

Na maioria das plantas industriais, o downtime não planejado é tratado como um problema apenas de manutenção. Quando uma linha para, o foco imediatamente se torna acionar o técnico, identificar o componente e restabelecer a operação.
No entanto, depois de resolver o problema e colocar as máquinas para rodar novamente, toda a informação que poderia ser usada como inteligência estratégica é perdida. Os relatórios mensais apontam a causa das paradas como "falha mecânica" e o registro para por aí, sem que alguma ação seja tomada além disso.
Esse tipo de dado não tem granularidade suficiente para orientar nenhuma ação específica. E quando a causa registrada é genérica demais, o ciclo de investigação nunca chega à raiz. Em pouco tempo, o downtime se repete como se fosse inevitável.
Este artigo mostra como sair desse ciclo, desde a forma de capturar e categorizar eventos de produção até o uso do Pareto de perdas para fechar o loop entre detecção, intervenção e validação de resultado.
Leia também:
- Top 3 sensores de vibração para moinhos de cana
- Como priorizar ordens de serviço com dados de condição
- Falha durante a safra: como antecipar com sensor de vibração
Por que o downtime pode estar se repetindo na sua indústria
Antes de pensar em solução, vale entender a raiz do problema. Na maioria dos casos, o downtime recorrente é sinal de que o processo de investigação nunca chegou fundo o suficiente. E isso começa pela forma como os eventos são registrados.
Alguns motivos possíveis para isso são:
Falta profundidade no registro
Quase toda planta registra suas paradas em relatório, nem que seja apenas por obrigação para auditorias. O ponto crítico é o nível de detalhe com que isso é feito.
Registrar "falha mecânica" como causa de uma parada é como anotar "dor" como diagnóstico médico. É tecnicamente verdadeiro, completamente inútil para tratar o problema. A falha é o sintoma, não a causa.
O que você precisa saber, de fato, é:
- Qual equipamento? O compressor da linha 3 ou o redutor da linha 5?
- Qual componente? Rolamento, vedação, correia, sensor?
- Qual turno concentra o evento? Sempre no noturno? Por quê?
- Qual SKU estava rodando? Tem relação com o produto, a velocidade ou o setup?
Sem esse nível, qualquer análise de Pareto que sua equipe fizer vai confirmar que "mecânica" é a maior causa de perda, mas não vai dizer o que fazer. Como consequência, o ciclo acaba se repetindo frequentemente, porque a investigação nunca chegou de fato à raiz.
O Pareto de perdas se torna inútil
O Pareto de perdas é uma das ferramentas mais poderosas da gestão de produção. Mas ele só funciona quando os dados de entrada têm qualidade suficiente.
Um Pareto que mostra "mecânica: 42% das perdas, elétrica: 18%, setup: 15%" parece informativo, mas não orienta nenhuma decisão. Afinal: qual máquina, qual falha mecânica, em que condição?
Já um Pareto que mostra "rolamento do compressor C3, turno noturno, produto SKU-081: 18 ocorrências nos últimos 30 dias" é um dado mais robusto, que possibilita uma intervenção específica, com janela de tempo definida e resultado mensurável.
A diferença entre os dois casos é a qualidade do dado que alimenta a análise. Isso independe do tipo de ferramenta utilizada para a análise.
