

Na rotina de manutenção industrial, não é raro que um mesmo alerta seja interpretado de formas diferentes por pessoas ou turnos distintos.
A mesma anomalia pode ser considerada prioridade no turno da manhã e ficar sem resposta no turno da noite, não por negligência, mas simplesmente porque não existe um critério comum para avaliar o que aquele alerta realmente significa.
Esse problema se intensifica em operações maiores, com múltiplas áreas, plantas ou níveis de criticidade distribuídos. A falta de padronização transforma alertas técnicos em disputas de autoridade, decisões inconsistentes e, no todo, mais ruído operacional.
Alarmes padronizados servem para resolver esse problema. Eles estabelecem uma linguagem comum, criando um método compartilhado que permite a qualquer pessoa da equipe entender, de forma objetiva, o que está acontecendo e o que deve ser feito.
Ao longo deste artigo, você vai entender o que são alarmes padronizados, o que acontece quando não há padrão na gestão de alertas e como implementar esse modelo de forma prática na sua operação.
Leia também:
- Da anomalia à causa raiz: passo a passo para reduzir retrabalho
- Matriz RACI: benefícios e como implementar na sua planta
- Lubrificação por condição: o que muda com ultrassom industrial contínuo
O que caracteriza um alarme padronizado
Dentro do monitoramento de condição, alarmes padronizados são alarmes com critérios objetivos e compartilhados que definem como interpretar e reagir a uma anomalia.
Em vez de deixar a priorização de ação sujeita à interpretação individual, a padronização estabelece níveis claros de severidade e associa cada nível a um tipo de resposta esperada.
A ideia é transformar uma lógica subjetiva em um método estruturado. Quando um sensor detecta vibração acima do esperado, por exemplo, o alarme padronizado já indica se aquilo é uma condição normal, uma anomalia em desenvolvimento ou uma situação crítica que exige intervenção imediata.
Além disso, ele orienta quem deve ser acionado, em quanto tempo a resposta deve acontecer e qual tipo de intervenção é mais adequada.
Esse modelo reduz variabilidade entre turnos, plantas e níveis de experiência do time, permitindo que decisões sejam tomadas com base em critérios técnicos, não em impressões pessoais.
Alerta técnico, alarme operacional e prioridade de manutenção
É importante entender a diferença entre três conceitos que muitas vezes se misturam na rotina de manutenção: alerta técnico, alarme operacional e prioridade de manutenção. Embora relacionados, cada um tem um papel específico no fluxo de decisão.
O alerta técnico é a detecção de uma condição anormal em um ativo, com base em medições de vibração, temperatura, corrente elétrica ou qualquer outro parâmetro monitorado. É a informação bruta gerada pelo sistema de monitoramento. Sozinho, ele não diz o que fazer, apenas indica que algo mudou.
Já o alarme operacional é a interpretação contextualizada desse alerta. Ele considera o valor medido, a criticidade do ativo, o histórico de comportamento, o contexto de operação e os limites definidos para cada nível de severidade. É aqui que o alerta técnico se transforma em uma informação acionável.
Por fim, a prioridade de manutenção define em que ordem as ações devem ser executadas. Nem todo alarme operacional exige resposta imediata. Alguns podem ser programados para a próxima janela de manutenção, enquanto outros demandam intervenção urgente. A prioridade ajuda o time a focar no que realmente importa, sem desperdiçar esforço em ações que poderiam esperar.
Quando esses três conceitos estão alinhados dentro de um modelo padronizado, a manutenção ganha clareza. O time sabe o que está acontecendo, entende o grau de urgência e consegue decidir com mais precisão o que fazer e quando agir.
O que acontece quando não há padrão
Quando os alarmes não seguem critérios padronizados, a organização perde o controle sobre como as decisões de manutenção são tomadas.
Mesmo com tecnologia de monitoramento avançada, a falta de padrão cria gargalos que travam o fluxo de trabalho, comprometem a confiabilidade e aumentam o desgaste operacional.
Disputa de prioridade entre áreas
Sem uma linguagem comum para severidade e criticidade, cada área interpreta os alertas à sua maneira.
