

En una planta de alimentos, un paro de producción no es solo una pérdida de turno. Es un evento que toca múltiples áreas: la producción inmediata, el cumplimiento regulatorio, la confianza del cliente, y el margen operativo que nadie menciona explícitamente en la reunión.
Piensa en lo que sucede cuando una línea de empaque se detiene por 5 horas:
La producción que no salió se mide en cientos de unidades que no llegaron al mercado. Multiplica eso por margen de venta y el número ya duele. Pero el paro no termina cuando la línea arranca. Después viene la limpieza obligatoria (porque la regulación de inocuidad lo exige), la documentación interna, la auditoría del evento, y muy probablemente un cliente que rechaza el retraso en la entrega con crédito o penalidad contractual.
Un paro que en el reporte dura cuatro horas, en el estado de resultados pesa semanas. Y si eso ocurre varias veces al año, el costo acumulado no aparece en el presupuesto de mantenimiento, pero sí desaparece del margen operativo.
El mantenimiento predictivo entra en ese espacio. No para eliminar paros por completo (eso es técnicamente imposible), sino para convertir eventos sorpresa en algo que puedes anticipar.
Costos ocultos de los paros no planeados en líneas de producción de alimentos y bebidas
En una operación industrial en manufactura de alimentos y bebidas, están ampliamente documentados al menos dos tipos de costos ocultos:
Impacto en producción y cumplimiento regulatorio
El costo más directo es la producción perdida: unidades que no se fabricaron, multiplicadas por margen. Pero hay una segunda capa que es regulatoria.
Cuando un auditor inspecciona una planta de alimentos, pregunta cómo anticipas fallas. Si la respuesta es "cuando falla, lo reparamos," eso no es un programa de mantenimiento preventivo. Es mantenimiento reactivo. Lo documenta como hallazgo. La planta entra en lista de seguimiento. Las auditorías se vuelven más frecuentes. El cliente, viendo que hay hallazgos, audita más a menudo también.
El mantenimiento predictivo invierte esa narrativa. Cuando monitoreas vibración y ultrasonido, y tienes datos que muestran que actuaste antes de que algo falle, eso es anticipación. Es documentable. Es lo que la regulación espera ver.
Riesgo de contaminación cruzada y rechazo de auditoría
En la industria alimentaria hay un riesgo que en otros sectores no existe tanto: la contaminación cruzada.
Cuando una línea cae sin aviso, el flujo de producción se interrumpe. Puede haber producto en proceso durante el paro. Puede quedar material en la máquina durante la reparación. Cuando la línea arranca de nuevo, hay incertidumbre: ¿qué lotes fueron afectados? ¿Hay trazabilidad clara? ¿Hay residuos de limpieza o reparación en el producto?
Con paros anticipados es diferente. El operador completa el turno y la línea se detiene de forma ordenada. Hay tiempo para limpieza completa antes de intervención. Cero cruce de contaminación e incertidumbre de trazabilidad.
Eso es lo que un auditor ve en el protocolo: no es solo reactividad, es anticipación que reduce riesgo.
Limitaciones del mantenimiento preventivo tradicional (basado en calendario)
El mantenimiento preventivo es una metodología probada, pero tiene dos limitaciones que se vuelven aparentes después de un tiempo.
Intervenciones innecesarias en equipos no críticos
El calendario no distingue entre equipos críticos y no críticos. Si el plan dice "lubrica cada 4 semanas," el equipo se lubrica cada 4 semanas, sin importar su estado real.
Esto resulta en intervenciones innecesarias. Los rodamientos que están funcionando correctamente reciben lubricante nuevo cuando aún tienen reservas. La sobre lubricación tiene un costo oculto: genera agitación interna en el rodamiento, aumenta temperatura, acelera oxidación del lubricante. Dos semanas después de la lubricación innecesaria, el lubricante está en peor estado que si no lo hubieran tocado.
El resultado es consumo de lubricante más alto de lo necesario, horas técnico dedicadas a tareas innecesarias, y paradójicamente, equipos que se degradan más rápido porque están sobre lubricados.
