

O chão de fábrica é um ambiente de pressão constante. São muitos ativos diferentes, equipes com prioridades diferentes e pouco espaço para erro. A equipe de manutenção não consegue dar a mesma atenção para todos os ativos e, muitas vezes, sinais de falha podem se perder no meio do ruído.
A equipe até tem o conhecimento necessário para identificar anomalias, mas falta uma estrutura clara e repetível de ciclo. Um loop claro que começa na identificação do sintoma e acaba com uma resolução do problema, sem retrabalhos ou corretivas em cascata.
Não é preciso ter uma equipe de centenas de pessoas ou um orçamento enorme disponível. O que resolve essa lacuna é a capacidade de gerir bem o ciclo de vida da falha, do primeiro sinal até o fechamento da OS e o aprendizado que ela deixa.
Neste artigo, vamos destrinchar a melhor maneira de gerir o ciclo de vida da falha com um fluxo que funciona na rotina industrial, mesmo com time enxuto e múltiplas prioridades concorrendo ao mesmo tempo.
Leia também:
- Como o ultrassom evita o custo invisível na manutenção industrial
- Como os alarmes padronizados ajudam na gestão da manutenção
- Da anomalia à causa raiz: passo a passo para reduzir retrabalho
O que é ciclo de vida da falha
Quando a gente fala em “falha”, é comum imaginar o fim do filme: o ativo parado, a produção travada, alguém correndo para conter o dano. Só que a falha tem toda uma trajetória antes de causar dano real.
Ela nasce como um desvio pequeno, muitas vezes invisível a olho nu, evolui para um comportamento anormal, vira sintoma recorrente e, se nada mudar, culmina em quebra, perda de performance ou risco de segurança.
O ciclo de vida da falha é a jornada completa, do primeiro sinal até a resolução e o aprendizado. Ele organiza a rotina para que a manutenção trate falha como processo, não como evento.
Na gestão, isso importa por um motivo simples: quanto mais cedo você identifica o problema com dados e contexto, mais opções você tem. Opções de planejar parada, de combinar a intervenção com uma janela de produção, de preparar recursos, de evitar uma corretiva emergencial. Quando a falha já virou ocorrência crítica, você perde margem de decisão e fica com uma única opção, que é conter o dano já causado.
Uma forma útil de olhar para isso é separar três camadas que se misturam no dia a dia:
- Sintoma (o que aparece): vibração saindo do padrão, temperatura subindo, ruído diferente, consumo elétrico alterando, perda de eficiência, alarmes intermitentes.
- Mecanismo de falha (o que está acontecendo): desalinhamento, desbalanceamento, folga mecânica, lubrificação deficiente, cavitação, desgaste de rolamento, problema elétrico, ressonância.
- Causa raiz (por que aconteceu): instalação fora de padrão, condição operacional mudando, falha de lubrificação por procedimento, contaminação, especificação inadequada, prática operacional, qualidade de componente, erro de montagem.
O ciclo de vida existe para impedir o erro comum de agir no sintoma sem atacar o mecanismo ou a causa. É aí que nasce a “corretiva em cascata”. O problema é resolvido hoje, mas volta amanhã. A equipe troca a peça, mas não corrige o desalinhamento. Lubrifica, mas não checa contaminação.
Gerir bem o ciclo significa ter um loop repetível que estrutura o trabalho desde o primeiro sintoma da falha, para impedir que ela cause estragos maiores.