Essa falta de alinhamento transforma a priorização em uma negociação constante, que perde mais tempo do que poupa. O tempo que deveria ser dedicado à execução da intervenção acaba sendo gasto em reuniões, mensagens e tentativas de convencer diferentes áreas sobre o que deve ser feito primeiro. No final, a decisão nem sempre é baseada no que é tecnicamente mais importante, mas em quem tem mais poder de influência ou urgência declarada naquele momento.
Dependência de poucos especialistas para traduzir
Quando os alarmes não são padronizados, a interpretação técnica fica concentrada em poucas pessoas. Apenas os especialistas conseguem distinguir o que é realmente crítico do que pode esperar.
Esse gargalo cria dependência e pressão excessiva sobre o time mais experiente, que acaba sendo acionado a todo momento para "traduzir" alertas e validar decisões.
Além de sobrecarregar essas pessoas, esse modelo compromete a escalabilidade da operação. Se um especialista está de férias, ausente ou concentrado em outra planta, a interpretação dos alarmes fica inconsistente ou simplesmente não acontece.
O conhecimento técnico necessário para tomar decisões corretas não se distribui pela equipe, concentrando risco e dificultando a autonomia do restante do time.
Retrabalho por decisões inconsistentes
Sem critérios claros, as decisões de intervenção variam de acordo com quem está no turno, quem fez a análise ou qual área está envolvida. Um mesmo tipo de alerta pode gerar uma correção preventiva em um turno e uma espera prolongada no turno seguinte.
Essa variabilidade leva ao retrabalho. Sem um critério de severidade, componentes são trocados prematuramente porque o alarme foi interpretado como mais grave do que realmente era. Ou, no sentido oposto, falhas evoluem até a quebra porque o alerta foi subestimado e a resposta atrasou
O resultado é uma manutenção que não ganha consistência com o nem e nem aprende com os próprios erros. Cada decisão parece isolada, sem um método que permita comparar, corrigir e melhorar a forma como a equipe responde aos alertas.
Fadiga de alerta
Quando os alarmes não são confiáveis, o time começa a desconfiar deles. Se um alerta classificado como crítico não leva a nenhuma falha real, a equipe passa a ignorá-lo. Se outro alerta é disparado com frequência sem que nada de fato aconteça, ele vira apenas mais um ruído no sistema.
Essa fadiga de alerta é um dos problemas mais graves causados pela falta de padronização. Ela corrói a credibilidade do sistema de monitoramento e faz com que alertas importantes sejam tratados com descaso. O time deixa de responder com a urgência necessária porque já se acostumou com falsos positivos ou com alarmes mal calibrados.
No limite, a fadiga de alerta transforma o monitoramento em um sistema que ninguém leva a sério, anulando completamente o valor que ele poderia trazer para a operação.
O papel da padronização na gestão da manutenção
A padronização de alarmes define como a organização interpreta sinais, toma decisões e coordena esforços entre áreas, turnos e plantas.
Quando bem aplicada, ela ataca diretamente os problemas estruturais que travam a manutenção e compromete a confiabilidade.
Veja alguns dos efeitos da padronização na rotina de gestão:

Reduzir variabilidade entre turnos e plantas
Uma das consequências mais diretas da padronização é a redução da variabilidade. Com critérios definidos, o mesmo tipo de alerta é interpretado da mesma forma, independentemente de quem está no turno ou em qual planta ele ocorreu. Isso cria consistência e facilita o controle de qualidade sobre as decisões de manutenção.
Essa uniformidade é especialmente importante em operações que funcionam 24 horas por dia ou que têm múltiplas unidades produtivas. Sem padrão, cada turno age à sua maneira, e o que foi feito no turno anterior muitas vezes não se conecta com o que será feito no próximo.
Com alarmes padronizados, o fluxo de trabalho se mantém coerente ao longo do tempo, permitindo rastreabilidade e aprendizado contínuo.
Prioridades mais claras
Quando os níveis de severidade são bem definidos e conectados à criticidade dos ativos, as prioridades emergem de forma natural. A equipe sabe o que precisa ser resolvido primeiro e pode organizar o backlog com base em critérios objetivos, sem espaço para dubiedade.
