientes de la infraestructura de la planta. Funcionan en cualquier ubicación con cobertura celular, no requieren coordinación con el área de IT y pueden desplegarse en días, no en semanas.
Redes industriales propias. Mayor control sobre el ancho de banda y la seguridad de los datos. Requieren inversión en infraestructura y dependencia del área de tecnología de información para configuración y mantenimiento.
Conexión local con sincronización posterior. Adecuada para plantas con conectividad limitada en algunas zonas. El sensor almacena los datos localmente y los sincroniza cuando recupera conexión. El problema es que genera huecos en el historial que pueden coincidir con el momento de la falla.
Qué pasa cuando la conectividad falla
Los datos no transmitidos son datos perdidos. En activos críticos con fallas de progresión rápida, un hueco de pocas horas en el historial puede ser suficiente para perder la ventana de intervención.
Hay también un efecto sobre la confiabilidad del modelo de IA. Los algoritmos que construyen la línea base del activo y detectan desviaciones necesitan datos continuos y consistentes. Un historial con huecos frecuentes reduce la precisión del diagnóstico y aumenta los falsos positivos.
La evaluación de la conectividad debe hacerse en las condiciones reales de instalación, no en el banco de pruebas del laboratorio. Instalar el sensor en el activo más exigente de la planta durante el piloto es la forma más efectiva de detectar problemas de conectividad antes de comprometer la inversión completa.
Componente 3. La plataforma de análisis: donde el dato se convierte en diagnóstico
Los datos de vibración en bruto no sirven para tomar decisiones de mantenimiento. Un valor de 4.7 mm/s de velocidad de vibración no le dice nada al técnico si no sabe si ese valor es alto o bajo para ese activo en ese modo de operación.
La plataforma procesa la señal, la compara con la línea base del activo, identifica patrones y genera diagnósticos con contexto. Sin este componente, el equipo de mantenimiento recibe números, no información accionable.
La diferencia entre plataformas no está en la presentación visual ni en la cantidad de dashboards disponibles. Está en la calidad del diagnóstico: qué tan bien el sistema identifica qué está pasando, en qué componente y con qué nivel de urgencia, sin requerir que un analista certificado interprete manualmente cada alerta.
Qué debe hacer una plataforma de análisis de vibraciones
Construir la línea base individual de cada activo, no aplicar umbrales genéricos. El mismo nivel de vibración puede ser normal para un motor y anómalo para otro, dependiendo de su diseño, su carga y su historial. Los umbrales genéricos generan demasiados falsos positivos en activos robustos y pueden pasar por alto fallas en activos sensibles.
Detectar desviaciones y clasificarlas por tipo de falla potencial. No basta con alertar que "la vibración subió". El sistema debe indicar si el patrón corresponde a desbalance, desalineación, falla en rodamiento u holgura mecánica.
Generar alertas con contexto: qué componente, qué modo de falla, qué nivel de urgencia. El técnico debe poder tomar una decisión informada a partir de la alerta sin necesidad de un análisis adicional.
Almacenar el historial completo para análisis de tendencias y causa raíz. El valor de los datos aumenta con el tiempo. Un historial de seis meses permite diagnósticos que son imposibles con datos de dos semanas.
El rol de la inteligencia artificial en el diagnóstico
La IA no reemplaza al analista. Lo que hace es procesar el volumen de datos que ningún analista puede revisar manualmente, identificar patrones que son invisibles en una lectura puntual y priorizar qué activos necesitan atención.
El técnico valida y decide. La IA proporciona el diagnóstico preliminar; el técnico aporta el contexto de campo que la plataforma no puede ver: si hubo un cambio en el proceso esa semana, si el activo acaba de salir de una intervención, si hay condiciones ambientales que explican la variación.
Con el tiempo, esa retroalimentación del técnico mejora el modelo. El sistema aprende qué desviaciones generaron fallas reales y cuáles resultaron ser variaciones normales del proceso. Ese aprendizaje progresivo es lo que hace que las alertas sean cada vez más precisas y confiables.
Componente 4. El proceso de respuesta: lo que cierra el ciclo
El sistema de monitoreo más preciso del mundo no evita un paro si nadie actúa a tiempo con la información correcta. El cuarto componente no es tecnológico: es el proceso que define quién recibe la alerta, cuándo, qué hace con ella y cómo queda documentada la intervención.
En muchas implementaciones fallidas, los tres primeros componentes funcionaban bien. El sensor captaba la señal, la conectividad la transmitía y la plataforma generaba alertas precisas. El problema era que las alertas llegaban a una bandeja de correo que nadie revisaba con frecuencia, o que cuando llegaban al técnico correcto no había un procedimiento claro de qué hacer a continuación.
