

Em muitas plantas industriais, o volume de alarmes cresce ano após ano, mas a qualidade das decisões não acompanha esse aumento. Os alertas disparam, o backlog acumula e, no fim do dia, o time de manutenção ainda precisa decidir no achismo o que realmente merece atenção imediata.
Esse cenário cria dois riscos silenciosos. O primeiro é operacional: alarmes demais diluem o foco, atrasam intervenções críticas e normalizam o ruído. O segundo é cultural: quando muitos alertas não levam a ação, a confiança no sistema cai e até sinais importantes passam a ser ignorados.
Neste artigo, vamos mostrar como avaliar se os alarmes da sua planta estão ajudando ou atrapalhando a tomada de decisão, quais métricas usar nessa auditoria e como estruturar um método prático para melhorar a qualidade dos alertas em poucas semanas.
Leia também:
- Como funciona a Manutenção Baseada em Condição e como aplicar?
- 3 perguntas que destravam aprovação de parada por condição
- Quando NÃO intervir: 7 sinais de que o alarme é apenas ruído
O que é um alarme bom
Um bom alarme não é aquele que dispara cedo nem o que dispara com mais frequência. É aquele que sustenta uma decisão. Quando um alerta aparece, o time precisa conseguir responder três perguntas básicas: “isso é real?, “é urgente?” e “o que fazer agora?”.
Para isso, alarmes de qualidade têm quatro características fundamentais:
1) Acionável
O alerta deve trazer evidência mínima suficiente para validação e uma recomendação clara de próximo passo. Não basta sinalizar que algo saiu do normal, é preciso indicar o tipo de desvio, sua evolução e o que vale investigar em campo.
2) Estável
Um bom alarme respeita o regime de operação do ativo e evita disparos causados por variações normais de carga, processo ou velocidade. Quando o alerta dispara toda vez que o equipamento muda de contexto, ele perde credibilidade rapidamente.
3) Explicável
O porquê do alerta precisa ser rastreável. O time técnico deve conseguir entender quais sinais mudaram, em relação a qual referência e por que aquilo representa risco. Alarmes que não podem ser explicados tendem a ser ignorados ou excessivamente validados.
4) Priorizado por criticidade
A urgência do alerta precisa ser coerente com o risco do ativo e com o impacto potencial da falha. Um desvio em um ativo crítico não pode competir na fila com alertas de baixo impacto. Sem essa hierarquia, o backlog cresce e a tomada de decisão trava.
Quando esses quatro pontos estão presentes, o alarme deixa de ser uma desconfiança e passa a funcionar como deveria, como um gatilho confiável para ação no momento certo.
Métricas para auditar a qualidade de alarmes
Se um alarme gera ação, decisão ou aprendizado, está cumprindo seu papel. Se vira ruído, entra numa fila interminável ou exige retrabalho, algo está errado. Algumas métricas ajudam a transformar essa percepção em dado concreto.