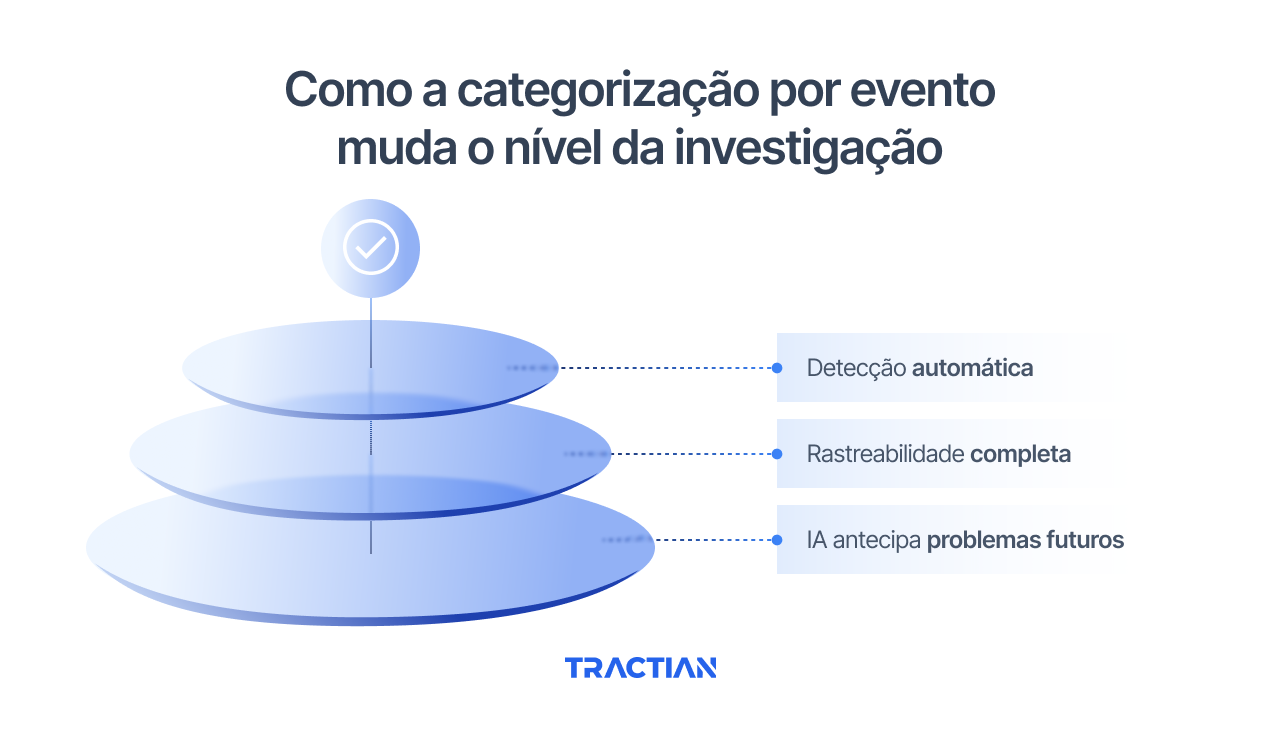
Como a categorização por evento muda o nível da investigação
Melhorar a qualidade dos dados não significa pedir mais esforço ao operador. É preciso redesenhar o processo de captura para que o dado certo apareça no momento certo, com o mínimo de atrito. Isso passa por três elementos: detecção automática de estado, rastreabilidade estruturada de cada evento e inteligência que aprende com o uso.
Vamos entender melhor cada um desses elementos:
Detecção automática de estados: o sistema trabalha antes do operador
O primeiro passo para ter dados de qualidade é eliminar a dependência da memória e do julgamento subjetivo no momento do registro. Quando o operador precisa lembrar, horas depois, o que aconteceu em determinada parada, a acurácia do dado cai inevitavelmente.
Sistemas modernos de monitoramento de produção detectam automaticamente o estado da linha (rodando, parada não planejada, redução de velocidade, setup, idle) com base em sinais físicos da máquina. Isso significa que a duração exata do evento, o horário de início e fim, e o estado em que a linha se encontrava já estão registrados antes mesmo de o operador abrir qualquer tela.
Assim, o papel do operador muda. Em vez de reconstruir o que aconteceu, ele complementa a informação no momento do evento, quando o contexto ainda está fresco.
