

Quando um equipamento crítico apresenta comportamento irregular, você tem duas opções: começar a trocar peças na esperança de resolver o problema ou seguir um método estruturado para identificar exatamente o que está acontecendo.
O troubleshooting sistemático é uma metodologia que pode ajudar nisso, transformando técnicos experientes em detetives industriais. É a melhor forma de conectar sintomas aparentemente isolados com suas causas reais. Não é só consertar o que quebrou, é entender por que quebrou e como evitar que aconteça novamente.
Neste artigo, veja como estruturar um processo de troubleshooting eficiente, desde a identificação inicial dos sintomas até a documentação das soluções, além de entender como manutenção preditiva pode acelerar drasticamente esse processo na sua operação.
Leia também:
- Top 3 sensores de vibração para moinhos de cana
- Como o monitoramento de condição muda a rotina de times pequenos
- Manutenção Preditiva: Como Implementar em 2026 (Guia Prático + ROI)
O que é troubleshooting na manutenção industrial
Troubleshooting é um processo sistemático para identificar, diagnosticar e resolver problemas em equipamentos industriais. Isso acontece com o uso de análise lógica e metodologia estruturada. A tradução literal do termo em inglês seria "solução de problemas", mas no contexto industrial, ele vai muito além de simplesmente consertar algo que quebrou.
Diferente da manutenção corretiva, que reage a falhas já estabelecidas, o troubleshooting envolve uma etapa de investigação ativa para descobrir a causa raiz do problema e resolvê-la de vez. E enquanto a manutenção preventiva segue cronogramas pré-definidos, o troubleshooting só é acionado quando algo sai do padrão esperado.
O processo exige uma abordagem metódica que combina observação, análise de dados, formulação de hipóteses e testes controlados. Não é apenas sobre trocar peças até que algo funcione novamente, é sobre entender por que o problema aconteceu e como evitar que se repita.
Passos fundamentais para solucionar problemas de modo eficaz
O troubleshooting eficiente segue uma sequência lógica que maximiza as chances de identificar e resolver problemas rapidamente, sem desperdício de tempo ou recursos. Cada etapa constrói sobre a anterior, criando um processo confiável que funciona consistentemente.
Veja um passo a passo eficiente:
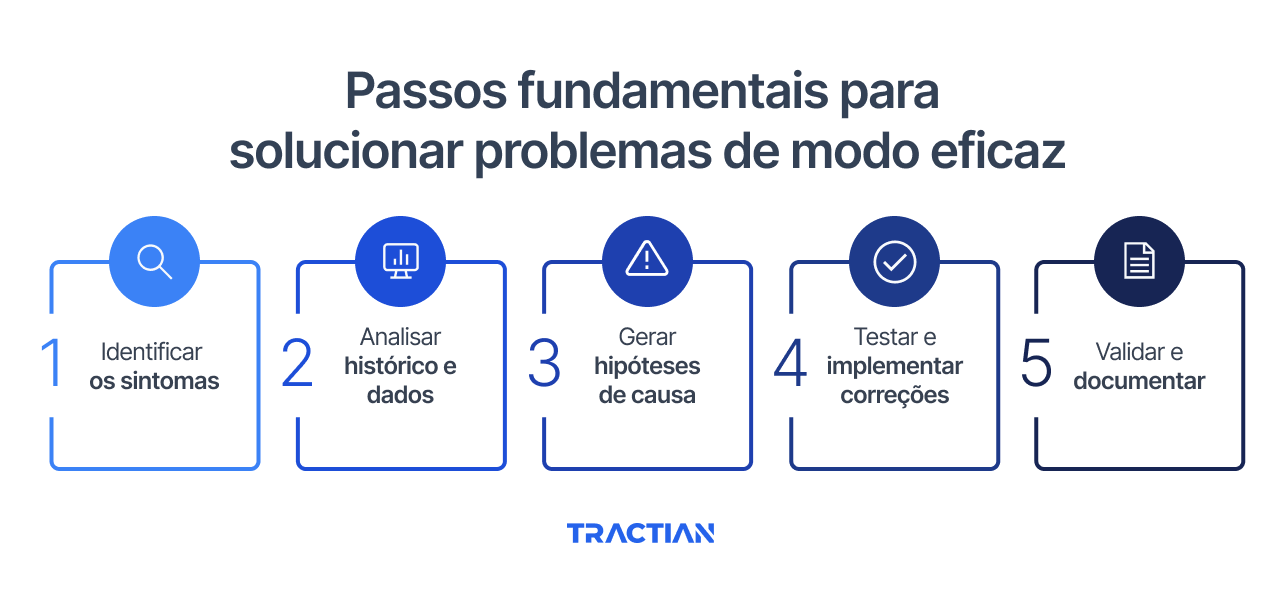
1. Identificar os sintomas
A primeira etapa consiste em coletar todas as informações disponíveis sobre o comportamento anômalo do equipamento. Essa coleta deve ser abrangente e sistemática, pois detalhes aparentemente irrelevantes podem ser cruciais para o diagnóstico.