O loop que funciona no chão de fábrica
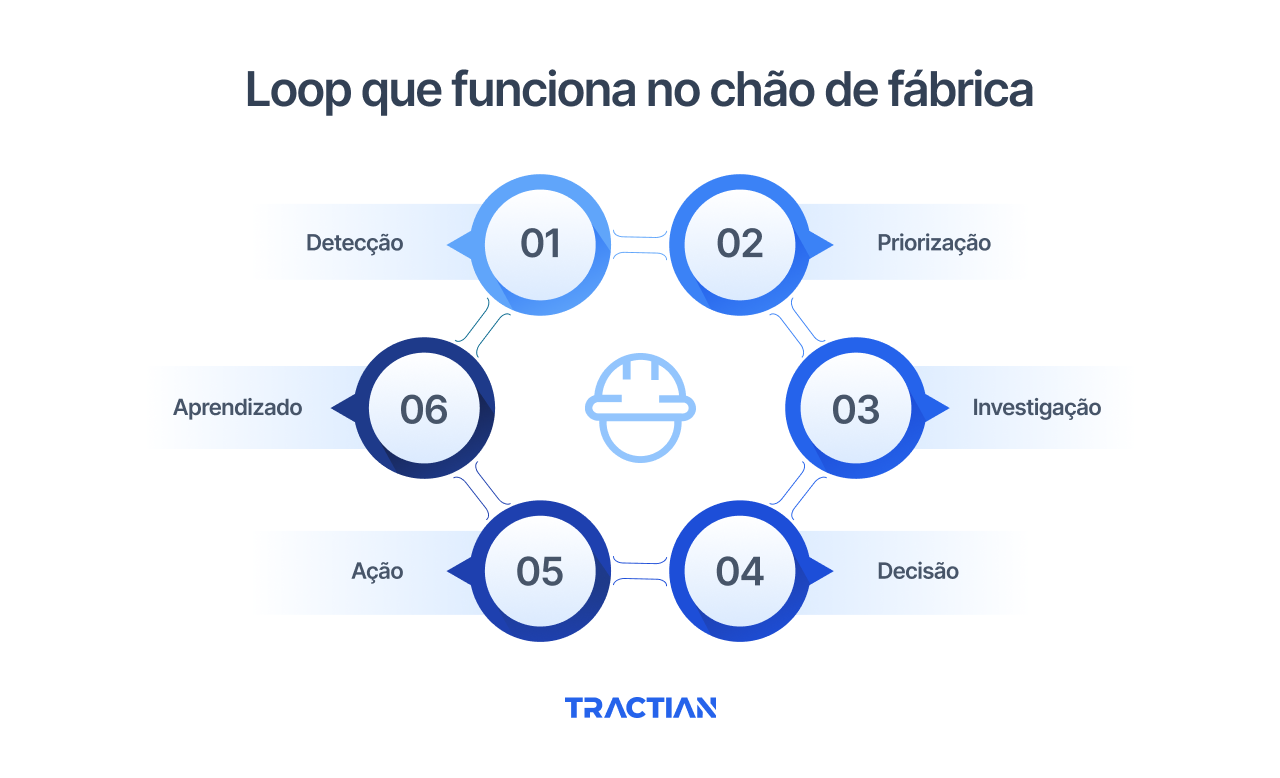
1. Detecção
Tudo começa na detecção do problema. É a etapa mais importante, porque a qualidade do que vem depois depende diretamente de como a ela é feita.
Detectar, nesse caso, é identificar uma anomalia que merece atenção e, principalmente, saber distinguir o que é ruído do que é sinal relevante. Isso pode vir de dados de vibração, termografia, ultrassom, análise de corrente, dados do supervisório ou feedback do operador. O canal muda, mas a lógica é sempre de transformar variação em evidência.
Uma anomalia acionável tem características claras: ela representa uma tendência de piora, uma mudança de padrão em relação ao comportamento histórico do ativo ou um comportamento fora do normal para aquela condição operacional.
Um pico isolado de vibração pode ser irrelevante. O mesmo pico que se repete a cada ciclo com amplitude crescente pode preocupar.
2. Priorização
Depois de detectar, a pergunta é: isso entra na fila ou vai para o topo da prioridade?
A resposta depende de dois fatores combinados: a criticidade do ativo e a severidade do sinal. Um ativo crítico com um desvio leve pode não exigir intervenção imediata. Por outro lado, um ativo de suporte com um desvio agressivo e progressivo pode precisar de atenção antes do que parece.
Sem uma regra clara de priorização, a decisão fica na mão de quem está disponível ou de quem grita mais alto. E isso gera desentendimentos e erros por agir de forma pouco estratégica. A equipe começa a trabalhar por urgência percebida, e não por risco real.
Uma boa priorização leva em conta o impacto da falha na produção, o tempo estimado até a falha se tornar crítica e a disponibilidade de janela para intervenção. Não precisa ser complexo, mas precisa ser consistente.
3. Investigação
Com a anomalia identificada e priorizada, o próximo passo é entender mais a fundo o que está acontecendo. E isso passa por um conjunto mínimo de perguntas que precisam ser respondidas antes de qualquer decisão.
O que mudou? Quando essa mudança começou? Em que condição operacional o desvio aparece? O ativo passou por alguma intervenção recente que pode ter alterado seu comportamento?
Essas perguntas podem parecer óbvias, mas são sistematicamente puladas em ambientes de alta pressão. A investigação sem contexto leva o técnico a agir sobre o sintoma mais visível, não sobre a causa real. E o resultado, quase sempre, é retrabalho.
4. Decisão
Com a investigação feita, chegamos ao momento mais crítico do ciclo: decidir entre intervir agora ou planejar uma janela.
A intervenção imediata faz sentido quando o risco de falha catastrófica é alto e a continuidade da operação não pode ser comprometida. O planejamento de janela faz sentido quando o desvio está controlado, a progressão é lenta e há condições de preparar a intervenção com mais qualidade e menos custo.
O erro mais comum aqui é deixar o planejamento de lado pela pressão do momento e intervir de forma não preparada. Isso gera mais tempo de parada, maior custo e, frequentemente, uma intervenção incompleta que vai exigir retorno em breve.
