
Quem vive a rotina de uma usina sabe que a entressafra não é um momento de pausa, é na verdade uma corrida contra o tempo. E a safra, por sua vez, não perdoa erro. Se um redutor quebra, se uma OS não foi executada apropriadamente, ou se uma peça crítica não está no estoque, o prejuízo aparece em horas.
O que muitas vezes passa despercebido é que boa parte dessas falhas nasce da ausência de controle. O problema não é só falta de planejamento, mas não saber o que foi feito, quando, como e com que resultado. Ou seja, falta rastreabilidade: é preciso enxergar o que está atrasado, o que está falhando de novo e o que deveria ser prioridade.
Mas o que medir? E como medir?
Neste artigo, você verá quais são os indicadores de manutenção mais importantes de serem acompanhados dentro de uma usina sucroalcooleira, qual é a forma mais eficiente de medi-los e como você pode aplicá-los, na prática, dentro do seu chão de fábrica.
O que medir em usinas sucroalcooleiras?
A rotina de uma usina envolve centenas de tarefas distribuídas entre a planta industrial, o pátio e o campo. São equipes operando sob pressão, ativos com perfis distintos e janelas curtas para intervenção. Nesse cenário, é fácil cair na armadilha de medir tudo, ou pior ainda, de medir o que é fácil de extrair e deixar de lado o que realmente importa.
Indicadores como "quantidade de ordens abertas", "custo de manutenção por mês" ou "horas acumuladas em corretiva" podem até ser úteis como referência, mas raramente dizem o que você precisa saber para garantir disponibilidade e confiabilidade no dia a dia.
O que realmente precisa ser medido é aquilo que muda a forma como sua equipe age, é isso que permite ajustar o curso da operação antes que a falha aconteça.
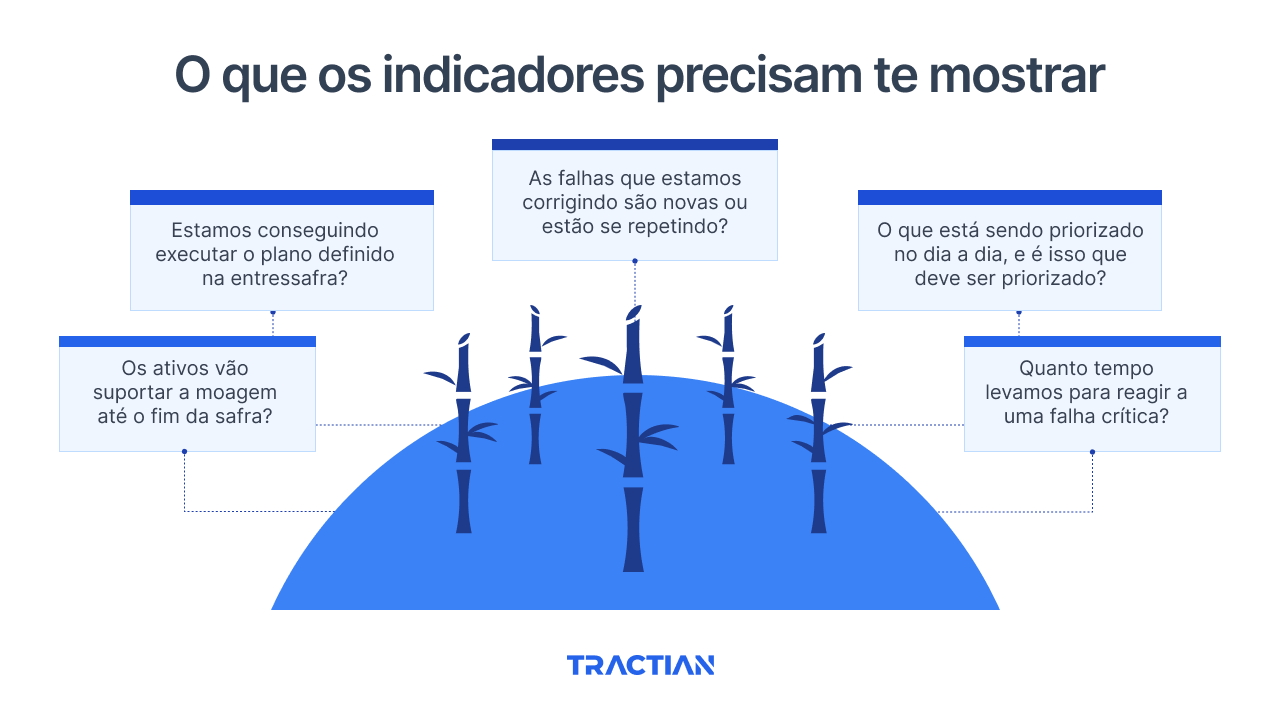
Em outras palavras: bons indicadores não são números de relatório. São instrumentos que vão guiar decisões. E para que cumpram esse papel, precisam responder perguntas críticas como:
- Os ativos vão suportar a moagem até o fim da safra?
