

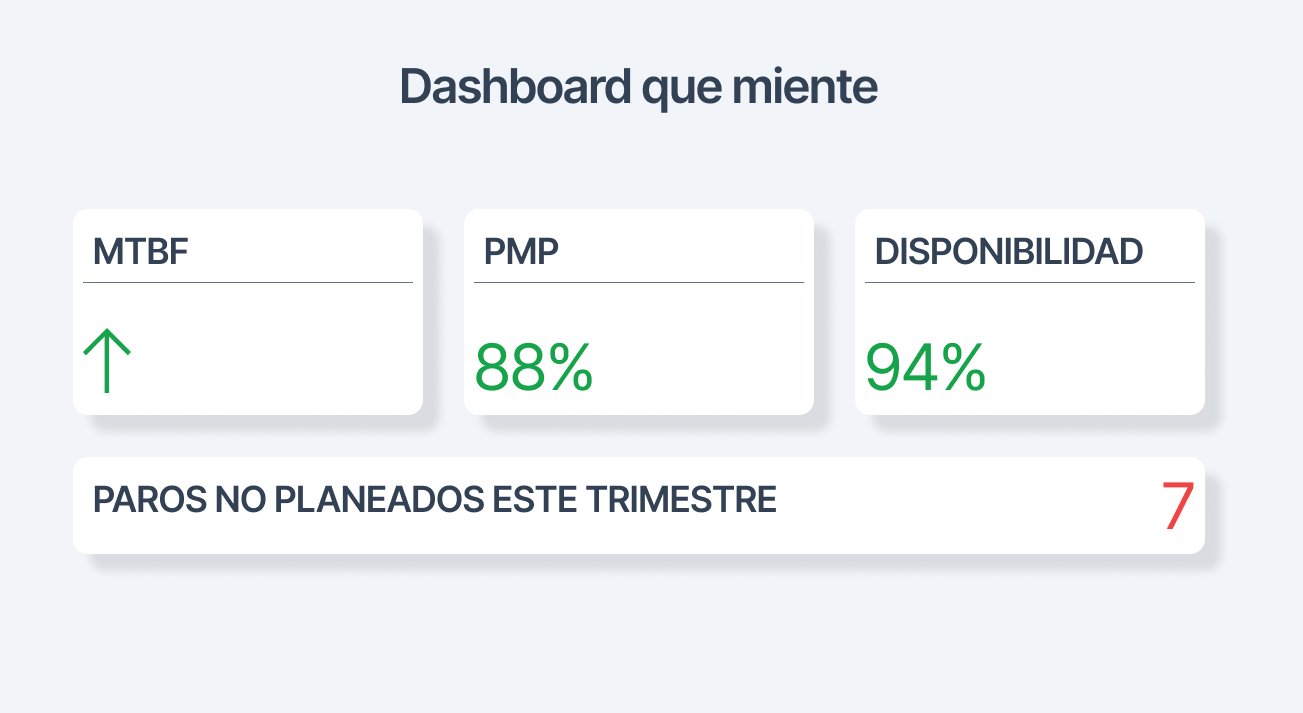
Tu MTBF subió un 20% este trimestre. Puede ser que la confiabilidad mejoró. Puede ser que dejaste de registrar los correctivos menores. El indicador no dice cuál de las dos es: eso lo decides tú.
Un KPI de mantenimiento bien configurado no es un número para presentar en junta: es una señal que indica si el programa está funcionando o si algo necesita corrección. Este artículo cubre los KPIs que realmente mueven el marcador en planta industrial, cómo calcularlos correctamente y, sobre todo, cómo detectar cuándo un indicador bien calculado puede conducirte a la decisión equivocada.
La diferencia entre un programa que mide y uno que gestiona está en cómo se interpretan los números. El dashboard verde no siempre significa que la planta está bien. A veces significa que el programa de medición está midiendo las cosas equivocadas o con los datos equivocados.
Por qué los KPI de mantenimiento importan más allá del reporte mensual
Los KPIs de mantenimiento existen para responder una pregunta operativa: ¿el programa está mejorando la confiabilidad de los activos o simplemente generando actividad? Es posible tener un equipo ocupado al 100%, con todas las OTs cerradas a tiempo, y aun así tener activos que fallan con mayor frecuencia que el trimestre anterior.
La gestión del mantenimiento efectiva requiere indicadores que reflejen la realidad operativa. Un dashboard con diez indicadores en verde puede esconder problemas reales si los indicadores no están configurados para capturar lo que importa.
