

Cada minuto de inatividade no chão de fábrica impacta prazos, metas e o bolso da empresa. E para não perder o controle da operação quando isso acontece, é preciso entender quanto tempo sua equipe realmente leva para resolver o problema de ponta a ponta.
É aqui que entra o MTTR (Mean Time To Resolve), um dos indicadores mais importantes para medir a eficiência da manutenção e a resiliência da operação como um todo.
Mais do que o tempo de reparo em si, o MTTR considera todo o ciclo da falha: desde a detecção até a validação da solução. Ao acompanhar esse dado com precisão, você consegue enxergar gargalos, otimizar respostas e reduzir o impacto das falhas sobre o desempenho industrial.
Neste guia, você vai entender o que realmente está por trás do MTTR, como calculá-lo corretamente e, principalmente, como usá-lo para impulsionar a eficiência da sua equipe técnica.
O que é MTTR (Mean Time To Resolve)?
MTTR (Mean Time To Resolve ou, em português, Tempo Médio para Resolver) é o tempo médio que sua equipe leva para resolver uma falha, do início ao fim.
Ele começa no momento em que o problema é detectado e só termina quando tudo está resolvido, validado e funcionando de novo. Na prática, esse é o indicador que mostra, com precisão, quanto tempo sua operação realmente foi impactada por um incidente.
Mas atenção: MTTR pode significar outras coisas. Na gestão de manutenção e de incidentes, é comum encontrar quatro variações principais:
- Mean Time To Repair (Tempo Médio de Reparo)
- Mean Time To Recovery (Tempo Médio de Recuperação)
- Mean Time To Respond (Tempo Médio de Resposta)
- Mean Time To Resolve (Tempo Médio para Resolver)
Apesar dos nomes parecidos, esses indicadores não são sinônimos. Cada um mede um ponto específico do seu processo de resposta a falhas, e escolher o indicador errado pode distorcer completamente a análise.
Veja uma comparação das principais diferenças entre essas métricas:
| Indicador | O que mede |
|---|---|
| Mean Time To Resolve | Todo o ciclo: da detecção do problema à solução completa e validada |
| Mean Time To Repair | Tempo de execução do reparo em si, "mão na massa" |
| Mean Time To Respond | Tempo até a equipe agir pela primeira vez após a falha |
| Mean Time To Recovery | Tempo até o serviço ser restabelecido (não necessariamente resolvido) |
Cada uma dessas siglas expoe um momento diferente. Uma equipe pode ter um tempo de resposta rápido, mas uma resolução lenta. Por isso, cada uma tem o seu valor na hora de avaliar a confiabilidade da operação. O MTTR como “Mean Time To Resolve” oferece a visão mais completa da resposta da operação quando uma falha ocorre. Ele considera todas as etapas entre a detecção do problema e a validação da solução, incluindo diagnóstico, correção, testes e confirmações finais.
Como Calcular a Fórmula do MTTR
A fórmula do MTTR é simples:
Tempo Total de Resolução ÷ Número de Incidentes = MTTR.
É simples na teoria, mas na prática, o que conta como “tempo de resolução”? E como você define exatamente o que é um “incidente”? O desafio não está na conta em si, mas em definir com clareza o que você está medindo e como está medindo. Só assim os resultados serão consistentes e realmente úteis.