El enfoque predictivo es diferente: sólo se lubrica cuando los datos dicen que es necesario. Si un rodamiento está saludable en la semana 4, espera a la semana 5 o 6. Si otro rodamiento demuestra degradación en la semana 2, lubrica en la semana 2. Es técnico, basado en evidencia.
El consumo de lubricante baja típicamente 30% a 40%, sin que baje la confiabilidad del equipo. De hecho, mejora, porque el lubricante se aplica exactamente cuando se necesita.
Reacción tardía en activos que sostienen la producción
El calendario tampoco diferencia por impacto operativo. Un rodamiento en un compresor crítico que sostiene toda la línea se inspecciona con la misma frecuencia que un rodamiento en un ventilador secundario.
Esto significa que en los equipos donde más duele una falla, la reacción es tardía. El equipo crítico se inspecciona solo cuando el calendario dice, sin ningún dato que indique si su condición está degradándose o no.
Con monitoreo predictivo, los equipos críticos están bajo observación continua. Vibración, ultrasonido, temperatura. Cuando algo desvía, hay datos para actuar. Los equipos secundarios se inspeccionan periódicamente, sin urgencia. El esfuerzo se concentra donde realmente impacta.
Fundamentos del mantenimiento predictivo: qué monitorear y por qué
El mantenimiento predictivo es una lógica directa: en lugar de intervenir por calendario, interviene por condición. Pero esa lógica solo funciona si sabes qué medir y cómo interpretar lo que ves.
Aquí es donde muchas implementaciones se pierden. Se instalan sensores, se recogen datos, y nadie está seguro de qué hacer con ellos. El dato sin interpretación genera ruido, no decisiones.
Condición vs. calendario: el cambio mental necesario
Cambiar de un modelo a otro requiere adoptar nuevos procesos, pero a su vez que estos procesos estén acompañados de un cambio cultural. Algunos aspectos prácticos que facilitan el cambio implican observar algunos procedimientos con nuevos ojos.
De "lubrico cada 4 semanas" a "lubrico cuando condición lo dice"
El cambio de calendario a condición es más que un cambio de procedimiento. Es un cambio de mentalidad.
Con base en el calendario, el técnico ve la fecha, constata que han pasado 4 semanas desde la última lubricación, y lubrica. No hay interpretación. Hay ejecución.
Con lubricación basada en condición, el técnico ve un sensor que indica que el ultrasonido subió 35%. Compara ese número contra lo que entiende como normal (el baseline). Interpreta que la lubricación está degradándose. Aplica lubricante. Vuelve a medir y confirma que el ultrasonido bajó. Registra todo en el sistema de mantenimiento.
Eso requiere más que un sensor. Requiere baseline claro, protocolos documentados, y un sistema que guarde el histórico de cada intervención. Pero el resultado es eficiencia: menos intervenciones innecesarias donde no importan, y más anticipación donde sí importa.
Cómo priorizar activos según criticidad operativa
No todos los equipos son iguales cuando fallan.
Un compresor que alimenta aire a toda la línea: si falla, la línea se detiene. El impacto es máximo. El ROI de monitorear ese equipo es inmediatamente evidente.
Un ventilador que enfría un área: si falla, hay opciones de contingencia. El impacto es menor. El ROI de monitoreo es más bajo.
Un motor que acciona una bomba de agua crítica: si falla, la línea se detiene. Impacto máximo.
Cuando empiezas con mantenimiento predictivo, la priorización de criticidad define dónde pones los primeros sensores. No en todo. En los 5 a 10 equipos cuya falla cuesta más dinero y desorganiza más la operación. Ahí es donde descubres patrones. Ahí es donde aprendes a interpretar datos.
Señales físicas de degradación: vibración, ultrasonido, temperatura, presión
Un equipo que degrada genera múltiples señales simultáneamente. Vibración. Ultrasonido. Temperatura. En algunos casos, presión. El desafío es entender cuál señal te está diciendo qué, y en qué momento.
