

Nem toda falha começa com um ruído evidente ou um alarme disparando fora do padrão. Em muitos casos, o que realmente compromete a disponibilidade de um ativo é uma degradação lenta, silenciosa e cumulativa, que evolui ao longo de semanas ou meses sem chamar atenção.
Só que esse tipo de degradação raramente aparece em medições pontuais ou em limites fixos de alarme. Geralmente, ela se manifesta em pequenas mudanças de comportamento que só fazem sentido quando analisadas em conjunto e ao longo do tempo.
E é nesse cenário que a inteligência artificial chegou para mudar o jogo. Em vez de se deparar com falhas já consolidadas, a IA da Tractian foi desenvolvida para acompanhar o comportamento real dos ativos, aprender como cada máquina opera em condições normais e identificar sinais fracos de deterioração muito antes de uma falha funcional.
Ao longo deste artigo, vamos explorar o que caracteriza uma degradação lenta, por que os métodos tradicionais não conseguem capturá-la e como a IA da Tractian transforma sinais quase imperceptíveis em alertas úteis de verdade, permitindo intervenções planejadas no momento certo.
Leia também:
- Integração ERP x CMMS: 7 erros que quebram rastreabilidade
- Como usar o CMMS para auditorias internas de manutenção
- Por que a Curva PF pode falhar na prática e como corrigi-la
O que caracteriza uma degradação lenta em um ativo industrial
A degradação lenta acontece quando um ativo começa a perder desempenho de forma progressiva, sem apresentar sintomas claros de falha iminente.
Não há um ponto único de ruptura, mas um acúmulo de pequenas alterações no comportamento que isoladamente parecem irrelevantes, mas juntas indicam que algo está saindo do normal.
Esse tipo de degradação costuma estar associado a fenômenos como desgaste gradual de componentes, desalinhamentos leves, folgas crescentes, problemas de lubrificação ou variações no regime de carga. O equipamento continua operando, muitas vezes dentro dos limites aceitáveis de normas e tabelas, mas já não se comporta como antes.
O ponto crítico é que esses desvios raramente aparecem como picos ou alarmes evidentes. Eles surgem como mudanças sutis de tendência: um aumento lento e constante de vibração, um padrão espectral que se reorganiza aos poucos, ou uma resposta diferente da máquina a condições operacionais semelhantes.
Sem uma referência clara do comportamento normal daquele ativo, esses sinais passam despercebidos.
Por isso, identificar a degradação lenta exige uma compreensão profunda do contexto, do histórico e dos padrões de comportamento. O ideal é sempre comparar a máquina consigo mesma ao longo do tempo, e não apenas com limites genéricos.
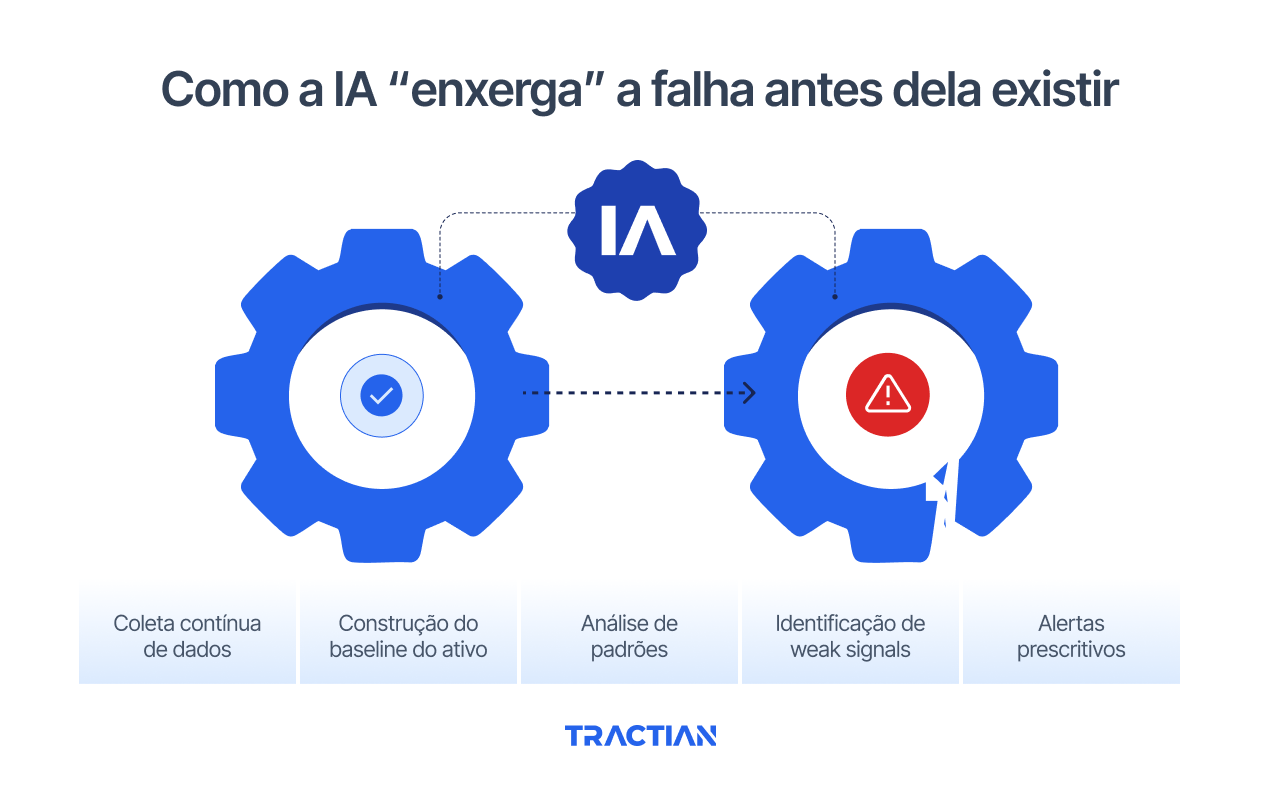
Como a IA “enxerga” a falha antes dela existir
Para identificar uma degradação lenta, a IA acompanha o comportamento do ativo de forma contínua e entende como ele evolui ao longo do tempo.
Tudo começa com a coleta contínua de dados. Sensores capturam informações de vibração e operação em alta frequência, criando um histórico muito mais denso do que qualquer rotina de inspeção periódica. Esse volume de dados é essencial para enxergar variações pequenas, que só se tornam relevantes quando analisadas em sequência.