Para evitar distorções, o ideal é calcular o MTTR em quatro etapas:
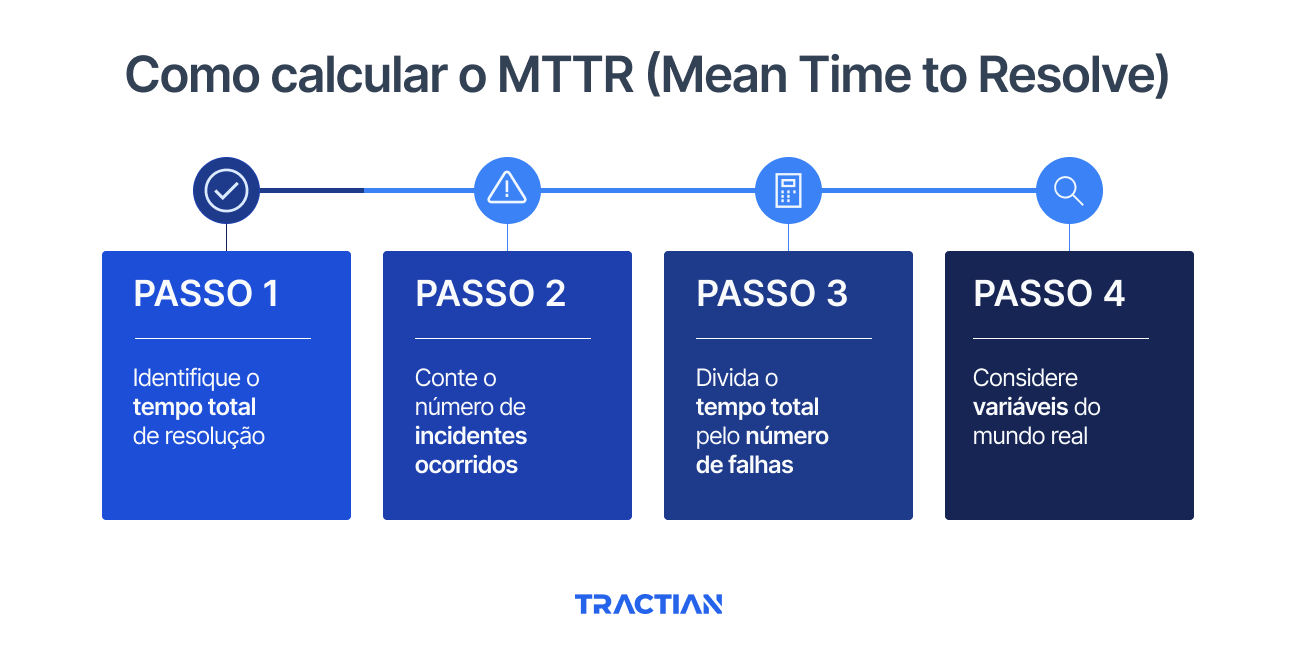
1. Identifique a Duração Total de Resolução
O tempo de resolução começa no momento em que o incidente é detectado e só termina quando ele é completamente solucionado e verificado. Isso inclui diagnóstico, tempo de reparo, tempo de testes, assim como atrasos entre cada uma dessas fases.
Outro ponto importante é decidir se o cálculo será feito em horas de expediente ou em tempo corrido de calendário. Se sua equipe atua apenas em turnos específicos, faz sentido usar o horário comercial. Mas, se o objetivo é medir o impacto real sobre a operação ou os clientes, o tempo corrido dá uma visão mais precisa.
O fundamental é manter a consistência. Independentemente do método escolhido, aplique o mesmo critério para todos os incidentes. Só assim as comparações serão válidas e úteis para a análise.
2. Conte o Número de Incidentes
Antes de calcular o MTTR, é essencial definir o que será considerado um incidente. Um problema recorrente que exige várias intervenções deve ser registrado como um único incidente ou como vários? Questões menores contam da mesma forma que falhas críticas que interrompem a produção?
A forma mais eficiente é classificar os incidentes por gravidade. Uma parada crítica que afeta a linha de produção merece um tratamento diferente de uma falha de software que impacta apenas um usuário.
Independentemente da classificação, registre todos os incidentes de forma consistente, inclusive os reparos rápidos. Na média, aqueles problemas resolvidos em 10 minutos equilibram as falhas complexas que levam dias para serem solucionadas.
3. Divida a Duração pelo Número de Incidentes
Aqui está a aplicação prática da fórmula. Se sua equipe gastou 100 horas para resolver 20 incidentes em um mês, o MTTR será de 5 horas por incidente.
No entanto, essa média pode esconder padrões importantes. Incidentes simples podem ser resolvidos muito mais rápido do que falhas complexas, e a média sozinha não mostra essa diferença.
Por isso, vale analisar a distribuição dos tempos de resolução. Isso revela pontos fortes da equipe e também os diferentes tipos de desafios enfrentados.
Para extrair insights mais acionáveis, considere calcular o MTTR separado por categoria de incidente ou por nível de criticidade. Dessa forma, você entende melhor onde estão os gargalos e pode direcionar melhorias de forma estratégica.