La medición sin interpretación no genera valor. Este artículo está escrito para el ingeniero de mantenimiento y el ingeniero de confiabilidad que ya miden KPIs y necesitan asegurarse de que lo que miden refleja la realidad operativa, no una versión optimista de ella.
Los KPI de mantenimiento que realmente importan en planta
No existe un número mágico de KPIs. Menos de cinco y se pierden dimensiones críticas. Más de diez y nadie los sigue con disciplina. El rango práctico es entre seis y diez, dependiendo de la madurez del programa y de la capacidad real del equipo para actuar sobre lo que los indicadores muestran.
MTBF (Tiempo Medio Entre Fallas)
Fórmula: MTBF = Tiempo total de operación / Número de fallas en el período. Es el indicador más directo de confiabilidad del activo. Para entender el MTBF y su relación con el MTTR, ambos deben analizarse juntos: uno mide cuánto dura el activo antes de fallar; el otro, cuánto tarda el equipo en restituirlo.
Cómo puede engañarte: si solo se registran paros completos y se omiten correctivos menores, el MTBF aparece alto aunque la condición real del activo esté deteriorándose. El indicador mejora porque los datos de entrada empeoran, no porque el activo mejore.
También puede engañarte si el período medido tuvo condiciones atípicas. La planta operó al 60% de capacidad. Con menos carga, los activos fallan menos. El MTBF sube sin que el programa haya cambiado nada. Solución: normalizar el MTBF por horas de operación efectiva, no por días de calendario.
MTTR (Tiempo Medio de Reparación)
Fórmula: MTTR = Tiempo total de reparación / Número de reparaciones. Mide la velocidad de respuesta del equipo. Un MTTR bajo indica capacidad de resolver rápido, pero rápido no siempre significa bien.
Cómo puede engañarte: un MTTR bajo logrado con reparaciones temporales genera reincidencia. La falla vuelve, el MTTR baja, pero el activo acumula más intervenciones que uno reparado correctamente la primera vez. El análisis del MTTR en tendencia revela si el tiempo de reparación está cayendo por mejora real o por trabajo incompleto.
El MTTR también esconde la diferencia entre tiempo de diagnóstico y tiempo de ejecución. Si el técnico tarda dos horas en identificar el problema y una en resolverlo, el MTTR de tres horas no indica que la reparación sea lenta: indica que el diagnóstico no tiene suficiente contexto previo del activo.
Disponibilidad del activo
Fórmula: Disponibilidad = (Tiempo disponible / Tiempo total) × 100. Es el indicador que producción entiende mejor porque traduce directamente a capacidad productiva.
Cómo puede engañarte: un activo puede estar disponible pero operando con rendimiento reducido. Una línea con disponibilidad del 95% puede tener un OEE del 68% si el rendimiento y la calidad son bajos. La disponibilidad no captura la eficiencia, solo la presencia o ausencia de paro.
Esa diferencia entre disponibilidad y OEE es la fuente más frecuente de confusión entre mantenimiento y producción. Mantenimiento reporta disponibilidad alta; producción reporta eficiencia baja. Ambos tienen razón con sus datos. La discrepancia está en lo que cada indicador captura.
Porcentaje de mantenimiento planificado (PMP)
Fórmula: PMP = (Horas planificadas / Horas totales de mantenimiento) × 100. Referencia: objetivo superior al 80-85% en plantas maduras.
Cómo puede engañarte: un PMP alto puede significar muchas OTs preventivas innecesarias. Si el 40% de las OTs planificadas están en activos que rara vez fallan y cuya intervención no genera valor, el PMP es alto pero el programa está desperdiciando recursos. Alto PMP no equivale a programa eficiente.
La solución: revisar periódicamente si cada OT preventiva está justificada por historial de fallas o por criticidad del activo. Las OTs que llevan 12 meses cerrándose con 'sin novedad' son candidatas a revisión de frecuencia o eliminación.
Backlog de mantenimiento
Mide el trabajo identificado pero no ejecutado. El backlog cero no es el objetivo: puede indicar que no se están identificando fallas. El backlog útil está priorizado, con fechas comprometidas y separado por criticidad.
Un backlog que crece sin control indica que el equipo no tiene capacidad para ejecutar todo lo que identifica. Un backlog estable y priorizado indica un equipo que gestiona su carga con criterio. La diferencia es cualitativa, no cuantitativa.