Isso também facilita a comunicação entre áreas. Produção, manutenção, engenharia e PCM passam a "falar a mesma língua" ao discutir prioridades. Um alerta “de nível 3 em um ativo crítico A” tem um significado compartilhado por todos, o que reduz disputas e acelera decisões.
Maior previsibilidade operacional
Alarmes padronizados tornam a manutenção mais previsível. A equipe sabe o que esperar de cada nível de severidade, conhece os tempos de resposta esperados e consegue planejar intervenções com antecedência. Isso melhora a coordenação com produção, reduz paradas não planejadas e permite um uso mais eficiente dos recursos de manutenção.
A previsibilidade também fortalece a confiança entre as áreas. Quando a produção sabe que um alerta de nível 2 será tratado dentro de um prazo definido, ela consegue ajustar a programação com mais segurança. Quando a manutenção tem clareza sobre o que é realmente urgente, ela consegue organizar o trabalho sem precisar reagir a todo momento.
Menos alertas perdidos
Um dos benefícios menos visíveis, mas extremamente importantes, da padronização é a redução de alertas perdidos. Quando os critérios são claros e a equipe confia no sistema, os alertas passam a ser tratados de forma sistemática. É muito mais improvável que um aviso importante seja ignorado porque parecia um alarme falso.
A padronização cria um compromisso operacional: se o alerta disparou em determinado nível, ele deve ser investigado e tratado conforme o protocolo. Isso reduz a chance de que uma anomalia em desenvolvimento passe despercebida e evolua até uma falha crítica.
Passo a passo: como padronizar alarmes
Implementar um modelo de alarmes padronizados exige método. Não basta definir níveis de severidade no papel e esperar que a equipe comece a usá-los. A padronização funciona quando é construída de forma colaborativa, validada na prática e conectada ao fluxo real de manutenção.
A seguir, você confere um passo a passo prático para estruturar alarmes padronizados na sua operação:
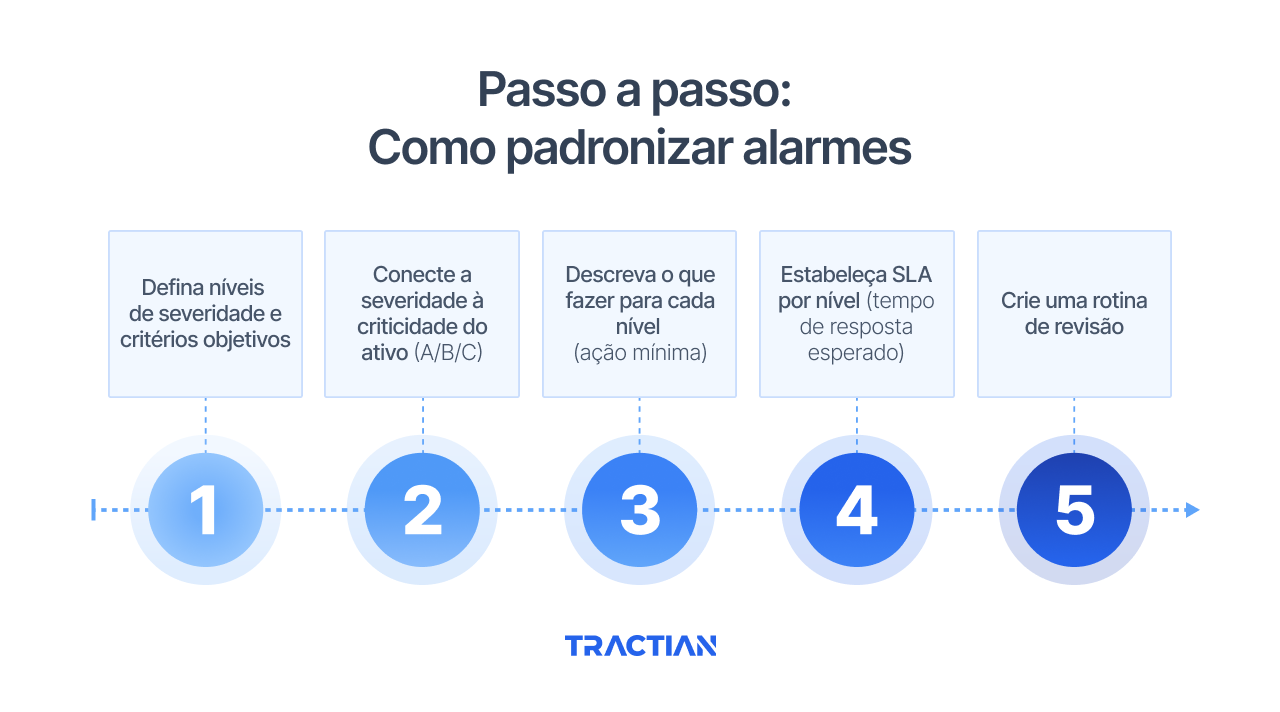
1. Defina níveis de severidade e critérios objetivos
O primeiro passo é estabelecer quantos níveis de severidade fazem sentido para a sua operação e quais são os critérios técnicos que caracterizam cada um deles. Não existe um número ideal de níveis, mas a prática mostra que entre 3 e 5 níveis costumam ser suficientes para cobrir a maioria dos cenários industriais.