Rastreabilidade completa: cada evento como uma fonte de inteligência
Para que uma parada seja investigável de verdade, ela precisa conter todos os elementos que permitem cruzar dados depois. Um evento de downtime bem registrado inclui:
- Estado: detectado automaticamente pelo sistema
- Duração: calculada automaticamente pelo sistema
- Causa: informada pelo operador no momento do evento
- Estação: qual ponto da linha foi afetado
- Turno: quem estava operando
- SKU: qual produto estava sendo produzido
- Operador: quem registrou a causa
Quando o operador categoriza a causa no momento, com opções estruturadas em vez de um campo de texto aberto, a rastreabilidade e a qualidade do dado sobem significativamente. Campos abertos geram 47 variações de "rolamento quebrado", enquanto categorias estruturadas geram um dado limpo, comparável e analisável.
IA como aliada da categorização: sugestão que aprende com o uso
Com o acúmulo de histórico, sistemas com inteligência artificial passam a sugerir a causa provável de cada evento com base em padrões anteriores. O operador confirma ou corrige a suspeita, e a cada interação, o sistema melhora a precisão das próximas sugestões.
Isso reduz o esforço cognitivo do operador, acelera o registro e cria um ciclo em que quanto mais o sistema é usado, mais preciso ele se torna. Eventualmente, a categorização deixa de ser um atrito no fluxo de trabalho e passa a ser quase automática.
Como usar o Pareto de Perdas para eliminar downtime e fechar o loop
Com os eventos bem categorizados, o Pareto de Perdas deixa de ser um exercício de consolidação e passa a ser um instrumento de decisão. Mas ele só cumpre esse papel quando é usado em toda a sua profundidade, indo do ranking simples de causas até o cruzamento de dimensões e a validação pós-intervenção.
Pareto por causa: onde concentrar esforço
Com dados categorizados com granularidade, o Pareto de perdas deixa de ser um gráfico bonito e passa a ser um instrumento de priorização real. Ele mostra, com objetividade, quais causas respondem pela maior parte do tempo perdido e quais merecem atenção imediata.
A lógica é simples: se três causas respondem por 70% do downtime não planejado, atacar essas três causas tem mais impacto do que distribuir esforço por toda a lista. O Pareto torna essa priorização visível e defensável em uma negociação entre diferentes áreas.
Pareto cruzado: os padrões que só aparecem no cruzamento
O verdadeiro poder da análise, porém, está no cruzamento de dimensões. Um evento que parece aleatório isoladamente pode revelar um padrão claro quando você cruza causa, turno, estação e SKU ao mesmo tempo.
Veja alguns exemplos do que esse cruzamento pode revelar:
- A mesma falha mecânica ocorre três vezes mais no turno da noite do que nos outros? Isso pode indicar diferença de procedimento, nível de atenção ou condição ambiental.
- Um SKU específico concentra paradas por setup acima da média? Pode indicar um problema no procedimento de troca ou na parametrização da máquina para aquele produto.
- Uma estação específica acumula paradas curtas e frequentes que, somadas, superam em tempo perdido as paradas longas que todo mundo tenta evitar? É preciso dar mais atenção aos procedimentos nessa estação e investigar o que está causando essas pausas.
Esses padrões são invisíveis quando os dados estão agregados. Eles só aparecem quando você tem granularidade suficiente para cruzar dimensões.
Causa mecânica recorrente: cruzando OEE com monitoramento de condição
Quando o Pareto aponta uma causa mecânica recorrente em uma estação específica, o próximo passo é investigar se existe correlação com a condição do ativo.
Se o equipamento está sendo monitorado continuamente com sensores que acompanham vibração, temperatura e outros indicadores, é possível verificar se o downtime está se concentrando em momentos em que o ativo já apresentava sinais de deterioração.
Esse cruzamento entre dado de produção e dado de condição é o que transforma a manutenção reativa em preditiva. Em vez de esperar a falha, a equipe age quando o dado mostra que o risco está crescendo.
Validação: o mesmo Pareto que priorizou precisa validar
Depois de intervir em uma causa, o ciclo só se fecha com validação. A pergunta é direta: o downtime naquele ponto de foco caiu depois da intervenção?