Costo de mantenimiento como porcentaje del valor del activo (CMF)
Fórmula: CMF = (Costo total de mantenimiento / Valor de reemplazo del activo) × 100. Un CMF superior al 5-8% anual puede indicar que el activo está llegando al fin de su vida útil económica y que reemplazarlo es más rentable que seguir manteniéndolo.
Este indicador es especialmente útil para justificar decisiones de reemplazo con la dirección financiera. Un activo que consume el 12% de su valor de reemplazo en mantenimiento cada año tiene un argumento financiero claro para su sustitución.
KPIs de diagnóstico operativo vs. KPIs de reporte a dirección
No todos los KPIs tienen el mismo público ni la misma frecuencia. Mezclarlos en el mismo dashboard genera frustración en ambos sentidos: el equipo operativo recibe indicadores que no le dicen qué hacer hoy, y la dirección recibe datos que no puede interpretar sin contexto.
KPIs de diagnóstico operativo (diario y semanal)
MTTR por activo crítico. El supervisor necesita saber hoy cuánto está tardando su equipo en resolver cada intervención. Si el MTTR de un activo específico sube esta semana, necesita identificar por qué.
Backlog por criticidad y por técnico. ¿Cuántas OTs de activos críticos están pendientes? ¿Cuál técnico tiene la mayor carga? Ese dato define la asignación de recursos del día.
OTs cerradas vs. abiertas en la semana. El ritmo de cierre de OTs indica si el equipo está avanzando o acumulando trabajo.
Alertas de condición atendidas vs. pendientes. Si el programa incluye monitoreo de condición, las alertas no atendidas son trabajo pendiente con fecha de vencimiento implícita.
KPIs de reporte a dirección (mensual y trimestral)
Disponibilidad por línea de producción. La dirección necesita ver el impacto del mantenimiento en la capacidad productiva, no el detalle de cada intervención.
MTBF en tendencia vs. trimestre anterior. La tendencia importa más que el valor absoluto. Un MTBF de 200 horas que crece cada trimestre es mejor que uno de 400 que decrece.
PMP y CMF. Juntos muestran si el programa es eficiente y si los activos justifican seguir siendo mantenidos o deben reemplazarse.
Cuándo un KPI bien calculado igualmente te engaña
Esta es la sección que diferencia este análisis de las listas de fórmulas que circulan en la mayoría de recursos. Un KPI puede estar correctamente calculado y aun así conducir a la decisión equivocada. Hay tres escenarios que ocurren con frecuencia en planta.
El MTBF sube pero la confiabilidad no mejora
Escenario: el período no tuvo las condiciones de producción habituales. La planta operó al 60% de capacidad. Con menos carga, los activos fallan menos. El MTBF subió sin que el programa mejorara.
Solución: normalizar el MTBF por horas de operación efectiva, no por días de calendario. Un MTBF calculado sobre horas reales elimina el efecto de la variación de carga y permite comparar trimestres con condiciones de producción distintas.
El PMP es alto pero el programa está sobredimensionado
Escenario: el 40% de las OTs preventivas están en activos que rara vez fallan y cuya intervención no genera valor. El programa es extenso pero no eficiente. Alto PMP no equivale a programa bien diseñado.
Solución: revisar periódicamente si cada OT preventiva está justificada por historial de fallas o por criticidad del activo.
La disponibilidad es alta pero el OEE es bajo
Escenario: disponibilidad 95%, OEE 68%. La diferencia está en rendimiento y calidad: el activo está disponible pero opera con microparos, velocidad reducida y defectos. Solución: complementar disponibilidad con seguimiento de OEE que capture las tres dimensiones de la eficiencia productiva.
Este escenario es el más frecuente en plantas donde mantenimiento y producción operan con indicadores desconectados. Cuando ambos equipos ven los mismos datos, la conversación cambia de '¿quién tiene la culpa?' a '¿dónde está el problema?'
Cómo implementar un sistema de KPIs que realmente funcione
Empieza con menos KPIs, no con más
Un programa nuevo que mide 15 KPIs desde el día uno no tiene datos confiables para ninguno. Empieza con tres: MTTR, disponibilidad y backlog. Cuando esos tres tienen datos limpios durante 90 días, agrega el siguiente. La tentación de medir todo desde el inicio es contraproducente: sin datos limpios, los indicadores son ruidosos y las conclusiones poco confiables.
Define el numerador y el denominador antes de calcular
El MTBF de un activo que operó 1,000 horas con dos paros es diferente al del mismo activo que operó 300 horas con dos paros. Definir qué entra en el tiempo total de operación es tan importante como la fórmula.