Veja as mais importantes:
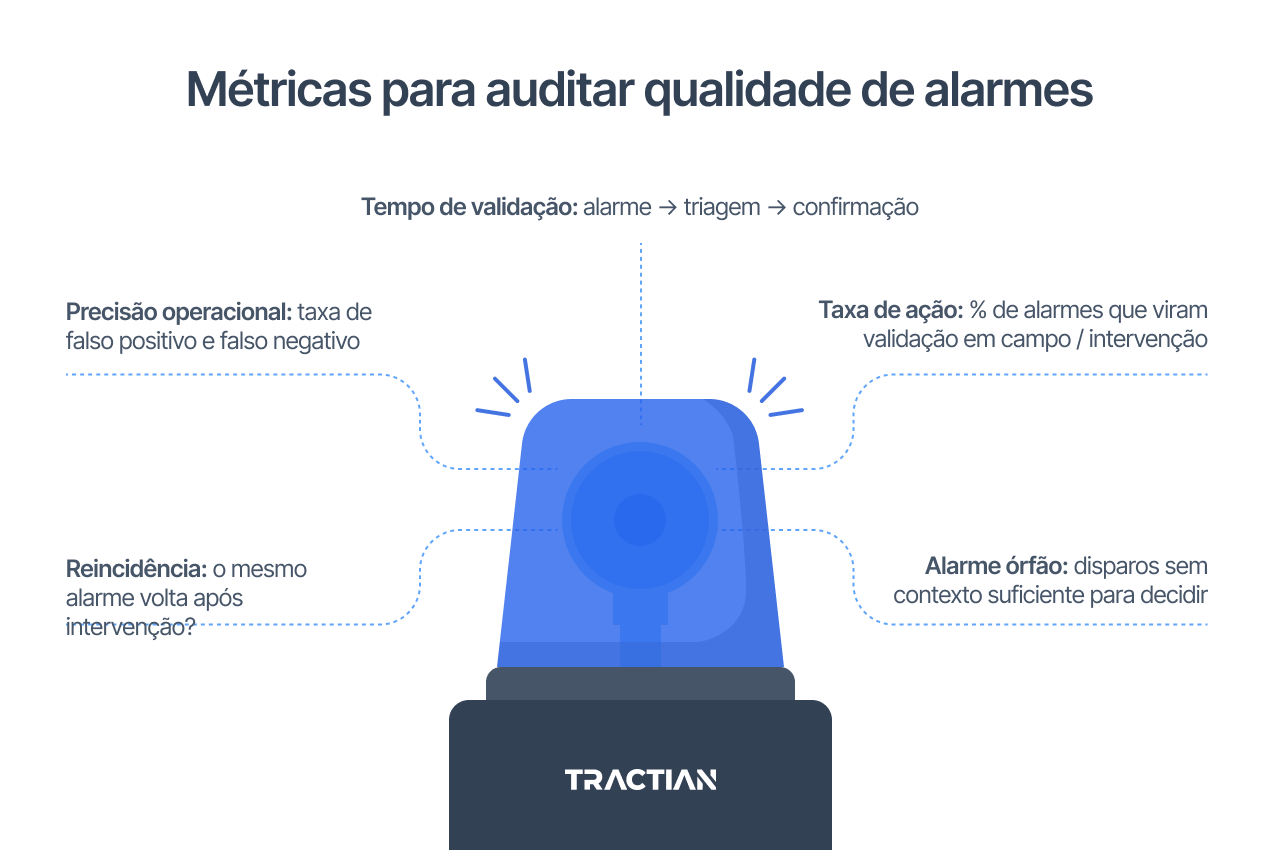
- Precisão operacional: Avalia a taxa de falso positivo e falso negativo. Alarmes que disparam sem falha real geram desgaste e perda de confiança. Já falhas que ocorrem sem alarme expõem a planta a riscos silenciosos. Esses dois extremos indicam baixa qualidade do alarme.
- Taxa de ação: Mostra quantos alarmes realmente viram validação em campo ou intervenção. Um volume alto de alertas com baixa taxa de ação é um sinal claro de excesso de alarme ou falta de contexto para decisão.
- Tempo de validação: Mede o intervalo entre o disparo do alarme, a triagem técnica e a confirmação do problema. Tempos longos indicam alertas pouco claros, difíceis de interpretar ou que exigem investigação excessiva antes de qualquer decisão.
- Reincidência: Avalia se o mesmo alarme volta após uma intervenção. Quando isso acontece com frequência, pode indicar correção superficial, diagnóstico errado ou critérios de alarme mal ajustados ao comportamento real do ativo.
- Alarme órfão: São alertas que disparam sem contexto suficiente para decidir: sem histórico, sem tendência clara ou sem referência do que mudou. Eles consomem tempo do time, mas não levam a nenhuma ação concreta.
Com essas métricas, fica evidente se os alarmes estão funcionando corretamente e, caso não estejam, é possível saber onde está o problema.
