

Em plantas sucroenergéticas, a safra não perdoa erros de planejamento. Cada hora parada fora do cronograma representa cana que fica no campo, açúcar que deixa de cristalizar e etanol que não entra no tanque.
O turno de moagem opera em regime contínuo por meses, e qualquer falha em um ativo crítico pode comprometer não só o equipamento em si, mas toda a cadeia, da extração à cogeração.
Por isso, a análise preditiva é uma camada operacional indispensável nesse setor. Monitorar a condição dos ativos em tempo real permite antecipar degradação, planejar intervenções durante janelas curtas e, mais importante, manter a disponibilidade da planta no patamar que o negócio exige.
Mas existe uma série de decisões práticas que o gestor de manutenção precisa tomar antes e durante a safra para de fato evitar paradas com a análise preditiva. A seguir, reunimos as cinco mais relevantes, a partir da nossa experiência com plantas sucroenergéticas maduras.
Leia também:
- Top 3 sensores de vibração para moinhos de cana
- Como o monitoramento de condição muda a rotina de times pequenos
- Manutenção Preditiva: Como Implementar em 2026 (Guia Prático + ROI)
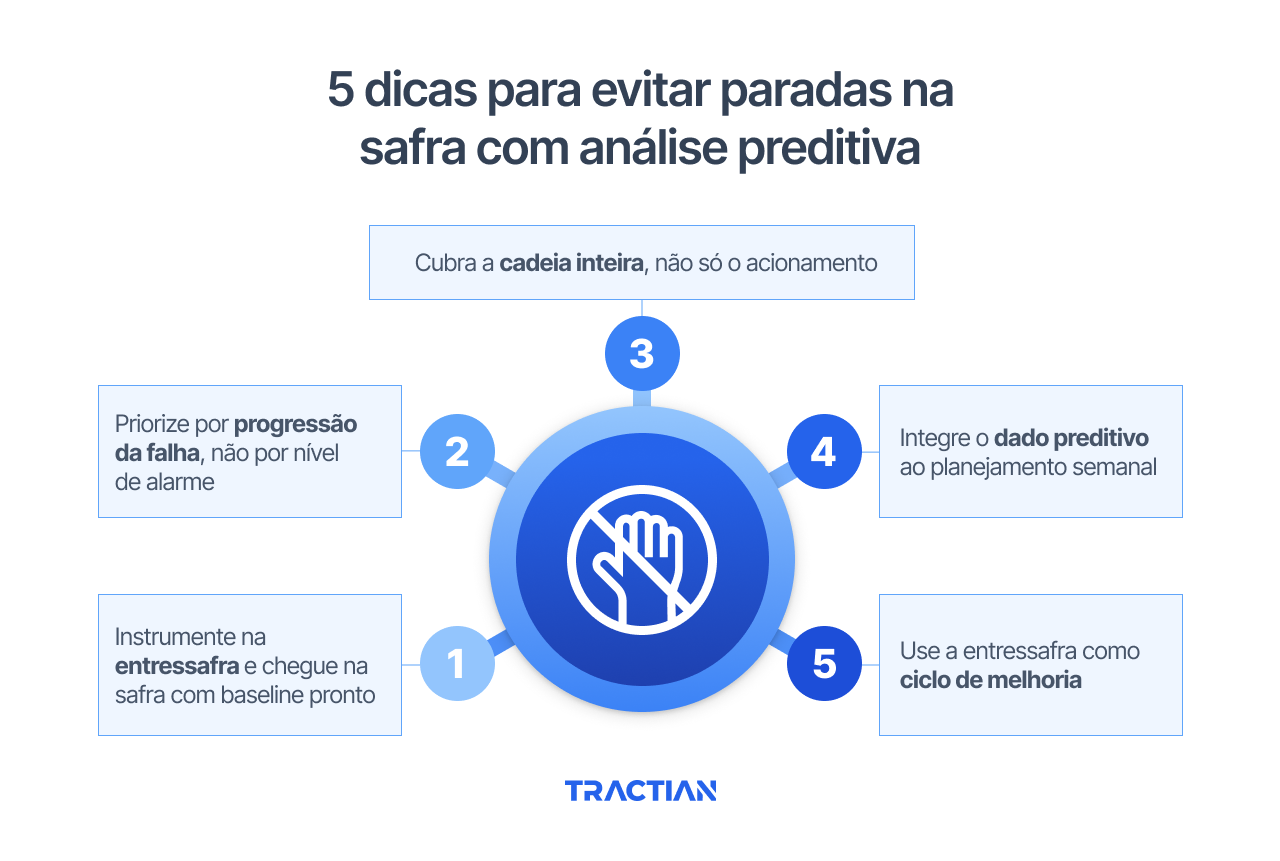
1. Instrumente na entressafra e chegue na safra com baseline pronto
Quando um sensor é instalado com a planta já em operação contínua, ele começa a coletar informação sem nenhuma referência de como o ativo se comporta quando está saudável. Qualquer alerta gerado nas primeiras semanas é questionável, porque o sistema ainda não sabe diferenciar um pico de vibração que representa um evento real de deterioração de um padrão normal de operação.