- Estamos conseguindo executar o plano definido na entressafra?
- As falhas que estamos corrigindo são novas ou estão se repetindo?
- O que está sendo priorizado no dia a dia, e é isso que deve ser priorizado?
- Quanto tempo levamos para reagir a uma falha crítica?
Se os dados disponíveis hoje na sua operação não te ajudam a responder essas perguntas com clareza, então está na hora de rever o que está sendo medido.
A seguir, você verá os 5 indicadores que mais impactam a confiabilidade da operação em uma usina sucroalcooleira e como aplicar cada um deles, de forma prática, na sua rotina de manutenção.
1. MTBF
Entre os muitos indicadores de manutenção que circulam nos relatórios de usinas, poucos são tão negligenciados, e ao mesmo tempo tão reveladores, quanto o MTBF (Mean Time Between Failures).
Ele mede o tempo médio entre falhas de um ativo, e quando aplicado corretamente, revela se os seus equipamentos estão realmente confiáveis ou apenas “sobrevivendo até a próxima parada”.
Nas usinas, esse número deveria ser acompanhado com atenção redobrada para todos os ativos que operam de forma contínua durante a safra: moendas, redutores, bombas, exaustores, ventiladores, esteiras transportadoras.
Equipamentos que não podem parar, mas que, sem essa medição, acabam parando - e geralmente no pior momento possível.
Como medir corretamente o MTBF
Evite a armadilha de calcular esse indicador de forma isolada para ativos individuais. O ideal é analisar o MTBF por sistema ou subsistema funcional. Por exemplo, a casa de força como um todo, o sistema de extração ou o conjunto de bombas de circulação da torre de resfriamento.
Essa abordagem oferece duas vantagens:
- Permite observar tendências de falha em blocos técnicos que operam de forma integrada;
- Elimina ruídos causados por ativos com pouca amostragem ou intervenções pontuais.
O cálculo é simples: divida o tempo total de operação dos ativos pelo número de falhas registradas em um período. Mas atenção: o valor só é útil quando há registro consistente das falhas reais, não apenas das paradas.
Como interpretar (e agir sobre) esse indicador
Um MTBF alto, por si só, não é garantia de saúde. Ele pode esconder falhas mal registradas ou ativos que estão simplesmente sem histórico confiável. Por isso, o MTBF precisa ser lido em conjunto com o histórico de OSs, com o backlog e com o plano de manutenção preventiva.
Quando o número começa a cair, ele pode indicar:
- Ciclos de manutenção mal dimensionados, que normalmente apontam para preventivas que não estão atacando a raiz do problema;
- Execução de ordens sem padrão técnico, ou seja, ausência de POPs/SOPs ou inspeções rasas;
- Falta de peças, ferramental ou tempo adequado para fazer a manutenção corretamente;
- Substituições por peças não originais ou de baixa durabilidade.
2. MTTR
Se o MTBF revela a confiabilidade de um ativo, o MTTR (Mean Time to Repair) mostra o quão preparada está a sua equipe para reagir quando a falha acontece.