El proceso de respuesta debe definirse antes de activar el sistema, no después de la primera alerta. Qué técnico recibe cada tipo de alerta, en qué canal, con qué tiempo de respuesta esperado y qué sucede si no responde en ese tiempo. Sin esas definiciones, el sistema genera información que no genera acción.
Del diagnóstico a la acción
La alerta generada por la plataforma debe traducirse en una acción concreta, asignada al técnico correcto, con el procedimiento de intervención disponible. Si ese paso es manual y depende de que alguien recuerde actuar, el tiempo de respuesta se alarga y la ventana de intervención se reduce.
En sistemas maduros, la alerta de la plataforma dispara automáticamente la notificación al técnico asignado a ese activo, con el contexto del diagnóstico y el procedimiento de intervención recomendado. El técnico confirma la recepción, valida en campo y documenta la acción.
La documentación de la intervención es parte del proceso, no una tarea opcional. Cada intervención registrada con sus hallazgos reales alimenta el historial del activo y mejora los diagnósticos futuros del sistema.
La retroalimentación como parte del sistema
Cuando el técnico confirma o descarta el diagnóstico después de la intervención, esa información regresa al sistema. El ciclo completo, detección, diagnóstico, intervención y retroalimentación, es lo que hace que el sistema mejore con el tiempo.
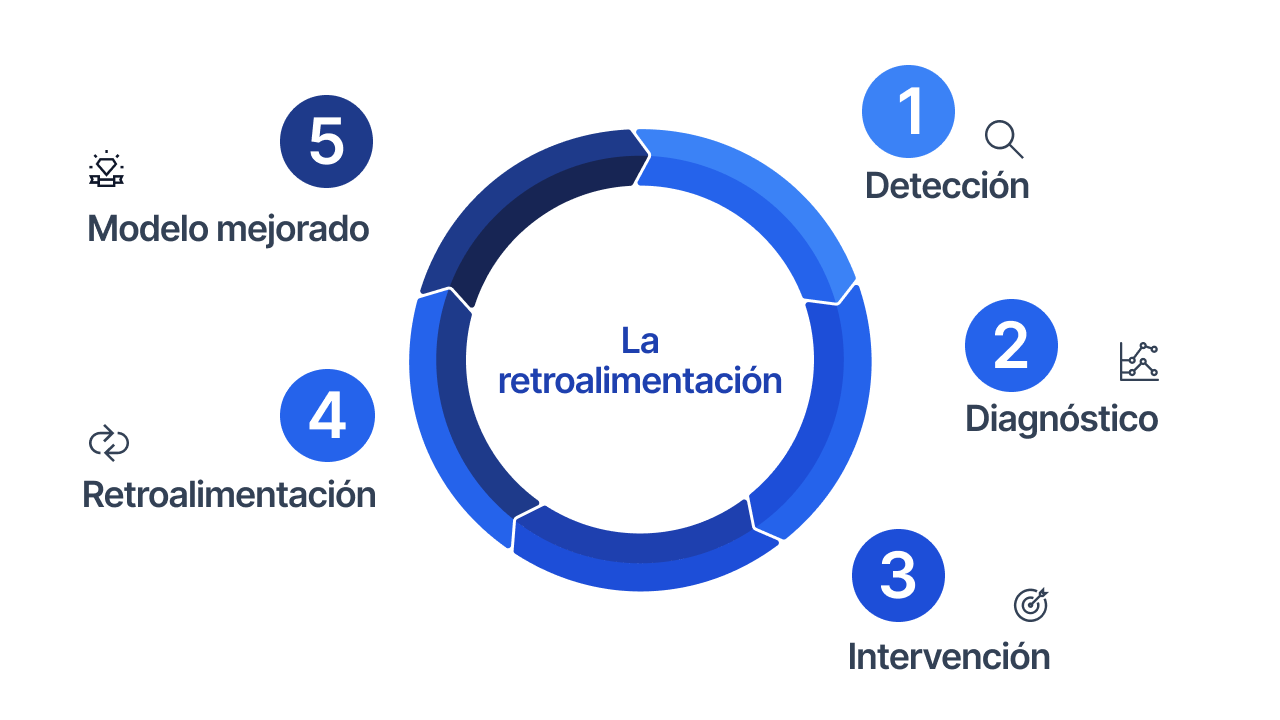
Sin ese cierre, el sistema no aprende. Genera alertas con la misma precisión el primer mes que el décimo. La retroalimentación es el mecanismo por el que la experiencia del técnico en campo enriquece el modelo de IA, y por el que el modelo de IA se adapta a las particularidades de cada planta.