Cuál es útil en cada etapa de una falla
Una falla de rodamiento sigue típicamente esta progresión:
Días 1-2: Lubricación comienza a degradarse. Hay microcontactos entre las superficies. Vibración: sin cambio notable. Ultrasonido: sube 20% a 40% del nivel normal. Temperatura: sin cambio. En este punto, lubricación resuelve el problema.
Días 3-4: Los microcontactos han comenzado a rayar la pista. Vibración: empieza a subir (10% a 20% del nivel normal). Ultrasonido: sigue muy alto (60% a 100% arriba del normal). Temperatura: sube 5 a 10 °C. Aquí tienes una decisión: lubricar o preparar un cambio de rodamiento.
Días 5-7: El daño en la pista está establecido. Vibración: sube 30% a 50%. Los patrones empiezan a ser predecibles. Ultrasonido: muy alto, con picos claros. Temperatura: sube 15 a 25 °C. En este punto es casi seguro que necesitas cambiar el rodamiento.
Días 8-10: Daño severo. Vibración: muy alta (50% arriba del normal), spikes claros con cada rotación. Ultrasonido: patrones altamente estructurados. Temperatura: muy elevada. Aquí se trata de una emergencia.
Sin sensores, típicamente te enteras en los días 6 o 7. Con monitoreo desde el día 1, actúas en el día 1 o 2. La diferencia entre estos escenarios es enorme: lubricación vs. cambio de rodamiento, turno normal vs. paro emergencia.
Combinación de señales para diagnóstico confiable
Un solo sensor puede fallar o generar una falsa alarma. Cuando monitoreas múltiples señales simultáneamente, reduces incertidumbre:
- Si la vibración sube pero el ultrasonido no, probablemente estés frente a un desbalance, no a un problema de lubricación. La acción es diferente: rebalancear, no lubricar.
- Si el ultrasonido sube pero la vibración y temperatura están estables, probablemente hay fricción incipiente. La lubricación es la solución.
- Si la vibración y la temperatura suben juntas pero el ultrasonido no, puede ser un problema eléctrico o de alineación. Necesitas un diagnóstico más profundo.
- Si los tres parámetros suben simultáneamente, la falla está avanzada. No hay tiempo para soluciones graduales; el cambio de componente es necesario.
La lógica de decisión con múltiples señales es más robusta. Menos falsas alarmas. Diagnóstico más confiable. El técnico actúa con certeza, no con incertidumbre.
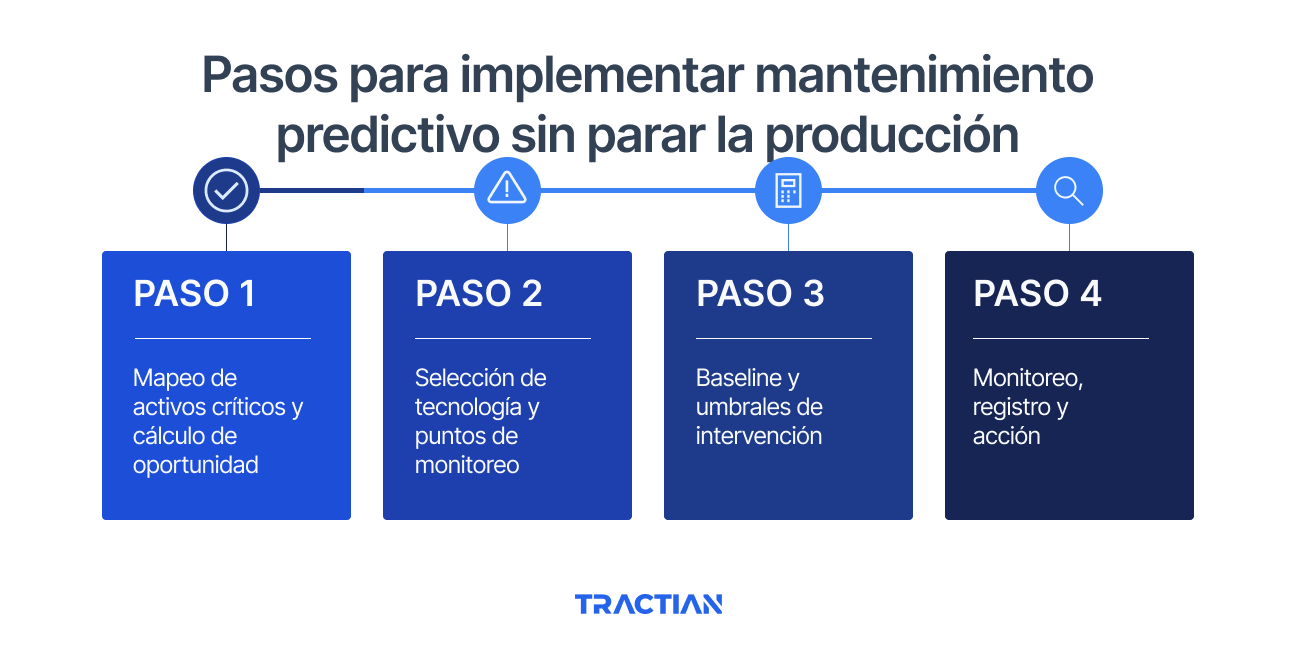
Pasos para implementar mantenimiento predictivo sin parar la producción
La teoría del mantenimiento predictivo es clara. La implementación es donde la mayoría de los proyectos se atascan. No por falta de tecnología, sino por falta de estructura.