Nessa etapa, o registro é essencial. A decisão precisa ser documentada, com o racional que levou a ela. Isso é o que permite aprender e melhorar o critério ao longo do tempo.
5. Ação
A intervenção precisa de dois cuidados fundamentais.
O primeiro é evitar a ação paliativa que resolve o sintoma mas deixa a causa intacta. Trocar um rolamento desgastado sem investigar por que ele desgastou antes do prazo é um exemplo clássico. A peça nova vai, mas o problema volta. E quando volta, já é mais caro.
O segundo cuidado é o registro. Toda intervenção precisa deixar um rastro do que foi feito, o que foi encontrado, quais peças foram usadas e, principalmente, qual foi o resultado observado logo depois. Esse registro é a matéria-prima do aprendizado e da melhoria contínua.
6. Aprendizado
Essa é a etapa mais negligenciada e, ao mesmo tempo, a mais estratégica do ciclo.
Toda falha ensina algo. Às vezes sobre o ativo, às vezes sobre o processo, às vezes sobre a rotina de manutenção que deixou de detectar o desvio a tempo.
Pode até ser que, no ritmo normal, o técnico aprenda algo ao fim de uma intervenção. Mas esse aprendizado fica guardado na cabeça do técnico que estava lá, ou ele se incorpora de verdade ao processo?
Depois de cada intervenção relevante, vale fazer perguntas simples:
- O que essa falha revelou sobre o comportamento desse ativo?
- O padrão de checagem atual era adequado?
- A priorização foi correta?
- O que pode ser ajustado para que, na próxima vez, o ciclo seja percorrido com mais agilidade?
As respostas precisam atualizar os critérios de priorização, os intervalos de inspeção e os pontos de atenção nos ativos de mesma família. Quando isso acontece, a equipe resolve mais falhas e evolui junto com a operação.
Onde o ciclo quebra no chão de fábrica
Conhecer as etapas do ciclo é necessário, mas não suficiente. Quando o time vai colocar essa estrutura em prática, existem pontos de ruptura recorrentes que fazem o loop travar ou regredir.
Veja alguns deles:
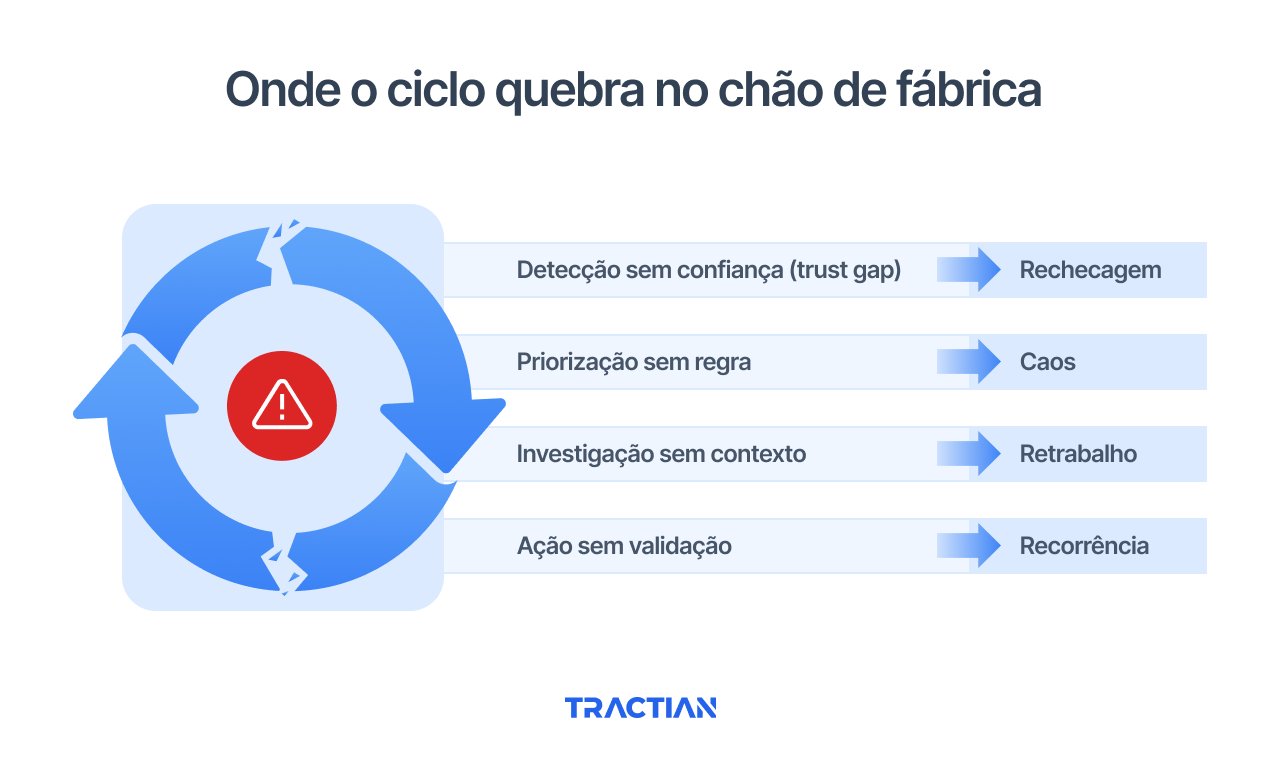
Detecção sem confiança
Quando o sinal detectado é questionável, o técnico faz o que qualquer pessoa faz diante da incerteza: reconfirma. Vai até o ativo, mede de novo, consulta um colega. O tempo gasto nesse loop de validação é tempo que não existe em um ambiente de alta demanda.