Se caiu, a causa-raiz foi identificada corretamente e a intervenção foi eficaz. Se não caiu, a causa-raiz não era aquela e a investigação precisa ir mais fundo.
Esse é o loop completo:
Pareto prioriza → Equipe intervém → Pareto valida
Sem a etapa de validação, a manutenção fica presa num ciclo de ações sem evidência de resultado.
Qual é o papel do OEE na redução de downtime?
Quando falamos de OEE (Overall Equipment Effectiveness), podemos estar nos referindo a um indicador muito usado e confiável que mede o desempenho dos equipamentos de uma planta.
Mas também é usado para definir sistemas de Monitoramento de Produção, que são utilizados amplamente para medir e melhorar esse indicador, como é o caso do Tractian OEE.
Esse tipo de sistema estrutura a captura dos dados de produçãpo desde o início, detectando estados automaticamente, organizando o contexto de cada evento e permitindo que o operador contribua com o que só ele sabe, no momento em que ainda sabe.
Quando bem implementado, ele funciona como um modelo interpretativo que reconstrói o comportamento real da linha de produção turno a turno. É uma linha do tempo estruturada de tudo que aconteceu na produção, com estado, duração, causa, operador, SKU e estação registrados em cada evento.
Essa estrutura é o que transforma o dado de produção em algo investigável. Com ela, qualquer parada pode ser analisada no contexto exato em que ocorreu.
Para a redução de downtime não planejado, cinco características do OEE fazem diferença prática:
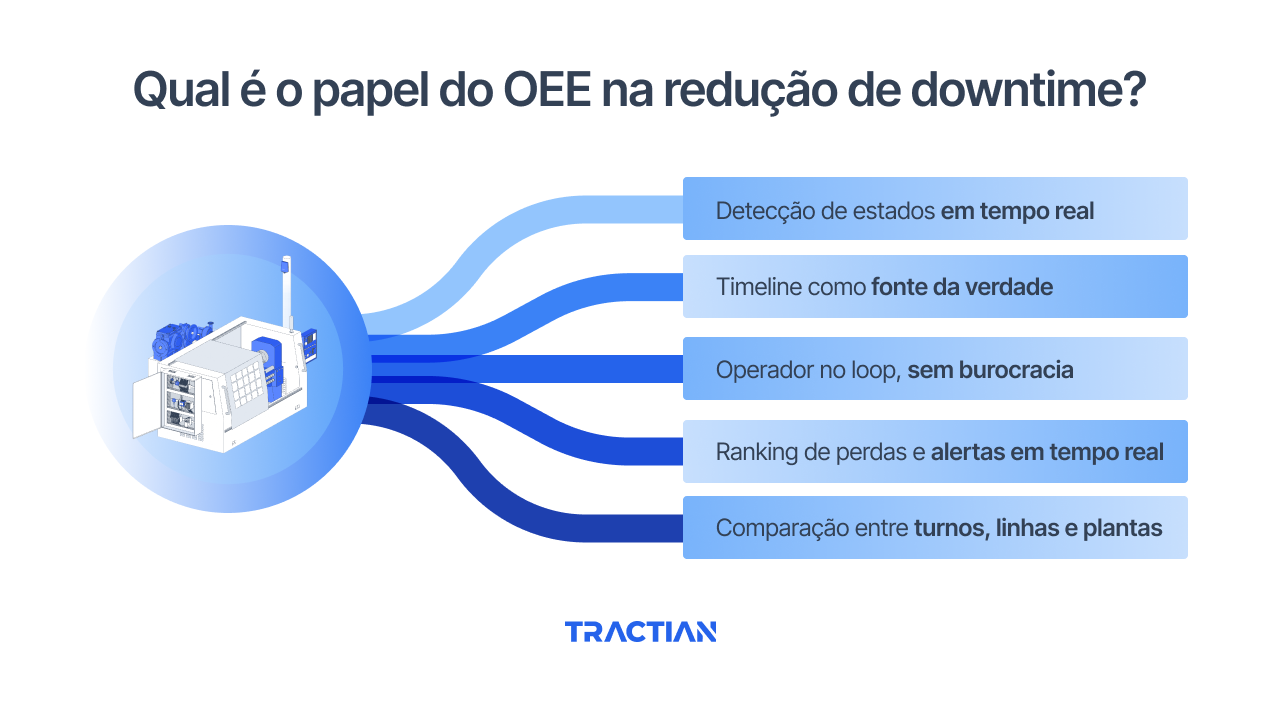
1. Detecção de estados em tempo real
O sistema interpreta sinais físicos da máquina (velocidade, ciclos, consumo) e classifica automaticamente o estado da linha: rodando, parada não planejada, redução de velocidade, setup, idle.