Durante a observação direta, registre tudo que pode ser percebido pelos sentidos: ruídos estranhos, vibrações excessivas, odores incomuns, alterações visuais como vazamentos ou descoloração. Cada sinal físico conta uma parte da história do problema.
Analise parâmetros mensuráveis como temperatura, pressão, corrente elétrica, velocidade de rotação e consumo energético. Variações nesses valores frequentemente precedem falhas mais graves.
2. Analisar histórico e dados
Com os sintomas mapeados, o próximo passo é contextualizar o problema dentro do histórico operacional do equipamento. Essa análise revela padrões que podem não ser óbvios na situação atual.
Consulte registros de manutenção anteriores para identificar intervenções recentes, peças substituídas e problemas similares já enfrentados. Verifique se houve mudanças nos parâmetros operacionais, alterações no processo produtivo ou modificações no ambiente de trabalho.
As perguntas certas direcionam essa investigação. Quando o problema começou a se manifestar? Houve intervenções recentes no equipamento ou sistemas relacionados? Existem padrões sazonais ou cíclicos nas falhas? Que condições operacionais estavam presentes quando o problema surgiu? A documentação técnica do fabricante também fornece informações valiosas sobre tolerâncias operacionais e procedimentos de diagnóstico específicos.
3. Gerar hipóteses de causa
Com base nos dados coletados, formule uma lista de possíveis causas, priorizando-as por probabilidade e facilidade de verificação. Essa etapa exige conhecimento técnico sólido e experiência prática com equipamentos similares.
Liste todas as possibilidades lógicas, desde as mais óbvias até as menos prováveis, usando os 5 porquês da manutenção para aprofundar a análise de causa. Use ferramentas de análise de falhas para organizar sistematicamente as hipóteses em categorias como material, método, máquina, mão de obra e meio ambiente.
4. Testar e implementar correções
Execute testes controlados para validar ou descartar cada hipótese, começando pelas mais prováveis e de menor risco. Cada teste deve ser seguro, documentado e reversível quando possível.
Realize ajustes graduais e meça os resultados após cada intervenção. Evite fazer múltiplas alterações simultâneas, pois isso dificulta a identificação da solução efetiva. Quando uma hipótese for descartada, documente o resultado antes de passar para a próxima.
Quando a causa for identificada, implemente a correção definitiva seguindo procedimentos de segurança. Teste o equipamento em condições normais de operação para confirmar que o problema foi resolvido sem criar novos issues.
5. Validar e documentar
Após implementar a correção, monitore o equipamento por tempo suficiente para confirmar que o problema foi definitivamente resolvido. Essa validação deve incluir verificação de todos os parâmetros operacionais.