Na prática, esse indicador mede o tempo médio que a equipe leva para restaurar o funcionamento de um ativo após uma falha, desde a identificação até a correção completa. Em usinas onde paradas inesperadas podem gerar prejuízos expressivos em horas, o MTTR se transforma rapidamente em um dos termômetros mais sensíveis da eficiência operacional.
Durante a safra, por exemplo, um tempo médio de reparo acima do aceitável costuma significar duas coisas: falta de padrão técnico e baixa fluidez na execução. Não é só sobre velocidade, mas principalmente sobre a capacidade de reagir com precisão, sem retrabalho e com o recurso certo, na hora certa.
Como medir corretamente o MTTR
O MTTR deve ser medido por tipo de ativo ou falha, sempre considerando o tempo total da intervenção (desde a abertura da OS até o retorno pleno da operação).
Evite generalizar a análise com médias enganosas. Em vez disso:
- Compare o MTTR por área crítica, como extração, preparação, caldeira e moagem;
- Priorize os ativos com maior impacto de parada (ex: redutores principais, bombas de recirculação da torre de resfriamento, motores de exaustão térmica);
- Considere variações sazonais, até porque uma falha na entressafra não tem o mesmo peso de uma parada em safra.
Como interpretar (e agir sobre) esse indicador
Um MTTR alto não significa apenas que a equipe demorou para resolver uma falha. Ele pode sinalizar falhas estruturais na operação, como:
- Desorganização no fluxo de atendimento: OSs que chegam incompletas, sem diagnóstico prévio ou histórico técnico;
- Falta de padronização: ausência de procedimentos operacionais claros, resultando em abordagens diferentes para a mesma falha;
- Carência de recursos no momento da falha: ferramentas ou peças que não estão onde deveriam estar, forçando improviso ou espera;
- Gargalos de conhecimento: técnicos novos ou sem capacitação suficiente para atuar em equipamentos específicos.
Se o tempo entre o início da falha e a retomada da operação é grande, o prejuízo é maior do que parece, já que envolve não só perda de produção, mas também retrabalho, desperdício de tempo técnico e desorganização da fila de ordens.
3. Backlog
Backlog de manutenção é um dos indicadores mais importantes, e um dos mais mal interpretados, dentro das usinas. Em vez de ser tratado como alerta, ele acaba normalizado. O problema é que, sem controle, o que hoje é corretiva de baixa prioridade pode se transformar em falha crítica amanhã.
Na prática, o backlog representa o volume de ordens de serviço pendentes de execução, seja por falta de recurso, tempo, pessoal ou priorização. Ele afeta diretamente a confiabilidade da planta porque impede que o time atue de forma preventiva. Quando há fila demais, a manutenção para de planejar e passa a só apagar incêndio.
Como medir corretamente o backlog
A maioria das equipes acompanha apenas o backlog total (em horas). Mas isso raramente é suficiente.
O ideal é dividir o indicador em três frentes:
- Backlog total por área ou sistema funcional: Alguns exemplos comuns são a moagem, evaporação, fermentação, utilidades. Isso permite atacar os gargalos com mais foco.
- Backlog crítico: Quantas OSs estão em aberto para ativos de alta criticidade? Esse número é o que define o risco real da operação.
- Backlog por tipo de serviço: Preventiva, corretiva planejada, inspeção, lubrificação. Isso revela onde está o acúmulo e o que está sendo deixado de lado.
Além disso, é essencial comparar o backlog com a capacidade de execução da equipe. Não adianta saber que há 400 horas pendentes se sua equipe executa no máximo 160 horas por semana.
Como interpretar (e agir sobre) esse indicador
Quando o backlog cresce, ele te mostra o acúmulo das ordens de serviço, mas também aponta para a falta de priorização e descompasso entre planejamento e execução.
As consequências desse acúmulo vão muito além da execução atrasada. A manutenção preventiva perde eficácia, a confiabilidade despenca e a entressafra se torna um gargalo praticamente intransponível, o que, no fim das contas, também compromete a moagem logo nos primeiros meses da safra.