Cada nível deve ter critérios claros e mensuráveis. Por exemplo:
- Nível 1 – Normal: Equipamento operando dentro dos parâmetros esperados. Nenhuma ação necessária.
- Nível 2 – Atenção: Desvio leve detectado, mas ainda dentro de limites aceitáveis. Reforçar monitoramento e programar inspeção na próxima janela de manutenção.
- Nível 3 – Alerta: Desvio significativo que exige análise técnica. Investigar causa e planejar intervenção em até 72 horas.
- Nível 4 – Crítico: Condição anormal que pode evoluir para falha em curto prazo. Intervenção obrigatória em até 24 horas.
- Nível 5 – Emergência: Risco iminente de falha catastrófica ou comprometimento da segurança. Intervenção imediata. Considerar parada programada de emergência.
Crie um sistema de níveis que faça sentido para a sua operação, não precisa ser exatamente como mostramos aqui. O importante é que cada nível esteja amarrado a valores mensuráveis de vibração, temperatura, corrente elétrica ou outros parâmetros monitorados. Isso elimina margem para interpretação subjetiva.
2. Conecte a severidade à criticidade do ativo (A/B/C)
Os níveis de severidade ganham mais relevância quando combinados com a criticidade do ativo. Um alerta de nível 3 em um ativo de criticidade A (crítico para a operação) exige resposta mais rápida do que o mesmo nível 3 em um ativo de criticidade C (redundante ou de baixo impacto).
Essa conexão permite priorizar de forma inteligente. A matriz de severidade X criticidade define não só o que está acontecendo, mas o quanto aquilo importa para a operação.
Esse modelo garante que o esforço da equipe se concentre onde o impacto operacional é maior, mas sem ignorar ativos secundários.
3. Descreva o que fazer para cada nível
Cada nível de severidade deve vir acompanhado de uma ação mínima esperada. Isso orienta o time sobre o que deve ser feito, reduzindo ambiguidade e acelerando a resposta.
Por exemplo:
- Nível 2: Registrar no histórico + acompanhar evolução. Não exige ação de campo.
- Nível 3: Análise técnica obrigatória + Identificar causa provável + Planejar intervenção.
- Nível 4: Inspeção em campo + Validar componente afetado + Definir escopo de intervenção e mobilizar recursos.
- Nível 5: Parada imediata ou programada de emergência + Mobilização de equipe especializada.
Essas descrições evitam que a equipe fique paralisada tentando decidir o que fazer. O protocolo já indica o caminho mínimo, e o time pode ajustar conforme o contexto específico.
4. Estabeleça SLA por nível (tempo de resposta esperado)
Além de definir o que fazer, é fundamental estabelecer em quanto tempo a ação deve acontecer. Esse SLA (Service Level Agreement) cria compromisso e permite rastrear se o processo está sendo cumprido.
Por exemplo:
- Nível 2: Sem prazo fixo. Acompanhar na próxima inspeção programada.
- Nível 3: Análise técnica em até 48 horas. Planejamento de intervenção em até 72 horas.
- Nível 4: Inspeção em até 12 horas. Intervenção em até 24 horas.