Aquí hay un riesgo común: instalar sensores sin baseline claro, sin criterios de alerta definidos, sin capacitación del equipo. El resultado son datos sin interpretación, falsas alarmas, y finalmente, sensores que nadie mira porque nadie confía en lo que dicen.
La implementación correcta es gradual. Comienza en 3 a 5 equipos de máximo riesgo. Ahí aprendes. Ahí defines protocolos. Luego escalas.
Paso 1: Mapeo de activos críticos y cálculo de oportunidad (Semana 1-2)
El primer paso no es comprar sensores. Es entender dónde duele más una falla.
Sienta a tu equipo de operaciones y mantenimiento. Lista cada equipo: compresores, bombas, motores, reductores, ventiladores. Para cada uno, responde tres preguntas:
¿Cuántas veces falló en el último año? ¿Cuántas horas se detiene la línea por falla? ¿Cuál es el costo aproximado por hora de paro en tu operación?
Con esos tres números puedes hacer un cálculo simple:
Paros por año × Horas por paro × Costo por hora = Riesgo anual por equipo
Con ese número en la mano, comparas contra el costo de implementar monitoreo en ese equipo (sensor, software, instalación, capacitación). Si el riesgo anual es significativamente mayor que el costo de implementación, tienes caso de negocio claro.
Un equipo crítico (compresor, bomba principal) que falla regularmente tendrá un riesgo anual que justifica monitoreo rápidamente. Un equipo secundario (ventilador de apoyo) probablemente no.
Los primeros sensores van en los 5 a 10 equipos donde ese cálculo es más favorable. Ahí es donde verás ROI más rápido. Ahí es donde validarás el enfoque.
Documenta este cálculo. No es solo para justificar inversión. Es tu baseline de éxito. Al final del piloto, comparas:
- ¿Cuántos paros evitamos?
- ¿Cuánto dinero ahorramos?
- ¿Confirmamos el modelo?
Paso 2: Selección de tecnología y puntos de monitoreo (Semana 2-3)
Una vez que sabes qué equipos necesitan sensores, viene la decisión técnica: ¿qué sensor, dónde lo pones?
Un compresor en zona de lavado: IP69K + 2-en-1 (vibración + ultrasonido). El ambiente es mojado, la lubricación es continua, necesitas ver la fricción temprano.
Una bomba de agua en circuito cerrado: IP69K estándar (vibración). El riesgo es la cavitación, no la lubricación. El ambiente es semi-seco.
Un molino de granos en ambiente seco: acelerómetro estándar (IP67). El riesgo es el desbalance, no la lubricación.
Hay un detalle técnico que importa: ¿sensor clip-on o integrado?
Los clip-on se instalan en 10 minutos, magnéticamente, sin parar máquina. Útil para piloto, para validar antes de invertir en instalación permanente.