Documente detalhadamente todo o processo: sintomas identificados, hipóteses testadas, solução implementada e resultados obtidos. Essa documentação alimenta a base de conhecimento da equipe e acelera futuros troubleshootings em problemas similares. Atualize o histórico do ativo no sistema de gestão de manutenção e compartilhe os aprendizados com a equipe.
Por que o Troubleshooting é crucial no ambiente fabril
Quando uma linha de envase para no meio do turno por causa de um problema não identificado, cada minuto de parada representa perda direta de receita e potencial comprometimento de prazos de entrega. O troubleshooting eficiente é a diferença entre reduzir o downtime em 30 minutos ou ficar horas tentando descobrir o que está errado.
Um diagnóstico preciso e rápido minimiza o tempo de equipamento parado, mantendo a continuidade produtiva. Técnicos treinados em troubleshooting sistemático conseguem identificar problemas em uma fração do tempo necessário para tentativa e erro.
Identificar a causa raiz evita substituições desnecessárias de componentes caros. Sem diagnóstico adequado, é comum trocar peças funcionais na esperança de resolver o problema, gerando custos desnecessários e desperdício de estoque.
Problemas identificados precocemente através de troubleshooting preventivo evitam danos secundários que reduzem drasticamente a vida útil dos equipamentos. Uma vibração anômala detectada e corrigida rapidamente pode evitar danos nos rolamentos, eixos e acoplamentos.
Falhas não diagnosticadas adequadamente podem evoluir para situações de risco, comprometendo a segurança dos operadores. O troubleshooting sistemático identifica condições perigosas antes que se tornem acidentes.
Estratégias para registrar e documentar soluções
A documentação eficaz do troubleshooting transforma experiências individuais em conhecimento organizacional, acelerando futuras resoluções de problemas similares e criando uma base sólida para melhoria contínua.
Desenvolva procedimentos padronizados que incluam campos obrigatórios para sintomas observados, hipóteses testadas, soluções implementadas e resultados obtidos. Essa padronização garante que informações críticas não sejam omitidas e facilita a consulta posterior.
Use checklists estruturados para cada tipo de equipamento, garantindo que aspectos importantes não sejam esquecidos durante o processo de diagnóstico. Crie um banco de dados pesquisável que permita localizar rapidamente soluções para problemas similares.
Além disso, é importante documentar visualmente sempre que possível. Fotografias do antes e depois, vídeos de comportamentos anômalos e diagramas explicativos complementam descrições textuais e tornam a informação mais clara para outros técnicos.
Por fim, vale muito a pena integrar a documentação com sistemas de gestão de manutenção para garantir que informações estejam sempre acessíveis quando necessário - e digitalizadas.
Métricas e resultados do troubleshooting bem executado
Medir a eficácia do troubleshooting através de indicadores de manutenção permite identificar oportunidades de melhoria e demonstrar o valor dessa abordagem sistemática para a organização.
O Tempo Médio para Reparo (MTTR) é o indicador mais direto da eficiência do troubleshooting. Equipes que seguem metodologia estruturada consistentemente apresentam MTTR menor que aquelas que dependem apenas de experiência individual. O Tempo Médio Entre Falhas (MTBF) reflete a qualidade das soluções implementadas.
A taxa de resolução na primeira intervenção mede a precisão do diagnóstico inicial. Técnicos experientes em troubleshooting sistemático conseguem identificar e corrigir problemas sem necessidade de múltiplas tentativas, reduzindo custos e tempo de parada.
Essas métricas principais revelam o impacto real do troubleshooting sistemático:
- MTTR: Tempo médio desde a identificação do problema até sua resolução completa
- MTBF: Intervalo médio entre falhas do mesmo tipo no mesmo equipamento
- Taxa de primeira resolução: Percentual de problemas resolvidos na primeira intervenção
- Redução de reincidência: Diminuição de problemas similares após implementação da solução
- Economia de peças: Redução no consumo de componentes devido a diagnósticos mais precisos
A economia de recursos e peças de reposição é um indicador financeiro direto do valor do troubleshooting. Diagnósticos precisos evitam substituições desnecessárias e reduzem o estoque de segurança necessário, liberando capital para outros investimentos produtivos.