4. Considere as Variáveis do Mundo Real
Diversos fatores podem impactar o cálculo do MTTR e precisam ser levados em conta na interpretação dos resultados.
- Horas de expediente x tempo corrido: a diferença pode alterar bastante os números, especialmente se os incidentes ocorrerem fora do horário normal de trabalho.
- Gravidade dos incidentes: uma queda de rede de 30 minutos não deve ter o mesmo peso que uma falha em equipamento crítico que leva três dias para ser resolvida.
- Sazonalidade: variações de demanda, ciclos de produção, períodos de férias ou até condições climáticas podem influenciar tanto a frequência dos incidentes quanto o tempo de resolução.
- Recursos disponíveis: o tamanho da equipe e a disponibilidade de técnicos impactam diretamente a agilidade da resposta. Um time completo em horário de pico certamente resolve problemas mais rápido do que uma equipe reduzida em um fim de semana.
Em resumo, o MTTR é uma métrica poderosa, mas precisa ser lido dentro do contexto da operação para realmente refletir a realidade da sua equipe.
Desafios Comuns no Uso do MTTR
Mesmo entendendo bem o cálculo, muitas equipes enfrentam dificuldades na aplicação prática do MTTR. Esses desafios não são apenas técnicos e também envolvem também questões organizacionais e de processo.
Medições inconsistentes
Cada membro da equipe pode iniciar ou encerrar a contagem em momentos diferentes. Um técnico pode considerar o problema resolvido assim que o reparo imediato é feito, enquanto outro só encerra após a verificação completa do sistema. É necessário que todos estejam alinhados em uma maneira padronizada de coleta de dados.
O uso de checklists automatizadas dentro de um CMMS melhora a consistência das informações registradas.
Incidentes fora da curva
Falhas muito complexas podem distorcer a média. Um único caso que leve 40 horas para ser resolvido pode comprometer todo o resultado do mês, mesmo que outros 50 incidentes tenham sido solucionados de forma ágil.
É importante se manter atento a esses eventos fora do padrão para não se assustar com um MTTR anormal e perder o controle do que deve, de fato, ser resolvido estruturalmente.
Critérios pouco claros de resolução
Quando exatamente o relógio deve parar? No momento em que o equipamento volta a operar, quando o cliente confirma a satisfação ou apenas após a implementação de medidas preventivas?
Defina muito bem quais são os critérios para estabelecer início e fim do período de resolução da falha. Isso melhora a medição feita pelos técnicos e torna o resultado mais confiável.
Limitações das ferramentas
Sistemas de gestão de incidentes que não capturam todos os dados necessários forçam a equipe a recorrer a controles manuais. Isso gera registros incompletos e métricas pouco confiáveis.
Na hora de escolher um sistema de gestão, esteja atento à forma como a plataforma registra as falhas e as intervenções técnicas. Boas ferramentas são o segredo para um bom resultado.
No entanto, a solução não está apenas em ferramentas “perfeitas”, mas em padrões bem definidos e aplicados com consistência. Documente os critérios de medição, treine a equipe sobre os procedimentos corretos de registro, utilize métodos estruturados como planilhas FMEA e faça auditorias regulares de qualidade dos dados. Só assim o MTTR refletirá a realidade da operação.
Limitações e Armadilhas do MTTR
O MTTR é um indicador poderoso para avaliar a eficiência no gerenciamento de incidentes, mas dar atenção excessiva a essa única métrica pode gerar efeitos contrários ao esperado. Em vez de melhorar os resultados, a pressão pelo tempo pode prejudicar a qualidade da resposta.
Muitas vezes, a busca por reduzir o MTTR leva a soluções incompletas. Um técnico pode aplicar uma correção rápida para recolocar o sistema em operação e alcançar um bom resultado no indicador, mas, se a causa raiz não for tratada, o problema retornará em poucos dias ou semanas.
Outro risco é priorizar a velocidade em detrimento da precisão. Equipes medidas apenas pelo tempo de resolução podem deixar passar causas fundamentais da falha, realizar testes insuficientes ou documentar mal as ações executadas.
Também é importante reconhecer que alguns incidentes, pela sua natureza, exigem mais tempo para serem resolvidos. Falhas complexas, dependência de fornecedores ou casos que pedem conhecimento altamente especializado não podem ser apressados sem comprometer a segurança ou a qualidade do reparo.