Los integrados se montan de forma fija, mejor para operación a largo plazo, pero requieren intervención más profunda durante la instalación.
Para el piloto, usa clip-on. Te permite mover sensores, probar en diferentes equipos, aprender sin comprometer la instalación.
Paso 3: Baseline y umbrales de intervención (Semana 3-4)
Un baseline es la firma de vibración y ultrasonido de un equipo cuando está saludable.
Sin baseline, un número de sensor no significa nada. La vibración de 5 mm/s puede ser normal para una bomba de 50 HP, pero es alarma en un ventilador pequeño. El ultrasonido de 60 dB puede ser normal en un compresor, pero anómalo en un rodamiento seco.
Cada máquina es diferente. Incluso dos compresoras idénticas pueden tener baselines diferentes según la carga habitual, la temperatura ambiental, la historia de mantenimiento.
Para establecer el baseline: deja el equipo operando en condición normal durante 1 a 2 semanas. Recolecta datos. Promedia. Eso es tu referencia. Los baselines posteriores se comparan contra eso.
Los umbrales de intervención son bandas de decisión. Por ejemplo:
Si el ultrasonido sube 20% arriba de baseline: la condición está degradada, monitorea con frecuencia aumentada. Si el ultrasonido sube 50% arriba de baseline: la intervención es cercana, prepara la lubricación. Si la vibración sube 30% arriba de baseline: el cambio de rodamiento probablemente es necesario.
Estos umbrales no son estándar. Se ajustan según la experiencia y según lo que cada equipo te enseña.
Paso 4: Monitoreo, registro y acción (Semana 5+)
Aquí es donde los datos se convierten en decisiones.
El técnico mide. Ve que el ultrasonido subió 35%. Consulta el baseline. Interpreta que la lubricación está degradándose. Lubrica. Mide de nuevo. Confirma que el ultrasonido bajó.
Luego registra en el CMMS (sistema de mantenimiento): fecha, equipo, lectura anterior, lectura nueva, acción tomada, resultado. Sin registro, pierdes el aprendizaje. La próxima persona que toca ese equipo empieza desde cero.
Con registro, el histórico te enseña patrones. "Este compresor necesita lubricación cada 5 semanas en verano, cada 7 semanas en invierno." "Este rodamiento subió el ultrasonido después de cambio de producto." "Cuando la vibración sube pero el ultrasonido no, siempre fue desbalance, nunca lubricación."
Ese aprendizaje es el verdadero valor del mantenimiento predictivo. No es el sensor. Es la memoria técnica que construyes con los datos.
Tecnologías clave para mantenimiento predictivo en alimentos
El mantenimiento predictivo requiere sensores. Pero no todos los sensores ven lo mismo. Entender qué ve cada uno es crítico para tomar decisiones correctas.
Sensores de vibración: cuándo son suficientes y cuándo no
Un sensor de vibración mide el desplazamiento mecánico. Detecta bien cuando los defectos ya tienen amplitud: desbalanceo, desalineación, soltura mecánica, rodillo fracturado.
Normalmente opera en el rango 0-20 kHz (baja frecuencia). Es sensible a los movimientos visibles, a los impactos estructurales.
La limitación es clara: en etapas tempranas de una falla, no hay movimiento visible aún. Hay solo fricción. La vibración baja no la ve. Así que cuando la vibración empieza a subir, la falla ya tiene 4 a 5 días de edad. Tu ventana de intervención es estrecha.
En ambientes mojados hay otra limitación técnica. Un sensor estándar envejece más rápido en zonas de lavado frecuente. Un IP69K (washdown-rated) está diseñado para esos ambientes y tiene mayor durabilidad. La diferencia de costo entre ambos es relevante, así como la frecuencia de reemplazo y revalidación.
La vibración es suficiente cuando tu riesgo principal es un defecto estructural desarrollado. En alimentos, donde la lubricación es crítica, necesitas más.
Ultrasonido industrial: anticipación de fricción antes de daño
Un sensor ultrasónico mide la energía acústica en altas frecuencias (40-100 kHz). Detecta lo que la vibración baja no ve: la fricción, la turbulencia, los impactos microscópicos.