Isso elimina o atraso entre o evento e o registro, e garante que a linha do tempo do turno seja fiel ao que realmente aconteceu.
2. Timeline como fonte da verdade
Cada turno é reconstruído como uma sequência cronológica de eventos. Cada evento contém estado, duração, operador, SKU, estação e causa.
Essa linha do tempo é o que permite investigar um downtime com precisão, entender o contexto em que ele ocorreu e identificar padrões ao longo do tempo.
3. Operador no loop, sem burocracia
O sistema detecta o estado do equipamento automaticamente e o operador entra para informar a causa com categorias estruturadas, no momento do evento.
Esse modelo híbrido reduz o tempo gasto com burocracias no registro sem criar carga administrativa. A produção continua fluindo, e o dado é capturado com qualidade.
4. Pareto de perdas atualizado continuamente
Com a timeline sendo alimentada em tempo real, o Pareto de perdas também é atualizado continuamente.
Isso permite que gestores e engenheiros acompanhem a evolução das causas sem esperar o fechamento do turno ou a consolidação manual de planilhas.
5. Comparação entre turnos, linhas e plantas
Quando o mesmo equipamento, operando com o mesmo SKU, apresenta desempenho diferente em turnos distintos, isso aponta para uma variável humana ou de processo, não mecânica.
Esse tipo de comparação só é possível quando os dados são estruturados e consistentes o suficiente para ser cruzados com confiança.
Como a Tractian reduz downtime não planejado com OEE
A Tractian desenvolveu seu módulo de OEE exatamente para resolver o problema descrito ao longo deste artigo: dados de produção que parecem completos, mas são rasos demais para orientar decisões reais.
O módulo de OEE da Tractian detecta automaticamente o estado da linha a partir de sinais físicos, eliminando a dependência de relato manual para saber se a máquina está rodando, parada ou em setup. Cada evento é registrado com estado, duração, turno, SKU, estação e operador, criando uma linha do tempo fiel do que aconteceu em cada turno.
O operador participa do processo categorizando a causa do evento entre opções já estruturadas, no momento em que ele ocorre. Sem campos abertos, sem precisar de uma longa reconstrução de memória depois do turno.
Quando há histórico acumulado, a inteligência artificial da plataforma começa a sugerir causas com base em padrões anteriores. O operador confirma ou corrige e, com essa resposta, o modelo aprende. A categorização fica mais rápida, mais precisa e menos dependente do julgamento individual.
Além disso, o Pareto de perdas é atualizado continuamente e pode ser cruzado por causa, turno, estação e SKU. Isso possibilita que a equipe identifique padrões que só aparecem no cruzamento de dimensões e priorize as intervenções com base em impacto real, não em percepção.
E quando a causa é mecânica e o ativo é associado ao monitoramento de condição da Tractian, o cruzamento vai além: é possível verificar se o downtime está correlacionado com sinais de deterioração já detectados pelo sensor ou não.
Isso fecha o loop entre produção e manutenção preditiva e transforma a gestão de ativos numa estratégia integrada, não em duas operações paralelas.
Você já sabe como otimizar o caminho entre detecção, ação e resultado para diminuir o tempo perdido em paradas. Agora só falta ver funcionando na sua planta.