Por que o MTTR é Essencial para a Gestão de Incidentes
Quando usado com inteligência e atenção, o MTTR é um indicador crítico de resiliência operacional, com impacto direto tanto nos custos imediatos quanto no desempenho do negócio no longo prazo. Resolver incidentes de forma rápida e eficaz gera efeitos que vão muito além da correção técnica em si.
A correlação com os custos de downtime é o impacto mais evidente. Cada minuto de indisponibilidade de um sistema representa perda de produtividade, oportunidades desperdiçadas e, em muitos casos, prejuízo financeiro. No ambiente industrial, as paradas não planejadas podem trazer consequências severas para a operação e para os resultados.
O efeito também se estende à satisfação do cliente. Quando falhas demoram a ser resolvidas, a confiança nos sistemas e serviços diminui. Usuários esperam ver ação imediata e soluções rápidas, e quando isso não acontece, a credibilidade é comprometida.
Por fim, há ainda um aspecto muitas vezes ignorado: a moral da equipe. Um MTTR constantemente elevado gera frustração, estresse e até esgotamento nos técnicos, reduzindo sua eficiência ao longo do tempo.
Como MTTR e MTBF Funcionam em Conjunto
O MTTR e o MTBF (Mean Time Between Failures, ou Tempo Médio Entre Falhas) são métricas complementares que, juntas, oferecem uma visão completa da disponibilidade e confiabilidade de um sistema.
Enquanto o MTTR mede a eficiência na resolução de falhas, mostrando a rapidez e a eficácia da equipe em restaurar a operação, o MTBF mede a confiabilidade, indicando por quanto tempo o equipamento funciona antes de apresentar um problema.
Um MTTR baixo revela que seus processos de resposta a incidentes estão bem estruturados e que sua equipe tem recursos e habilidades para atuar com agilidade. Já um MTBF alto indica que os programas de manutenção preventiva estão funcionando e que os ativos são intrinsecamente confiáveis.
Essas duas métricas, combinadas, determinam a disponibilidade geral do sistema pela fórmula:
Disponibilidade = MTBF ÷ (MTBF + MTTR)
Essa relação mostra que a disponibilidade pode ser aumentada de duas formas: reduzindo a frequência das falhas (elevar o MTBF) ou acelerando a recuperação quando elas acontecem (reduzir o MTTR). A abordagem de manutenção centrada em confiabilidade (RCM) atua justamente nos dois lados da equação.
Como o CMMS da Tractian Pode Elevar Sua Operação
Reduzir o MTTR não significa apenas trabalhar mais rápido, mas sim trabalhar de forma mais inteligente, com sistemas que apoiam uma resposta eficiente a incidentes. O CMMS certo transforma a forma como sua equipe detecta, diagnostica e resolve problemas, oferecendo visibilidade em tempo real e fluxos de trabalho estruturados que eliminam atrasos e reduzem a confusão.
O problema é que a maioria das equipes de manutenção ainda luta com o MTTR porque as ferramentas disponíveis não oferecem a agilidade e a precisão necessárias. Informações dispersas, processos manuais e sistemas desconectados criam atrito e prolongam desnecessariamente o tempo de resolução.
Com recursos como alertas automáticos, acesso mobile e monitoramento integrado de ativos, o CMMS da Tractian permite identificar falhas mais cedo e responder com muito mais eficiência. Dashboards em tempo real dão visibilidade sobre o status dos incidentes e o desempenho da equipe, enquanto relatórios completos ajudam a identificar padrões e oportunidades de melhoria.
Além disso, a plataforma foi pensada para ser intuitiva. Isso garante que o foco da equipe esteja em resolver os problemas, não em “lutar” com o software. Todas as informações necessárias, como procedimentos, histórico de ativos, dados de peças e contatos, estão disponíveis de imediato, reduzindo o tempo gasto em buscas e aumentando o tempo dedicado à resolução efetiva
A equipe de manutenção se esforça, mas os resultados continuam fracos?
Solicite uma demonstração e descubra como o CMMS da Tractian eleva seus resultados com mais visibilidade, fluxos otimizados e automação inteligente.