- Nível 5: Resposta imediata. Mobilização em até 2 horas.
Esses tempos devem ser realistas e ajustados à capacidade operacional da equipe. SLAs impossíveis de cumprir geram frustração e perdem credibilidade rapidamente. O importante é que sejam cumpridos de forma consistente.
5. Crie uma rotina de revisão
Alarmes padronizados não são um modelo estático. À medida que a operação evolui, novos ativos são incluídos, processos mudam e a maturidade da equipe aumenta. Por isso, é essencial criar uma rotina de revisão periódica dos critérios de severidade, SLAs e ações esperadas.
Essa revisão pode acontecer trimestralmente ou semestralmente, dependendo da dinâmica da planta. O objetivo é validar se os níveis ainda fazem sentido, se os tempos de resposta estão sendo cumpridos e se há necessidade de ajustes.
Usar dados históricos de alarmes disparados, tempo de resposta real e resultados de intervenções ajuda a calibrar o modelo ao longo do tempo. A padronização se torna um processo de melhoria contínua, não uma decisão única.
Como automatizar o processo com tecnologia
Padronizar alarmes manualmente é possível, mas limitado. Quando a operação envolve centenas ou milhares de ativos, múltiplas plantas ou alta frequência de alertas, a gestão manual se torna insustentável. É aqui que a tecnologia entra para viabilizar a padronização em escala.
Sistemas de monitoramento de condição modernos permitem configurar níveis de severidade por ativo, tipo de equipamento e criticidade. Eles aplicam os critérios de forma automática, classificam os alertas em tempo real e direcionam as notificações para as pessoas certas, conforme o SLA estabelecido.
Além disso, sistemas robustos como o da Tractian conseguem aprender com o histórico. Ao analisar padrões de comportamento, eles ajustam os limites de alerta de acordo com o perfil operacional de cada ativo, reduzindo falsos positivos e aumentando a confiança da equipe nos alarmes disparados.
A automação também facilita a rastreabilidade. Cada alerta fica registrado com data, hora, nível de severidade, ativo afetado e ações tomadas. Isso permite auditar o processo, identificar gargalos e avaliar a eficácia da resposta ao longo do tempo.
Automatizar a padronização de alarmes não substitui o trabalho da equipe, só potencializa sua capacidade de agir de forma rápida, consistente e fundamentada em dados.
Como a parceria Tractian e Abecom ajuda a fechar o ciclo de alarme e ação
Mesmo com critérios claros e tempos de resposta bem definidos, muitas operações ainda enfrentam dificuldade em transformar o alerta em ação efetiva. O diagnóstico chega, mas a execução trava por falta de contexto técnico, especificação inadequada de componentes ou ausência de um fluxo estruturado entre detecção e correção.
A parceria entre Tractian e Abecom conecta duas frentes complementares da confiabilidade industrial: de um lado, o diagnóstico orientado por dados; do outro, a execução técnica fundamentada em experiência de campo e acesso a um catálogo completo de soluções.
A solução de monitoramento de condição da Tractian processa sinais de vibração, temperatura e outros parâmetros para identificar anomalias e classificá-las conforme níveis de severidade. Ela gera alertas contextualizados que indicam não apenas que algo mudou, mas o que aquilo pode significar em termos operacionais. Com isso, a padronização de alarmes se torna mais inteligente, ajustando-se ao comportamento real de cada ativo e reduzindo falsos positivos.
A Abecom, maior distribuidora SKF no Brasil, com mais de 60 anos de atuação em manutenção industrial, entra como suporte técnico e braço de execução. Além de um catálogo com mais de 30.000 itens, a empresa oferece serviços de confiabilidade aplicada, como análise de vibração, alinhamento a laser, balanceamento de campo, termografia, ultrassom, análise de óleo e revisão de planos de lubrificação.
Essa combinação permite que o alerta padronizado não fique preso no diagnóstico. Ele se desdobra em recomendações técnicas claras sobre qual intervenção aplicar, qual componente especificar e como executar a correção de forma que a falha não se repita.
Se sua operação ainda depende de critérios informais para reagir a alertas, esse é o momento de se atualizar.