Método de auditoria em 30 dias
Auditar a qualidade dos alarmes não exige meses de análise nem projetos complexos. Com um recorte bem definido e um método simples, é possível identificar rapidamente onde está o ruído, o que está funcionando e quais ajustes trazem mais impacto.
A proposta aqui é um ciclo de 30 dias focado em evidência real: alarmes que dispararam, decisões que foram tomadas e ações que de fato aconteceram. Em vez de discutir regras em abstrato, o método reconstrói o caminho completo do alerta até a intervenção.
Ao longo dessas quatro semanas, o objetivo não é zerar alarmes, mas entender quais sustentam decisões confiáveis, quais precisam ser ajustados e quais não deveriam existir. O resultado é um sistema mais estável, priorizado e alinhado ao risco real da planta.
Semana 1: mapear e classificar alarmes por família e criticidade
O primeiro passo da auditoria é parar de olhar para alarmes como uma lista única e começar a enxergá-los como grupos com comportamentos diferentes. Sem esse mapeamento, qualquer ajuste vira tentativa e erro.
Nesta etapa, o foco é levantar todos os alarmes ativos e classificá-los por família de falha. Alarmes mecânicos, elétricos, de processo ou de instrumentação não se comportam da mesma forma e não deveriam competir entre si na priorização.
A criticidade do ativo entra como segundo eixo. Um mesmo tipo de desvio pode exigir respostas completamente diferentes dependendo do impacto do ativo na produção, na segurança ou na qualidade. Sem essa hierarquia clara, o sistema tende a gerar filas confusas e decisões atrasadas.
Ao final da semana, o objetivo é simples: ter visibilidade de onde está o volume de alertas, quais famílias concentram mais disparos e em quais ativos críticos o ruído é mais perigoso. Esse mapa é a base para todas as análises seguintes.
Semana 2: selecionar amostra de casos e reconstruir a linha do tempo
Com os alarmes mapeados, o próximo passo é sair do volume e entrar no detalhe. Em vez de analisar tudo, selecione uma amostra representativa de alertas: os mais frequentes, os mais críticos e aqueles que geraram dúvida ou retrabalho.
Para cada caso, reconstrua a linha do tempo completa: quando o alarme disparou, quem fez a triagem, quanto tempo levou para validar, qual decisão foi tomada e se houve ou não intervenção. Esse exercício revela rapidamente onde a decisão travou.
Muitas vezes, o problema não está no disparo em si, mas no que vem depois. Falta de contexto, alerta genérico ou ausência de critério claro de escalonamento fazem o alarme empacar na análise, mesmo quando o risco é real.
Ao final da semana, o time passa a enxergar padrões, como quais tipos de alerta geram ação, quais sempre exigem investigação extra e quais raramente levam a qualquer decisão. É aí que a qualidade começa a ficar evidente.
Semana 3: identificar padrões de ruído
Depois de reconstruir os casos, o ruído deixa de ser uma sensação e passa a ter padrão. Nesta semana, o foco é entender quando e por que os alarmes ruins disparam.
Grande parte dos falsos alertas está associada a mudanças de regime, variações de processo ou condições específicas de operação. Carga parcial, partidas frequentes, alteração de produto ou ajustes de processo costumam gerar desvios que não representam falha, mas acionam alarmes mal calibrados.
Outro ponto comum é um baseline inadequado. Referências criadas com poucos dados, em condição instável ou que não representam o comportamento real do ativo tendem a gerar alertas inconsistentes, especialmente quando o equipamento opera fora do cenário “ideal”.
Nesta etapa, o objetivo não é ajustar nada ainda, mas marcar padrões recorrentes: horários, regimes, tipos de ativo, pontos de medição ou condições operacionais que concentram ruído. Esse diagnóstico evita correções genéricas e prepara o terreno para ajustes mais precisos.