O time começa a receber notificações que não se sustentam na prática, a confiança no sistema cai e, em poucas semanas, os alertas viram ruído de fundo. Esse é o ponto em que a preditiva deixa de funcionar mesmo com tudo aparentemente instalado e conectado.
Por isso, a safra não é o momento de instalar sensor.
A entressafra é a janela técnica para evitar esse desgaste. É o momento certo para instalar, parear, validar comunicação e, principalmente, construir baseline em condição controlada.
Com a planta rodando em regime estável de comissionamento ou testes operacionais, o sensor observa o ativo ao longo de todo o envelope de operação: arranques, transições de carga, regime de cruzeiro e desligamentos. Esse histórico é o que vai permitir, na safra, identificar com confiança qualquer desvio que realmente importa.
2. Priorize por progressão da falha, não por nível de alarme
A fadiga de alerta é um modo de falha do time de manutenção, não do ativo. E é talvez o mais silencioso de todos, porque o sistema continua gerando alertas, o time continua recebendo, mas ninguém mais age, porque associou que a maioria não se justifica.
Isso acontece quando o critério de priorização se apoia apenas em nível de alarme. Em uma planta com centenas de sensores espalhados entre moenda, bombeamento, caldeira e destilaria, essa abordagem gera um volume impossível de triagem e transforma a preditiva em uma caixa de entrada transbordando.
O critério que efetivamente separa urgência de ruído é a velocidade de degradação. Um ativo com vibração alta, porém estável há semanas, quase sempre é menos urgente que um ativo com vibração moderada acelerando. Isso porque o primeiro caso descreve uma condição conhecida e tolerável. Já o segundo descreve uma falha em evolução, que vai cruzar qualquer threshold em questão de dias.
Priorizar por progressão significa olhar para a tendência, não para o valor absoluto. Significa também reconhecer que nem todo ativo que dispara alarme precisa de intervenção imediata e que nem todo ativo silencioso está saudável.
Essa leitura muda completamente a rotina da equipe na safra. Em vez de apagar incêndio, o analista atua onde a curva está se inclinando e protege o ativo antes da amplitude virar problema. O monitoramento de condição com detecção de falhas por IA é um grande aliado para estabelecer esse critério.
3. Cubra a cadeia inteira, não só o acionamento
O motor e o redutor da moenda estão no topo de qualquer matriz de criticidade em planta sucroenergética. Mas a lista de ativos capazes de tirar a moagem do ar é bem maior do que isso.
Bombas de caldo, picadores, desfibradores, exaustores de caldeira, turbogeradores, ventiladores de tiragem, redutores de picador. Todos esses equipamentos falham com frequência comparável à da linha de acionamento principal, e muitos deles operam em condições ainda mais agressivas, com bagaço, caldo, vibração estrutural e variação térmica constantes.
A diferença é que, historicamente, eles recebem menos atenção do programa de confiabilidade.
Monitorar apenas o crítico A e ignorar o restante da cadeia cria pontos cegos. E o ponto cego é exatamente onde a falha inesperada acontece, porque ninguém está olhando.
Uma bomba de caldo que trava em plena moagem pode parar uma linha inteira até a reserva ser acionada. Um exaustor de caldeira que perde rolamento derruba a geração de vapor e impacta toda a cogeração.