Cuando la lubricación comienza a degradarse, hay microcontactos entre las superficies. Esos contactos generan la energía acústica en altas frecuencias. Un sensor ultrasónico la capta. La vibración baja aún no la ve.
La ventaja es el tiempo. El ultrasonido sube días antes que la vibración. Esa es una ventana amplia para actuar. Puedes lubricar y detener la falla en etapa incipiente. O si necesitas cambiar el componente, tienes días para planificar, no horas para improvisar.
En las bombas, el ultrasonido detecta la cavitación (implosión de burbujas) de forma muy clara. En los compresores, ve la presencia de agua en el circuito de aire. En los rodamientos sometidos a carga variable, ve los cambios de régimen de lubricación antes que otros sensores.
En ambientes mojados de alimentos, la combinación IP69K + ultrasonido es la que más impacto tiene. Ves anticipadamente, y el sensor sobrevive al ambiente.
Temperatura e integración multi-señal
La temperatura sube cuando hay fricción severa o cuando hay resistencia eléctrica anómala. Es útil, pero típicamente es la tercera o cuarta señal que ves en una progresión de falla.
Cuando la temperatura sube, la falla ya tiene varios días. La vibración y el ultrasonido la vieron antes.
Donde la temperatura es valiosa es como confirmación. Si el ultrasonido sube pero la temperatura no, probablemente es fricción incipiente. Si el ultrasonido y la temperatura suben juntas, la falla está avanzada.
La lógica de decisión con 3 sensores (vibración, ultrasonido, temperatura) es más robusta que con uno. Menos falsas alarmas. Diagnóstico más seguro.
Tienes razón. No terminé la 3. Reescribo completa:
Obstáculos comunes y cómo evitarlos
Implementar mantenimiento predictivo no es técnicamente difícil. Los sensores existen. El software existe. La dificultad es organizacional: alinear personas, cambiar hábitos, mantener disciplina cuando los resultados no son instantáneos.
Aquí están los obstáculos que aparecen en casi toda implementación. Reconocerlos adelantado ayuda a evitarlos.
"Tenemos muchos datos pero no sabemos qué hacer con ellos"
Este es el obstáculo más común. El equipo instala sensores, recolecta datos durante semanas, y después alguien pregunta: ¿ahora qué?
El problema no es la falta de datos. Es la falta de baseline claro y criterios de decisión definidos.
Un sensor sin baseline es solo una lectura. El ultrasonido registra un valor. ¿Eso es bueno o malo? Sin saber cuál es el nivel normal en ese equipo, la lectura no significa nada. Con baseline, puedes comparar y saber si representa una desviación importante.
La solución es disciplina en el baseline. Antes de hacer cualquier otro análisis, dedica 1 a 2 semanas a recolectar datos estables en cada equipo. Promedia. Documenta. Eso es tu referencia.
La segunda pieza es capacitación técnica. El dato solo, sin interpretación, genera falsas alarmas. Un técnico necesita entender: ¿cuándo el ultrasonido que sube significa lubricación deficiente vs. defecto incipiente vs. cavitación?
Sin esa interpretación, toda alerta es una alarma falsa. El técnico deja de confiar. Los sensores se ignoran.
"Implementamos sensores pero técnicos siguen lubricando por calendario"
Aquí el obstáculo es organizacional, no técnico.
Los técnicos llevan años lubricando por calendario. Es rutina. Es hábito. Aunque haya un sensor diciendo "no lubricar aún," el técnico lubrica porque "toca."
La razón es que nadie alineó al equipo. Nadie dijo: "A partir de hoy, el sensor decide, no el calendario." Nadie definió responsabilidad ni consecuencias.
La solución es cambio de instrucciones, alineación con el CMMS, y casos visibles de éxito.
Primero: reescribe el procedimiento. En lugar de "lubrica cada 4 semanas," dice "lubrica cuando el ultrasonido sube un nivel significativo arriba de baseline. Consulta el dashboard antes de intervenir."
Segundo: asegúrate de que el dashboard está visible. En piso de planta. Fácil de leer. El técnico ve el dato, no tiene que buscar en una app en la oficina.