Semana 4: ajustar regras e definir critérios de escalonamento
Com os padrões de ruído mapeados, é hora de transformar o diagnóstico em regra. Nesta etapa, os ajustes passam a estruturar como os alarmes devem se comportar no dia a dia.
O primeiro foco é a persistência do desvio de comportamento. Eventos isolados, picos momentâneos ou desvios curtos não devem competir com falhas em evolução. Definir critérios mínimos de duração, repetição ou consistência reduz drasticamente alarmes que surgem e desaparecem sem impacto real.
Em seguida, entram os critérios de tendência. Alarmes mais maduros não reagem apenas a um valor fora do padrão, mas à direção e à velocidade da degradação. Isso ajuda o time a agir com antecedência, sem transformar todo desvio inicial em urgência.
Por fim, o contexto precisa fazer parte da lógica de escalonamento. Regime de operação, criticidade do ativo e histórico recente devem influenciar a urgência do alerta. Um mesmo sinal pode exigir observação em um cenário e intervenção imediata em outro.
Ao final da quarta semana, o sistema deixa de ser reativo e passa a ser previsível. Os alarmes não apenas disparam menos, mas passam a chegar no momento certo, com prioridade coerente e critérios claros para decisão.
As 6 causas mais comuns de alarmes ruins
A maioria dos alarmes ruins nasce de erros bem específicos de configuração, contexto ou processo.
Identificar essas causas é importante porque evita correções superficiais, como simplesmente elevar limites ou silenciar alertas. Esse tipo de ajuste até reduz o volume, mas costuma empurrar o risco para debaixo do tapete.
A seguir, vamos passar pelas causas mais recorrentes de alarmes ruins:
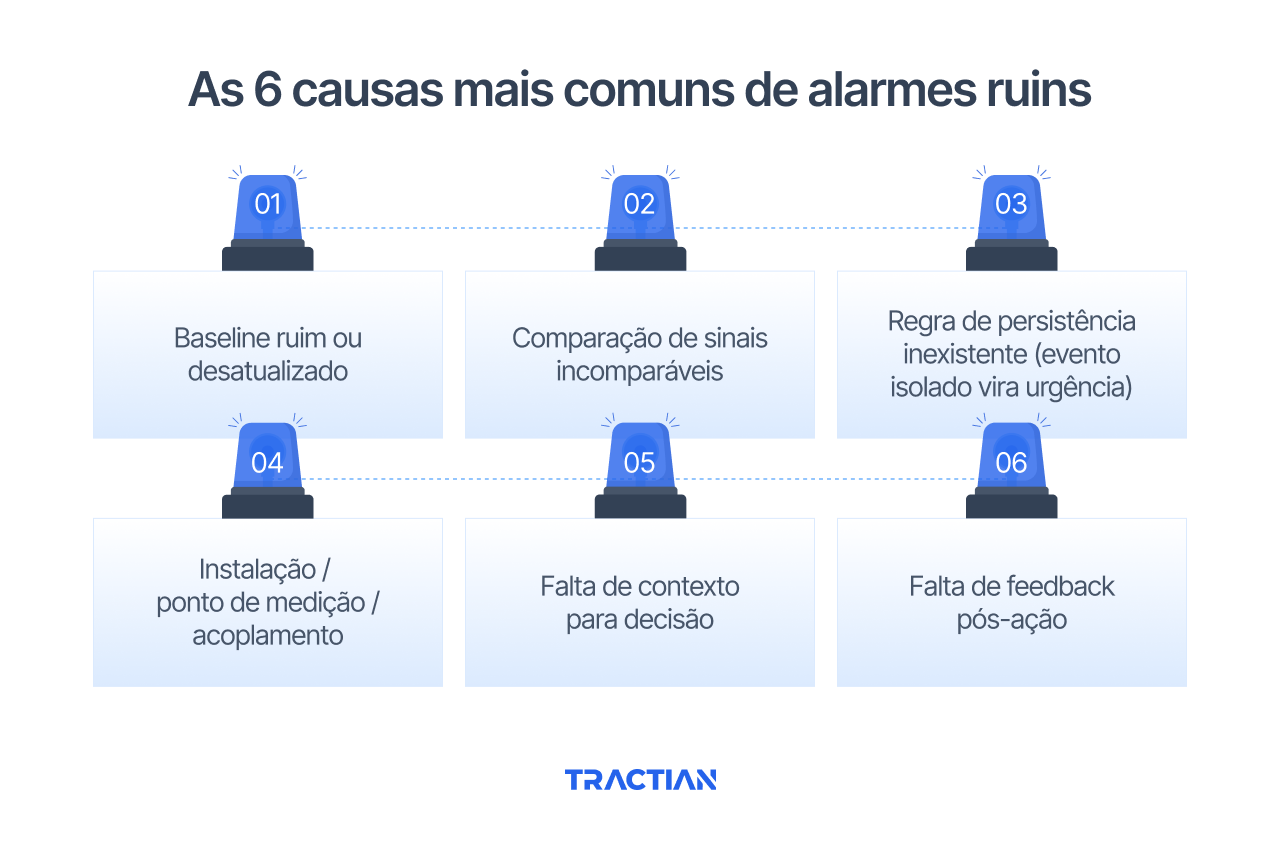
Baseline ruim ou desatualizado
Alarmes baseados em referências frágeis, criadas com pouco histórico ou em condições instáveis, tendem a disparar fora de contexto. Quando o baseline não representa o comportamento real do ativo, qualquer variação vira “anomalia”.
Comparação de sinais incomparáveis
Usar a mesma regra para ativos diferentes, pontos de medição distintos ou modos de operação incompatíveis gera alertas inconsistentes. Sinais que não compartilham o mesmo contexto não deveriam ser comparados da mesma forma.