Com esse histórico, a IA constrói o baseline do ativo. Esse baseline não é um valor fixo nem uma média genérica. Ele representa o comportamento normal daquela máquina específica, considerando seus modos de operação, carga, velocidade e variações naturais do processo. É a partir dessa referência que qualquer desvio passa a ter significado real.
A etapa seguinte é a análise de padrões. A IA observa como os sinais evoluem, identifica tendências, repetições e mudanças na dinâmica do ativo. Em vez de olhar apenas para amplitudes globais, ela analisa a forma como os sinais se organizam e se relacionam entre si ao longo do tempo.
É aqui que surgem os weak signals. Pequenas anomalias que ainda não configuram uma falha, mas indicam que o comportamento da máquina está se afastando do seu padrão saudável. Esses sinais seriam praticamente invisíveis em análises manuais ou inspeções pontuais, mas se destacam quando comparados ao histórico completo do ativo.
Quando esses desvios ganham consistência, a IA transforma essa detecção em alertas prescritivos. Em vez de apenas avisar que algo mudou, o sistema indica o nível de risco, a probabilidade de evolução do problema e orienta a melhor ação.
O objetivo não é gerar alarmes precoces demais, nem tardios, mas apoiar decisões no momento certo, antes que a degradação lenta se transforme em uma falha funcional.
Por que os métodos tradicionais não capturam degradação lenta
A maior limitação dos métodos tradicionais é que eles foram pensados para identificar falhas evidentes, não mudanças graduais de comportamento. Quando o problema evolui devagar, esses modelos simplesmente não têm resolução suficiente para perceber o que está acontecendo.
Veja alguns dos fatores que impedem a manutenção tradicional de identificar essas degradações:
Inspeções offline não coletam dados suficientes
Coletas periódicas geram fotografias isoladas do ativo. Mesmo quando bem executadas, elas deixam grandes lacunas temporais entre uma medição e outra.
Nesse intervalo, a máquina pode operar em diferentes condições, sofrer variações e iniciar um processo de degradação que nunca será registrado. O resultado é uma análise baseada em poucos pontos, incapaz de capturar tendências sutis e contínuas.
Medições globais escondem microanomalias
Indicadores agregados, como valores globais de vibração, funcionam bem para detectar falhas já avançadas.
O problema é que degradações lentas não se manifestam como saltos bruscos nesses valores. Elas aparecem como pequenas mudanças na distribuição do sinal, na resposta do ativo ou na repetição de determinados padrões, que acabam diluídas em métricas simplificadas.
Falta de correlação com o contexto operacional
Sem considerar carga, regime de operação ou variações do processo, qualquer análise fica limitada. Um mesmo nível de vibração pode ser normal em um contexto e preocupante em outro.
Métodos tradicionais raramente fazem essa correlação de forma automática, o que gera tanto alarmes tardios quanto falsos positivos que minam a confiança da equipe.