Por isso, vale a pena ficar de olho em alguns sinais de alerta:
- OSs vencidas há mais de 15 dias em ativos críticos;
- Preventivas canceladas por falta de recurso;
- Técnicos realocados para emergenciais de forma recorrente.
4. OS planejadas vs. OS executadas
Planejar é essencial, mas de nada adianta se a execução não acompanha. Um dos erros mais comuns em usinas é confiar demais no cronograma de manutenção preventiva sem validar o que realmente foi realizado. O resultado disso acaba sendo ordens de serviço planejadas que não são executadas no prazo, falhas reincidentes e retrabalho no meio da safra.
Esse indicador - a relação entre OSs previstas e as que de fato foram concluídas - revela se o plano de manutenção está se sustentando na prática ou se virou apenas uma formalidade.
Como medir corretamente esse indicador
Mais do que um número, esse indicador é uma fotografia da execução. Mas ele só ganha valor quando é tratado com a mesma seriedade que o backlog ou a disponibilidade. Não basta saber quantas ordens foram encerradas no mês, o seu gerente de manutenção precisa entender o que foi deixado para trás, por que isso aconteceu e quais as consequências práticas dessas falhas de execução.
Para isso, é importante trabalhar com múltiplas perspectivas:
- Por tipo de OS: A execução de preventivas e inspeções precisa ser tratada com prioridade, afinal, são elas que evitam a próxima corretiva. Já a baixa execução de lubrificação, por exemplo, pode sinalizar risco direto de falha em motores e redutores.
- Por área crítica ou célula produtiva: Quando determinadas áreas acumulam ordens não executadas, isso afeta diretamente o rendimento do processo como um todo.
- Por técnico, turno ou frente de trabalho: Essa análise ajuda a identificar onde há gargalos operacionais ou desvio de foco.
O ideal é consolidar esses dados em ciclos curtos (semanais durante a entressafra, quinzenais na safra) e sempre com visibilidade para o time técnico.
Como interpretar (e agir sobre) esse indicador
A distância entre o que foi planejado e o que foi executado raramente é um problema isolado. Ela costuma ser o reflexo de falhas em cadeia: desalinhamento entre planejamento e operação, baixa priorização, falta de recurso técnico e ausência de padronização nos procedimentos.
Uma baixa taxa de execução pode indicar, por exemplo:
- Que a equipe está sobrecarregada com corretivas emergenciais e não consegue cumprir o plano;
- Que o planejamento foi feito sem levar em conta a rotina real da planta, como a janela de disponibilidade dos ativos ou a escala da equipe;
- Que não há visibilidade clara das tarefas pendentes, e por isso os técnicos atuam de forma reativa, sem autonomia ou clareza.
5. Disponibilidade operacional
De todos os indicadores da manutenção, a disponibilidade operacional é, talvez, o mais decisivo. Isso porque mostra o que realmente interessa: o quanto os ativos estão disponíveis para produzir, de forma estável e dentro do ciclo planejado.
Enquanto MTBF, MTTR e backlog ajudam a entender o comportamento da manutenção, a disponibilidade entrega o reflexo direto na produção. Nas usinas, onde o tempo de moagem é limitado e a pressão por rendimento é alta, qualquer desvio impacta o faturamento.
O número mágico aqui é 95%: a disponibilidade de ativos críticos durante a safra não pode ficar abaixo disso.
Como medir corretamente esse indicador
Medir a disponibilidade de forma genérica, como uma média da planta, só vai te ajudar a esconder os gargalos, e não resolvê-los. Por isso, o ideal é segmentar esse indicador por linha de processo, célula funcional ou ativo crítico, criando visões operacionais realmente acionáveis.
Por exemplo:
- Qual é a disponibilidade da moenda principal durante o segundo turno?
- Como está o comportamento da torre de resfriamento nos dias mais quentes da safra?
- A bomba de recirculação do sistema térmico esteve operando por quanto tempo sem interrupções no último mês?