Un proceso de retroalimentación bien implementado también genera un historial de fallas real, con la causa confirmada por el técnico en campo, no la causa estimada por el algoritmo. Ese historial es el activo de información más valioso que un programa de mantenimiento puede construir.
Cómo se ven los 4 componentes integrados en la práctica
En una planta bien estructurada, el sensor detecta un cambio en la firma de vibración de un rodamiento. La plataforma lo compara con el histórico del activo, identifica un patrón de desgaste incipiente y genera una alerta clasificada como nivel 2: no urgente, intervenir en los próximos 15 días.
El técnico recibe la alerta en su aplicación con el diagnóstico completo: qué activo, qué componente, qué tipo de falla, qué nivel de severidad. Revisa el historial del activo, confirma en campo que la firma espectral es coherente con el diagnóstico y genera la solicitud de intervención para la siguiente ventana de mantenimiento planificado.
El rodamiento se cambia sin paro de emergencia. El técnico documenta los hallazgos en campo y confirma el diagnóstico. El sistema aprende del ciclo y ajusta su modelo para ese activo específico.
Eso es un sistema de monitoreo de vibraciones funcionando. No solo un sensor en la máquina.
Errores frecuentes al implementar un sistema de monitoreo de vibraciones
Conocer los componentes del sistema no es suficiente. La mayoría de las implementaciones fallidas cometieron al menos uno de estos errores, y en muchos casos más de uno.
Empezar por los activos más fáciles, no por los más críticos. Instalar los primeros sensores en activos accesibles y de bajo impacto puede ser tentador como forma de aprender el sistema sin riesgos. El problema es que esos activos rara vez generan alertas significativas, lo que lleva al equipo a concluir que el sistema no detecta nada cuando en realidad no hay nada que detectar en esos activos.
Subestimar la importancia de la línea base. Los primeros días de instalación son el periodo en que el sistema aprende qué es normal para ese activo. Si durante ese periodo el activo opera bajo condiciones atípicas (carga reducida, proceso de puesta en marcha), la línea base quedará sesgada y las alertas futuras serán menos precisas.
No definir el proceso de respuesta antes de activar el sistema. Cuando llega la primera alerta real y nadie sabe a quién asignarla ni qué procedimiento seguir, el tiempo de respuesta se alarga y se pierde la ventana de intervención. El proceso de respuesta debe estar definido antes del primer día de operación del sistema.
Desconectar la retroalimentación del ciclo. Si los técnicos no documentan el resultado de las intervenciones, el sistema no puede aprender. En pocos meses, las alertas pierden precisión porque el modelo no recibe información de retorno sobre cuáles diagnósticos fueron correctos y cuáles no.
Indicadores para medir si el sistema de monitoreo está funcionando
Un sistema de monitoreo de vibraciones bien implementado debe mostrar mejoras medibles en los indicadores de mantenimiento. Si después de seis meses de operación los indicadores no han cambiado, hay un componente del sistema que no está funcionando correctamente.
Porcentaje de fallas detectadas en el punto P vs. el punto F. Este es el indicador más directo de la efectividad del monitoreo. Si la mayoría de las intervenciones siguen siendo reactivas, el sistema no está detectando las fallas con suficiente anticipación.
Reducción de intervenciones de emergencia. A medida que el sistema detecta fallas en etapas tempranas, el número de paros no programados debe disminuir. Una reducción del 30% en los primeros seis meses es un resultado alcanzable en plantas con buena implementación.
Tasa de confirmación de alertas. El porcentaje de alertas que resultan en fallas reales confirmadas en campo indica la precisión del sistema. Una tasa alta de falsos positivos señala problemas en el componente de análisis o en la línea base del activo.
Smart Trac de Tractian: los 4 componentes en una sola plataforma
Smart Trac integra los cuatro componentes en una solución unificada. El sensor captura vibración y ultrasonido de forma simultánea y continua. La conectividad celular transmite los datos sin depender de la infraestructura de red de la planta.
La IA de Tractian procesa la señal en contexto, construye la línea base individual de cada activo y genera diagnósticos de causa raíz con nivel de urgencia, componente afectado y acción recomendada. El técnico recibe la alerta directamente en su dispositivo con toda la información necesaria para actuar.
El ciclo se cierra cuando el técnico documenta la intervención en la plataforma. Esa retroalimentación refina el modelo y construye el historial técnico del activo, que se convierte en el activo de información más valioso del programa de mantenimiento.
La implementación está diseñada para ser rápida y no invasiva: los sensores se instalan sin interrumpir la producción y en días la plataforma comienza a generar insights accionables.
Conoce Smart Trac de Tractian y evalúa cómo los 4 componentes funcionan integrados en tu operación.