Análise humana não escala para milhares de dados por dia
Mesmo equipes experientes têm limites. Analisar manualmente grandes volumes de dados contínuos, correlacionar históricos longos e identificar padrões sutis em centenas ou milhares de ativos não é viável na prática.
Sem automação e aprendizado contínuo, a degradação lenta passa despercebida até se tornar uma falha evidente.
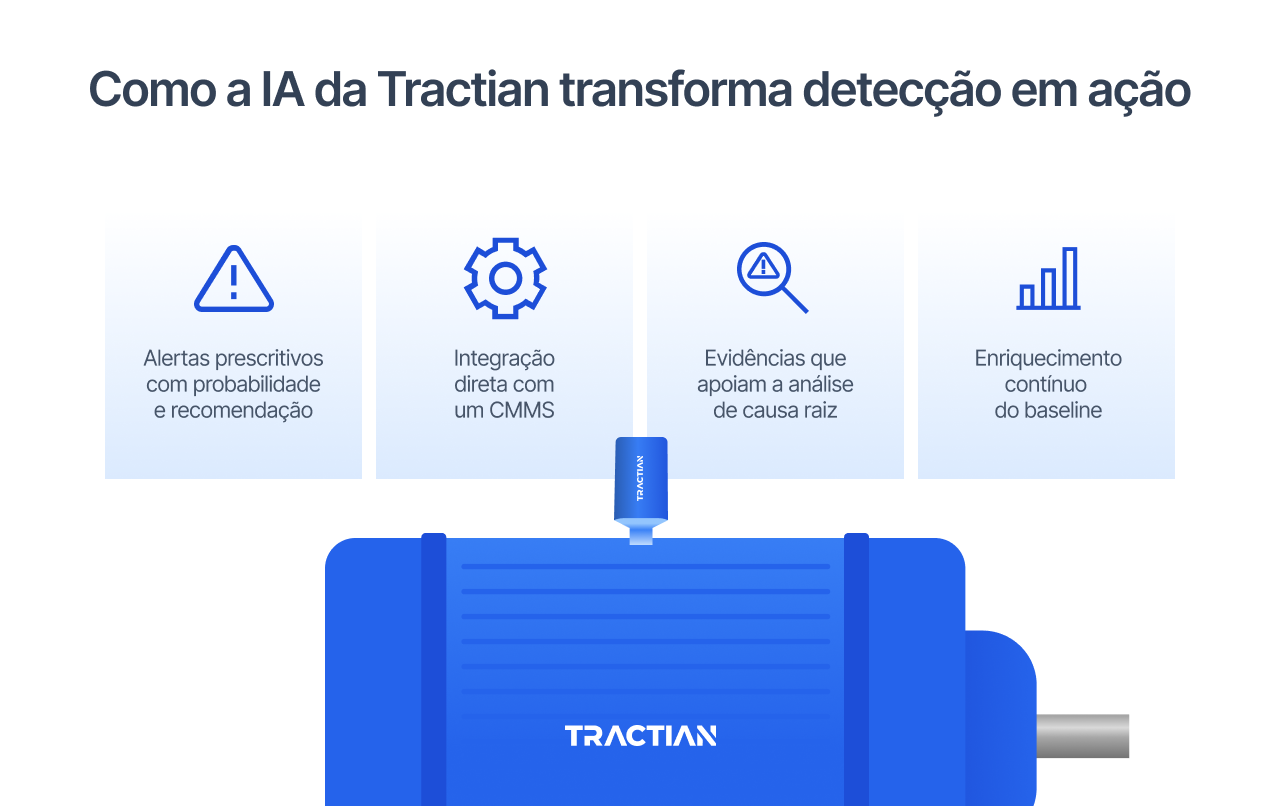
Como a IA da Tractian transforma detecção em ação
Monitorar ativos é importante, mas mais importante ainda é usar os dados coletados para orientar ações. Diferente de outros métodos de coleta de dados de ativos, a IA da Tractian avança além da identificação de anomalias e passa a atuar como suporte ativo à tomada de decisão.
Alertas prescritivos com probabilidade e recomendação
Os alertas prescritivos são o primeiro passo dessa transformação. Em vez de sinalizar apenas que algo saiu do padrão, a IA indica a probabilidade de evolução da degradação, o impacto potencial no ativo e sugere a melhor ação.
Isso permite que o time diferencie o que pode ser monitorado do que já exige planejamento, evitando tanto a reação tardia quanto intervenções desnecessárias.
Integração direta com um CMMS
Esses alertas não ficam isolados. A integração direta com o CMMS conecta as informações coletadas à equipe, que pode partir para a execução com base nesses dados. Quando um risco relevante é identificado, a informação já chega estruturada para o planejamento de manutenção.