¿Se incluyen los arranques y paros programados? ¿Se cuentan los correctivos menores como fallas o solo los paros completos? Esas definiciones deben ser explícitas y consistentes para que el indicador sea comparable entre períodos.
Vincula los KPIs a decisiones, no a reportes
Si el MTTR supera un umbral, tiene que existir una acción predefinida. Un KPI que no tiene una acción asociada es un número en un dashboard. La diferencia entre medir y gestionar está exactamente ahí.
Ejemplo práctico: si el backlog de activos críticos supera las 40 horas-hombre, se activa automáticamente la redistribución de recursos del equipo. Esa regla convierte al backlog de un número en un mecanismo de gestión.
El papel del monitoreo de condición en la confiabilidad de los KPIs
Los KPIs son tan confiables como los datos que los alimentan. Si los datos dependen de que el técnico registre manualmente cada evento, con la presión del turno y la urgencia de la siguiente OT, la calidad del dato es variable.
El monitoreo de condición continuo potenciado por IA aporta datos que no dependen de la memoria ni de la disponibilidad del técnico. El tiempo de operación real del activo, los eventos de paro con duración exacta y las alertas de condición atendidas vs. pendientes se registran automáticamente.
Las alertas de condición crean un KPI que antes no existía: el porcentaje de fallas detectadas antes del paro. Ese indicador mide directamente la efectividad del programa predictivo y complementa al MTBF como medida de confiabilidad.
Errores frecuentes en la implementación de KPIs de mantenimiento
Medir demasiados KPIs desde el inicio. Cuando el equipo tiene que alimentar 15 indicadores, la calidad de los datos de entrada baja porque el tiempo para documentar cada evento es limitado.
No distinguir entre KPIs operativos y estratégicos. El supervisor necesita datos diarios. La dirección necesita tendencias trimestrales. Mezclarlos genera frustración en ambos.
Calcular sin normalizar. Un MTBF calculado sobre días de calendario sin considerar las horas reales de operación no refleja la confiabilidad del activo.
Celebrar la métrica en lugar de cuestionar el dato. Cuando un KPI mejora significativamente en un trimestre, la primera pregunta debería ser por qué mejoró, no cuánto mejoró.
La conexión entre KPIs y reducción de paros no planeados
El objetivo final de los KPIs no es llenar dashboards: es reducir los tiempos de inactividad que afectan la producción. Cada KPI debería responder a esta pregunta: ¿esta métrica me está ayudando a evitar el próximo paro no planeado?
El MTBF mide si los activos fallan menos. El MTTR mide si las intervenciones son más rápidas. La disponibilidad mide el resultado neto. El backlog mide si hay trabajo pendiente que podría prevenir la siguiente falla. El PMP mide si el trabajo es planificado o reactivo.
Cuando todos estos indicadores están alineados y mejorando, los paros no planeados disminuyen. Cuando alguno se desvía sin que los demás lo acompañen, hay un desbalance en el programa que requiere investigación.
Preguntas frecuentes
¿Cuántos KPIs debe medir un equipo de mantenimiento industrial?
Entre seis y diez. Lo importante no es la cantidad sino que cada KPI tenga una acción asociada cuando se desvía del objetivo. Un indicador sin acción es observación pasiva.
¿Cuál es un buen valor de MTBF para activos industriales?
No existe un valor universal. Lo relevante es la tendencia: un MTBF que mejora trimestre a trimestre indica que el programa está generando resultados, independientemente del valor absoluto.
¿Cómo se diferencia la disponibilidad del OEE?
La disponibilidad mide si el activo está operando o detenido. El OEE mide disponibilidad, rendimiento y calidad de forma integrada. Un activo puede tener disponibilidad alta y OEE bajo si opera con microparos, velocidad reducida o defectos de calidad.
¿Con qué frecuencia debo revisar los KPI de mantenimiento?
Los KPIs operativos (MTTR, backlog, OTs abiertas) se revisan diario o semanal. Los KPIs estratégicos (MTBF en tendencia, disponibilidad por línea, CMF) se revisan mensual o trimestral.
¿Qué hace que el backlog de mantenimiento sea útil y no solo una lista?
Un backlog útil está priorizado por criticidad del activo, tiene fechas comprometidas para cada OT y se revisa semanalmente para reasignar recursos. Un backlog sin priorización es una lista de deseos; uno gestionado es una herramienta de planificación.
Ve cómo Tractian genera métricas de disponibilidad, MTBF y MTTR automáticamente