A detecção precisa ser confiável para que o ciclo avance sem atrito. Para isso, tecnologias de monitoramento de condição são um grande aliado, já que acompanham o comportamento do ativo de forma contínua. Elas identificam anomalias sem abrir espaço para dúvida, com detalhamento do que mudou e por que aquilo pode preocupar.
Priorização sem regra
Sem critérios claros, a fila de manutenção se organiza por pressão, não por risco. O ativo que o gerente de produção considera mais urgente vai na frente, enquanto o que está silenciosamente se deteriorando fica para depois.
Quando a ordem de priorização não é seguida, o problema se acumula até que, quando a bomba explode, é impossível apontar apenas um responsável.
Investigação sem contexto
A investigação feita sem histórico do ativo, sem conhecimento das condições operacionais recentes e sem acesso a dados comparativos leva a conclusões superficiais.
A intervenção até pode ser executada, mas sem atacar a causa real. Depois, é só questão de tempo até reaparecer e virar retrabalho.
Ação sem validação
Intervir e não validar o resultado é um problema. Sem a confirmação de que a ação resolveu o desvio, o ciclo fica tecnicamente encerrado, mas aberto na realidade da operação. Se a recorrência acontece, a equipe é pega de surpresa outra vez e tem que recomeçar o trabalho.
Como reduzir a fricção no ciclo sem aumentar o time
Um dos maiores equívocos na gestão de manutenção é achar que mais cobertura exige mais gente. Na maioria dos casos, o que falta é só direcionamento.
O primeiro passo para reduzir fricção é repensar a lógica das rotas de inspeção. Em um modelo tradicional, o técnico percorre todos os ativos com a mesma frequência, independentemente da condição de cada um. O problema é que, na maior parte do tempo, ele está inspecionando máquinas saudáveis. Isso consome horas que poderiam ser dedicadas a ativos que realmente demandam atenção.
A lógica mais eficiente inverte essa equação: o técnico vai até o ativo quando há uma demanda real gerada por dados captados no monitoramento contínuo, não no calendário.
Isso não significa abandono da preventiva. É uma estratégia de inteligência na alocação do esforço. Máquinas estáveis, sem desvio identificado, podem ter menor frequência de visita. Máquinas com comportamento em mudança passam a receber atenção proporcional ao risco que representam.
O segundo fator é a consistência dos dados em diferentes condições operacionais. Um sistema que gera alertas sem considerar que o ativo opera em regimes diferentes ao longo do dia vai produzir falsos positivos com frequência.
O falso positivo desgasta a confiança no processo e faz o técnico começar a ignorar os sinais. Dados confiáveis, ajustados ao contexto operacional real, são a base de um ciclo que funciona sem atrito.
Como a Tractian se encaixa no loop do seu chão de fábrica
Gerir o ciclo de vida da falha com consistência exige que cada etapa do loop tenha suporte adequado. E é justamente aí que a tecnologia deixa de ser um acessório e passa a ser estrutural.
A solução de monitoramento de condição da Tractian foi desenvolvida para sustentar o ciclo desde a detecção até o aprendizado. O monitoramento contínuo elimina as lacunas entre inspeções manuais, garantindo que desvios sejam identificados no momento em que começam a se desenvolver, não quando já causaram impacto.
O autodiagnóstico por inteligência artificial processa os dados em tempo real e gera alertas com contexto, com o comportamento histórico do ativo e com a comparação com equipamentos similares. Isso reduz o ruído e aumenta a confiança no sinal.
A priorização passa a ser orientada pela criticidade do ativo e pela severidade do desvio detectado de maneira automatizada. O técnico recebe não só o alerta, como a indicação clara de onde agir e o quê verificar, com rotas organizadas por demanda real.
A equipe percorre as etapas do ciclo de vida da falha com menos atrito, menos retrabalho e mais precisão, concentrando esforço onde ele tem impacto real.
Pensa nas últimas falhas da sua planta. Quantas viraram aprendizado de verdade, e quantas só viraram retrabalho? Se a segunda opção ganhou, é hora de repensar.