Regra de persistência inexistente
Sem critérios mínimos de duração ou repetição, eventos isolados ganham status de urgência. Picos momentâneos, ruídos de processo ou variações transitórias acabam competindo com falhas reais em evolução.
Instalação, ponto de medição ou acoplamento inadequados
Sensores mal posicionados, fixações frágeis ou pontos de medição pouco representativos distorcem o sinal. O alarme dispara, mas o problema não está no ativo, está na forma como o dado foi coletado.
Falta de contexto para decisão
Alertas que não mostram histórico, tendência ou relação com o regime de operação exigem investigação extra antes de qualquer ação. Sem contexto, o alarme consome tempo, mas não sustenta a decisão.
Falta de feedback pós-ação
Quando o resultado da intervenção não retroalimenta o sistema, o alarme não evolui. O mesmo padrão volta a disparar, mesmo após correção, mantendo o ciclo de ruído e retrabalho.
Como a Tractian ajuda a reduzir ruído e priorizar o que importa na sua planta
Auditar alarmes deixa claro um ponto: o problema raramente é excesso de monitoramento. O que realmente atrapalha é a falta de critério, contexto e aprendizado contínuo com os erros do processo. Sem isso, os alertas competem entre si, a fila cresce e a decisão trava exatamente onde deveria ser mais rápida.
A solução de monitoramento da Tractian foi construída para atacar esse ponto na raiz. Em vez de depender de limites fixos e regras genéricas, a plataforma aprende o comportamento real de cada ativo, considera diferentes regimes de operação e ajusta automaticamente o momento certo do alerta. Isso reduz falsos positivos, mas sem esconder riscos importantes.
Além disso, os alertas já nascem priorizados por criticidade e acompanhados de contexto técnico suficiente para sustentar qualquer decisão. Tendência, histórico e recomendação caminham juntos, facilitando a triagem e evitando que o time perca tempo com alarmes que não exigem ação imediata.
O feedback de campo passa a retroalimentar o sistema, fazendo o monitoramento evoluir junto com a operação. As decisões ficam mais rápidas e o time pode dar foco total ao que realmente ameaça a confiabilidade da planta.
Se todo alarme parece urgente, nenhum é.