Essas perguntas só podem ser respondidas quando a disponibilidade é medida com granularidade e atualizada com frequência. Dashboards mensais não funcionam em um ambiente que pode parar a qualquer hora. A atualização precisa ser diária, no mínimo, com visibilidade direta para operação e manutenção.
Outra recomendação é integrar essa métrica com o histórico de paradas, separando paradas planejadas, corretivas e por falha reincidente. Assim, é possível identificar não apenas o quanto a planta ficou indisponível, mas por qual motivo.
Como interpretar (e agir sobre) esse indicador
Quedas recorrentes de disponibilidade em um mesmo sistema ou turno indicam falhas estruturais de confiabilidade, falta de antecipação técnica ou planos de manutenção mal executados.
Veja os principais sintomas que aparecem quando a disponibilidade começa a cair:
- Manutenção corretiva dominando a agenda: time técnico está correndo atrás do que parou, e não atuando sobre o que pode parar;
- Falta de priorização de ativos críticos: quando todos os ativos são tratados da mesma forma, os mais importantes tendem a falhar primeiro;
- Desorganização entre operação e manutenção: ativos são mantidos indisponíveis por falta de liberação, ou liberados sem garantia de funcionamento.
Dito isso, esse indicador precisa ser interpretado como uma métrica de performance da manutenção, e não da produção. Se os ativos estão frequentemente indisponíveis por motivos técnicos, a causa está no chão de fábrica, e não na estratégia comercial da usina.
Resumo dos indicadores e como aplicá-los na sua usina
| Indicador | O que revela | Como aplicar na prática |
|---|---|---|
| MTBF (Tempo médio entre falhas) | Nível de confiabilidade dos ativos críticos | Avalie por sistema funcional; revise planos preventivos com base em reincidências |
| MTTR (Tempo médio de reparo) | Eficiência e preparo da equipe na resposta a falhas | Padronize procedimentos; organize recursos e trace gargalos por ativo ou tipo de falha |
| Backlog | Volume de trabalho pendente que compromete a confiabilidade | Classifique por criticidade; compare com a capacidade semanal da equipe |
| OSs planejadas vs. executadas | Aderência do plano de manutenção à execução real | Monitore desvios por área e tipo de OS; reavalie prioridades e causas das não-executadas |
| Disponibilidade operacional | Impacto real da manutenção na estabilidade da produção | Acompanhe por linha/ativo crítico; correlacione com tipos de parada e plano de confiabilidade |
Como o CMMS da Tractian pode orientar a sua usina sucroalcooleira
Como você já bem sabe, a operação de uma usina sucroalcooleira depende de uma manutenção confiável, eficiente e fundamentada em decisões técnicas, que precisam do auxílio dos dados.
Indicadores como MTBF, MTTR, backlog, taxa de execução de OSs e disponibilidade operacional te ajudam a ter visibilidade da operação como um todo e limitam as chances de alguma coisa dar errado.
Mas para que esses dados façam sentido na prática, a manutenção precisa operar com rastreabilidade total, padronização dos processos e visibilidade imediata sobre o que está sendo feito, por quem, quando e com qual resultado. Isso exige um sistema que conecte toda a cadeia da manutenção em uma única plataforma, de ponta a ponta.
O CMMS da Tractian foi desenvolvido para resolver justamente esse desafio. Com o nosso software, é possível transformar cada ordem executada, cada falha registrada e cada preventiva realizada em insumo direto para decisões mais ágeis, para um planejamento mais inteligente e para uma operação mais segura, desde a entressafra até o fim da moagem.
Nossa tecnologia conecta todos os dados operacionais da manutenção em um só sistema: da abertura da OS à análise de falhas, da priorização de ordens ao controle de estoque. O gestor tem visibilidade total da rotina, com insights acionáveis para reduzir paradas, otimizar recursos e garantir que o planejamento se cumpra exatamente como previsto.
Quer fazer um teste gratuito?
Comece hoje mesmo e veja como o CMMS da Tractian pode transformar sua usina, deixando na palma da sua mão o controle sobre todos esses indicadores e outros.