Tercero: documenta los casos donde la anticipación funcionó. "Compresor: ultrasonido mostró degradación. Lubricamos. Evitamos paro inesperado el lunes." Muestra eso al equipo. Demuestra que el sensor funciona.
Cuarto: alinea al supervisor. Es quien revisa si el técnico actuó por datos o por calendario. Sin supervisión alineada, el cambio no ocurre.
"El ROI no se ve en el primer mes"
Implementación rápida de mantenimiento predictivo es 90 días. No esperes resultados en 30 días.
Los resultados no aparecen como un número grande en la primera semana. Aparecen gradualmente: menos paros sorpresa aquí, una intervención anticipada allá, un rodamiento que duró más porque se lubricó en tiempo.
Donde la mayoría de los proyectos falla es en la métrica de éxito. Si esperas "menos sensores activos" como métrica, nunca lo verás. Eso no es lo que el mantenimiento predictivo entrega.
La métrica correcta es: "menos paros no planeados en equipos monitoreados." No es glamorosa, pero es real.
Otra métrica es: "menos rodamientos cambiados por desgaste, porque los vemos degradar y actuamos a tiempo." Eso ahorra dinero en capex de reemplazo.
Otra más: "consumo de lubricante más eficiente, porque lubricamos cuando es necesario, no cada X días."
El dinero ahorrado no aparece como un ingreso. Aparece como "gastos que no ocurrieron." Es más difícil de comunicar, pero es igual de real.
La solución es documentar desde el inicio. Antes del piloto, lista cuántos paros ocurrieron en equipos monitoreados en los últimos 12 meses. Al final del piloto (90 días), compara. Ese es el ROI.
Mantenimiento predictivo como estándar operativo
El mantenimiento predictivo en plantas de alimentos no es una tecnología futurista. Es una metodología que existe, funciona, y está al alcance de cualquier operación.
De "si" a "cuándo": la mentalidad correcta
La pregunta ya no es "¿implementamos mantenimiento predictivo?" Es "¿cuándo empezamos?"
Los primeros 90 días no son inversión especulativa. Son validación. Tomas 5 equipos de riesgo alto, instalas sensores, aprendes, y decides si escalas.
Impacto regulatorio: auditoría ve anticipación, no solo reactividad
Cuando un auditor pregunta cómo anticipas fallas, la respuesta basada en datos es muy diferente de la respuesta basada en calendario.
"Monitoreamos vibración y ultrasonido. Cuando la condición degrada, actuamos antes de que falle. Documentamos cada intervención."
Eso es anticipación. Eso es lo que la regulación espera.
El mejor turno es el que no se detuvo
El mantenimiento predictivo en la industria alimenticia no es una apuesta. Es una validación de 90 días.
Cinco equipos críticos. Sensores que se instalan sin parar la línea. Datos que empiezan a llegar el mismo día. Y una pregunta simple al final del piloto: ¿cuántos paros no ocurrieron que antes habrían ocurrido?
La respuesta no es teórica. Es medible. Rodamientos que se lubricaron antes de dañarse. Compresores que se intervinieron en ventana programada. Líneas que no se detuvieron a mitad del turno porque alguien vio la degradación a tiempo.
Cuando un auditor pregunta cómo anticipas fallas, la respuesta cambia. No es "cuando falla, lo reparamos". Es: monitoreamos condición de forma continua, actuamos cuando los datos lo indican y documentamos cada intervención. Eso es anticipación. Eso es lo que la regulación espera ver.
El costo de no implementar no aparece como línea en el presupuesto. Aparece como los paros que siguen ocurriendo, los correctivos de emergencia que siguen costando de más, los lotes que se siguen comprometiendo cuando un equipo falla sin aviso. Es dinero que no se ve salir, pero que tampoco llega al margen.
La pregunta dejó de ser si el mantenimiento predictivo funciona en plantas de alimentos. Funciona. Está documentado. Se implementa sin detener la producción.
La pregunta es cuántos turnos más van a pasar antes de que el dato llegue antes que la falla.