Isso facilita a criação de ordens de serviço, a priorização correta dos ativos e o alinhamento entre preditiva, planejamento e campo. A manutenção deixa de ser reativa e passa a trabalhar com antecedência real.
Evidências para análise de causa raiz
Outro ponto-chave são as evidências que apoiam a análise de causa raiz. Cada alerta vem acompanhado de dados históricos, tendências e comparações com o comportamento normal do ativo.
Isso reduz a dependência de interpretações subjetivas e acelera o entendimento do problema, permitindo que a equipe ataque a causa e não apenas o sintoma.
Enriquecimento contínuo do baseline
Com a IA da Tractian, o baseline nunca fica estático ou desatualizado. Sempre que uma intervenção acontece, seja confirmando ou descartando uma anomalia, a IA aprende com esse resultado.
O modelo se ajusta, refina seus critérios e passa a reconhecer com ainda mais precisão o que é normal e o que representa um risco real para aquele ativo específico. Com o tempo, os alertas se tornam mais assertivos e alinhados à realidade operacional da planta.
Casos reais que mostram o impacto da IA na prevenção de falhas
A diferença entre detectar uma degradação lenta e evitar uma falha está no tempo e na qualidade da decisão. As empresas que usam a tecnologia da Tractian para detecção de falhas mostram com clareza como a IA transforma sinais quase invisíveis em resultados operacionais concretos.
Uma delas é a Vetorial Siderurgia, que opera em um ambiente extremo, com altas temperaturas, poeira e ativos críticos como altos-fornos e grandes motores.
Mesmo com rotinas de manutenção e coletas de vibração já estabelecidas, a planta ainda sofria com falhas inesperadas. O problema não era falta de dados, mas a dificuldade de identificar, com antecedência, pequenas perdas de desempenho que evoluíam lentamente até a quebra.
Com o monitoramento online e o autodiagnóstico por IA, a Vetorial passou a acompanhar continuamente o comportamento real dos ativos. A IA identificou mais de 250 falhas em estágio inicial, muitas delas associadas a problemas de lubrificação e desgaste progressivo que dificilmente seriam percebidos em inspeções periódicas.
O resultado foi direto: mais de 1.200 horas de manutenções corretivas evitadas, 600% de aumento do ROI médio e 375 toneladas de ganho efetivo de produção. É o efeito de tratar a degradação lenta não mais como um risco invisível, mas como um evento planejável e contornável.
Já na Dexco, o impacto da IA aparece em escala. Com mais de 1.000 ativos monitorados em 22 plantas industriais, a empresa saiu de um modelo baseado em coletas mensais para um monitoramento contínuo, com medições a cada 10 minutos. A empresa saiu de 36 coletas por ano para mais de 144 coletas por dia por ativo.
Essa mudança permitiu à IA construir baselines extremamente precisos e identificar degradações lentas muito antes de qualquer falha funcional. A resposta nos resultados foi de um aumento médio de 35% na produtividade, redução de 25% em perdas por lucro cessante e um ROI médio de 700%.
Em média, cada falha evitada na Dexco economizou cerca de R$ 500 mil, graças a intervenções planejadas no momento certo.
Com alertas prescritivos claros indicando quando, onde e como agir, a manutenção passou a operar com previsibilidade, reduzindo paradas não planejadas e transformando sinais fracos de degradação em decisões objetivas no chão de fábrica.
Veja mais estudos de caso aqui e entenda o impacto da Tractian em operações industriais.
Comece a usar hoje mesmo a IA da Tractian
Problemas de degradação lenta não vêm da falta de manutenção. O problema é falta de visibilidade. Quando os sinais aparecem de forma sutil e progressiva, métodos tradicionais simplesmente não conseguem separar o que é variação normal do que já indica perda real de desempenho. E a história se repete: a falha só fica clara quando já é tarde demais.
O monitoramento contínuo da Tractian muda esse cenário porque acompanha o ativo o tempo todo, em diferentes regimes de operação, e constrói um histórico denso do seu comportamento real.
Em vez de depender de medições pontuais, a IA analisa dados coletados continuamente, aprende como cada máquina opera quando está saudável e identifica qualquer desvio relevante a partir dessa referência. Com análise automática de padrões e alertas prescritivos, esses desvios são transformados em decisões claras para o time de manutenção.
A plataforma indica quando o risco começa a ganhar consistência, qual a probabilidade de evolução do problema e qual é o melhor momento para intervir. Assim, a degradação deixa de ser invisível e passa a ser um evento gerenciável, integrado à rotina operacional e ao planejamento.
Se hoje sua equipe ainda descobre o problema quando a máquina já está perto de parar, o risco não está no ativo, mas no modelo de monitoramento.