O caminho é escalar o monitoramento sem perder governança. Isso não significa colocar sensores em todo ativo da planta, mas sim expandir a cobertura de forma estruturada, aplicando os mesmos critérios de priorização e análise que já funcionam para os ativos classe A em ativos B e C.
4. Integre o dado preditivo ao planejamento semanal
Ter dados preditivos coletados, mas não transformá-los em ação não vale de nada. O dashboard fica bonito, o relatório fica completo, mas nada disso tem valor operacional se ficar isolado em uma tela que ninguém consulta na reunião de programação da semana.
Essa é uma falha comum em plantas que estão começando a estruturar a preditiva. O sistema funciona tecnicamente, o time de confiabilidade entende os diagnósticos, mas o output do monitoramento corre em paralelo ao planejamento de manutenção em vez de alimentar diretamente as decisões de parada e intervenção.
Para que a preditiva tenha impacto real na safra, o dado precisa entrar como input do planejamento semanal, no mesmo nível em que entram os planos preventivos programados e as demandas corretivas em aberto. A reunião de programação deve começar olhando para o que o monitoramento está mostrando sobre ativos em progressão de falha, e essas informações precisam virar OS priorizadas dentro da janela disponível.
Para isso funcionar, também é necessário traduzir severidade técnica em impacto operacional. Um defeito de rolamento em estágio intermediário é uma informação relevante para o analista, mas o supervisor de produção precisa saber o que isso significa em horas de autonomia restante, risco para a linha e custo de uma intervenção programada versus emergencial.
Quando o time consegue fazer essa tradução de forma consistente, o dado preditivo deixa de ser consulta paralela e passa a pautar a operação.
5. Use a entressafra como ciclo de melhoria
Toda safra gera um histórico valioso de alertas, intervenções, falhas reais e eventos falsos. A planta que aproveita a entressafra para revisar esse histórico de forma estruturada tem tempo de aprender e corrigir o que não saiu como o esperado. Já a planta que passa direto para a próxima instalação repete os mesmos pontos cegos safra após safra.
A revisão precisa contemplar três perguntas principais:
- Quais alertas anteciparam falhas reais e confirmadas em campo?
- Quais alertas foram ruído que não se sustentou na investigação?
- Quais falhas aconteceram sem alerta prévio, pegando o time de surpresa?
Cada uma dessas respostas abre uma ação concreta para a entressafra.
Alertas que funcionaram confirmam que a calibração está correta e podem inspirar a expansão para ativos similares.
Alertas que geraram ruído indicam thresholds mal ajustados, posicionamento de sensor inadequado ou lógica de progressão que precisa ser refinada.
E falhas que passaram sem alerta apontam lacunas de cobertura ou de sensibilidade que precisam ser endereçadas antes da próxima moagem.
Também é o momento de recalibrar baselines com o histórico acumulado, reposicionar sensores em ativos que passaram por reforma e revisar a matriz de criticidade com base no que a safra revelou. Esse ciclo de melhoria contínua é o que diferencia uma operação preditiva madura de uma que funciona só no papel.
Como a Tractian facilita o seu trabalho durante a safra com análise preditiva
A solução de monitoramento de condição da Tractian foi desenhada considerando exatamente o tipo de realidade operacional que uma planta sucroenergética enfrenta na safra: ativos rodando em regime contínuo, cadeias longas com muitos equipamentos críticos, equipes enxutas e janelas de intervenção que precisam ser cirúrgicas.
A segunda geração dos sensores combina vibração e ultrassom em um único dispositivo, o que permite identificar falhas de lubrificação e atrito muito antes que o sintoma chegue ao espectro de vibração. Com magnetômetro integrado, o sensor mede RPM real em tempo contínuo, algo especialmente relevante em ativos com inversor de frequência, comuns em bombas, exaustores e compressores da planta.
E a coleta lossless com resolução até seis vezes maior que a geração anterior dá ao analista confiança de diagnóstico compatível com a de um coletor manual, mas com a cobertura e a continuidade que só o monitoramento online oferece.
Se a sua planta está se preparando para a próxima safra e busca uma abordagem de monitoramento que entregue confiança de diagnóstico, cobertura em escala e integração real com o fluxo de trabalho do time, a Tractian pode ser sua maior aliada.