Ultrassônicos versus sensores de vibração tradicionais para detecção de falhas: o que muda
No troubleshooting moderno, a primeira camada de diagnóstico migrou do diagnóstico após a falha pro alerta antes da falha. Aí entram duas tecnologias que costumam ser confundidas mas resolvem problemas diferentes: vibração e ultrassom.
Sensor de vibração tradicional. Captura sinal mecânico em frequências de 0 Hz a ~20 kHz. É a ferramenta certa pra detectar falhas mecânicas com assinatura no domínio da frequência: desbalanceamento, desalinhamento, folga, desgaste de rolamento em estágio médio a avançado, defeitos de engrenagem, problemas de fixação. É robusto, validado por décadas de aplicação industrial e referência da maioria dos modelos de análise modal.
Sensor ultrassônico. Captura sinal acima de 20 kHz, na faixa que o ouvido humano não escuta e que vibração não enxerga. Especializa-se em três classes de falha que vibração detecta tarde ou não detecta: vazamento de ar comprimido e gases (gera onda ultrassônica antes de qualquer assinatura mecânica), falha incipiente de rolamento (atrito metal-metal gera ultrassom semanas antes de aparecer no espectro de vibração) e descarga elétrica parcial em painéis de alta tensão (corona, tracking, arco).
Vantagens de usar os dois. Não é vibração ou ultrassom. A vibração serve para falhas mecânicas estruturadas e o ultrassom para falhas incipientes ou de fluido. Plantas que implementam só uma das duas perdem visibilidade: monitorar só vibração ignora vazamento de ar comprimido (que é a maior fonte de perda de energia em plantas industriais) e falha de lubrificação em estágio inicial. Monitorar só ultrassom perde a maturidade do diagnóstico modal que vibração entrega.
No troubleshooting, a regra é prática: ultrassom indica "tem algo errado e ainda dá tempo", vibração explica "o que está errado e em que estágio".
Como o monitoramento de condição encurta o troubleshooting
Pensa no técnico que chega na linha para investigar uma vibração estranha que o operador relatou. Sem dado contínuo, o ponto de partida é a memória de quem ouviu o ruído primeiro, a anotação no caderno de turno e o histórico de OS dos últimos meses, que na metade dos casos está incompleto.
A investigação começa do zero, com hipótese ampla demais e sem nenhuma referência clara sobre quando o comportamento do ativo mudou.
Agora imagine o mesmo cenário, mas com monitoramento contínuo no ativo desde o início. O técnico abre o histórico e vê que a amplitude de vibração em 1x RPM começou a subir três semanas atrás, que a temperatura do mancal seguiu o mesmo movimento e que o padrão espectral mudou de um jeito compatível com folga mecânica progressiva. A identificação do sintoma e a análise do histórico já vieram resolvidas.
A solução de monitoramento de condição da Tractian faz isso. Coleta vibração, ultrassom e temperatura de forma contínua e constrói esse histórico ativo a ativo. Quando algo sai do padrão, o alerta chega com diagnóstico do modo de falha, progressão e ação recomendada. O troubleshooting deixa de começar do zero e passa a começar do ponto onde o dado já levou a equipe.
Para times pequenos em planta com muitos ativos críticos, isso muda a economia da operação inteira. Em vez de gastar metade do tempo descobrindo o que aconteceu, a equipe usa esse tempo para resolver. E o conhecimento sobre cada ativo deixa de depender de quem estava no turno na hora da falha e passa a viver no histórico, disponível para qualquer técnico que precise consultar amanhã, na semana que vem ou daqui a seis meses.
Se a maioria dos troubleshootings na sua planta ainda começa com "alguém sabe quando isso começou?", o gargalo provavelmente não está na metodologia, mas no dado que falta para alimentá-la.
