

Em muitas plantas que investiram em monitoramento de condição nos últimos anos, os sensores estão instalados, a plataforma roda, o diagnóstico até funciona, mas a abertura da ordem de serviço continua dependendo de alguém imprimir um relatório e levar até o supervisor de turno para discutir prioridade. O alerta acaba virando chamado informal e precisa entrar no fim da fila de prioridades.
Esse hiato entre o que o sensor identifica e o que a equipe executa é onde grande parte dos programas de manutenção baseada em condição ainda perde dinheiro.
A causa raiz raramente está no diagnóstico, que costuma ser feito de forma até razoável. Está na ausência de um fluxo desenhado para transformar o alerta em ação rastreável dentro do CMMS, com responsável definido, prazo de resposta e fechamento técnico para alimentar o modelo de monitoramento.
Este artigo trata do que precisa estar amarrado para que isso aconteça em escala, e como centralizar condição, decisão e execução no mesmo ambiente tem se tornado um requisito operacional.
Leia também:
- Sensores de vibração sem fio: o que avaliar antes de escolher
- IA na manutenção industrial: o que realmente faz e qual escolher
- Sensor de ultrassom industrial e vibração: por que usar ambos?
O que define um fluxo de alerta à execução que funciona
Quando o monitoramento de condição é tratado como projeto de TI separado da manutenção, o desenho do fluxo tende a parar na entrega do dashboard.
O time da preditiva analisa o alerta, escreve um relatório e encaminha. A partir daí, a execução depende de quem está disponível, de qual é a prioridade percebida no momento e de como o coordenador de planejamento decide encaixar a tarefa na rotina da semana.
Esse desenho funciona enquanto o número de pontos monitorados é pequeno. Mas quando o programa cresce para algumas centenas de sensores, o gargalo passa a ser de governança.
Quatro fatores precisam estar estabelecidos antes de escalar, para que o programa não fique refém de heroísmo individual:
1. Definição de responsável por alerta e nível de criticidade
Cada ativo monitorado precisa ter um responsável nominal pela tratativa do alerta antes mesmo do primeiro sensor ser instalado.
A definição precisa especificar quem recebe, quem aciona o campo, quem aprova a abertura da OS e quem fecha o ciclo após a intervenção.
E esse mapeamento deve mudar conforme a criticidade do ativo.Um motor classe A acoplado a uma linha contínua não deveria depender de triagem do analista para chegar ao coordenador de manutenção. Já um ventilador classe C, sem impacto operacional imediato, pode entrar no fluxo padrão do supervisor de turno e ser resolvido dentro da rotina da semana.
O que não pode acontecer é essa decisão estar só na cabeça do analista mais experiente do time, porque no dia em que ele tirar férias, o programa trava.
2. Estabelecimento de SLA por nível
Saber quem é o responsável só resolve metade do problema. A outra metade é definir em quanto tempo o alerta precisa virar ação.
Sem prazo formal por nível de criticidade, qualquer alerta acaba competindo por atenção com tudo o que está acontecendo na planta naquele dia, e a tendência é que perca para o que estiver mais visível. Plantas com SLAs claros conseguem medir o tempo entre alerta e intervenção, identificar gargalos no fluxo e cobrar prazo de quem precisa cumprir.
A calibração varia por operação. Em algumas plantas, para ativos classe A, o tempo de resposta pode ser de horas. Para classe B, dias. Para classe C, dentro da próxima parada programada.
Outras operações usam critérios distintos baseados em curva PF estimada por modo de falha. Independentemente do desenho, o SLA precisa estar registrado no CMMS junto ao ativo, e o tempo entre alerta e abertura de OS deve ser um indicador acompanhado pelo gestor. Sem isso, o backlog cresce sem que ninguém perceba.
3. Integração de sensores com CMMS
Boa parte dos projetos de monitoramento de condição quebra exatamente aqui. A plataforma de monitoramento entrega o dado em um ambiente, o CMMS abre a ordem em outro, e o time fica transcrevendo informação entre os dois.
Quando a tratativa fica registrada só no CMMS, o sistema de monitoramento perde o feedback que treina o próximo diagnóstico. Quando fica só na plataforma de condição, o histórico de execução não chega ao planejador.
Uma integração funcional deve operar em dois sentidos. Do lado do monitoramento, o alerta dispara abertura automática da OS já com modo de falha sugerido, ativo identificado, criticidade pré-classificada e procedimento prescritivo anexado.
Do lado do CMMS, o retorno da execução volta estruturado para o monitoramento: o que foi encontrado em campo, qual foi a intervenção realizada, peças substituídas, condição pós-reparo.
Esse fechamento é o que mantém o modelo de autodiagnóstico aprendendo com a realidade da operação, em vez de degradar com o tempo.
4. Configuração de feedback de execução
Esse último ponto costuma ser tratado como burocracia, e raramente recebe atenção no desenho do fluxo, mas isso se torna um erro caro. Os campos de retorno técnico após a intervenção são o combustível do aprendizado contínuo do modelo de IA. Cada alerta confirmado reforça o critério de detecção, os alertas rejeitados refinam o limiar para casos parecidos e quando o modo de falha é confirmado, isso melhora a precisão do diagnóstico futuro.
Para que isso aconteça, o registro da execução precisa capturar dados estruturados, e não apenas texto livre. Modo de falha real, severidade encontrada, tempo entre alerta e intervenção e peças substituídas são o mínimo necessário. Sem essa captura, o time investe em sensoriamento e mantém um sistema de diagnóstico que não evolui.
Inteligência Artificial: como integrá-la à execução da manutenção industrial?
A IA não substitui o fluxo de execução. O que ela faz é acelerar o ponto mais lento dele, que é a captura e interpretação do alerta pelo analista.
Em sistemas convencionais, cada alerta chega como um espectro de vibração bruto que precisa ser examinado, comparado ao histórico do ativo, cruzado com a curva PF estimada para aquele modo de falha e só então traduzido em uma recomendação prática. Multiplicado por centenas de alertas semanais numa planta razoavelmente sensorizada, esse processo cria um gargalo enorme no time de confiabilidade.
Quando a IA está aplicada ao autodiagnóstico, o alertajá vem com modo de falha provável identificado, severidade calculada contra o baseline dinâmico do próprio ativo, ação prescritiva sugerida e estimativa de janela de intervenção.
O esforço do analista deixa de ser de leitura técnica e passa a ser de validação, ou seja, aprovar a recomendação, ajustar a prioridade ou pedir uma inspeção adicional antes da OS.
O ganho prático aparece na cobertura. Um analista que conseguia acompanhar entre 30 e 50 ativos críticos com método tradicional passa a cobrir centenas, porque o esforço por alerta cai muito. Quando esse fluxo está integrado ao CMMS, a OS já nasce com diagnóstico, procedimento e peça sugerida, e a etapa de planejamento, que costumava consumir horas por semana, vira validação rápida.
Os sinais que separam um diagnóstico automatizado confiável de um alerta sem contexto
Vale uma ressalva importante antes de seguir. Nem todo "alerta automatizado" merece confiança suficiente para sustentar abertura automática de OS. Existe uma diferença grande entre um sistema que apenas notifica quando a amplitude cruza um threshold e um sistema capaz de entregar diagnóstico ancorado em modo de falha.
Cinco elementos técnicos costumam separar um do outro:
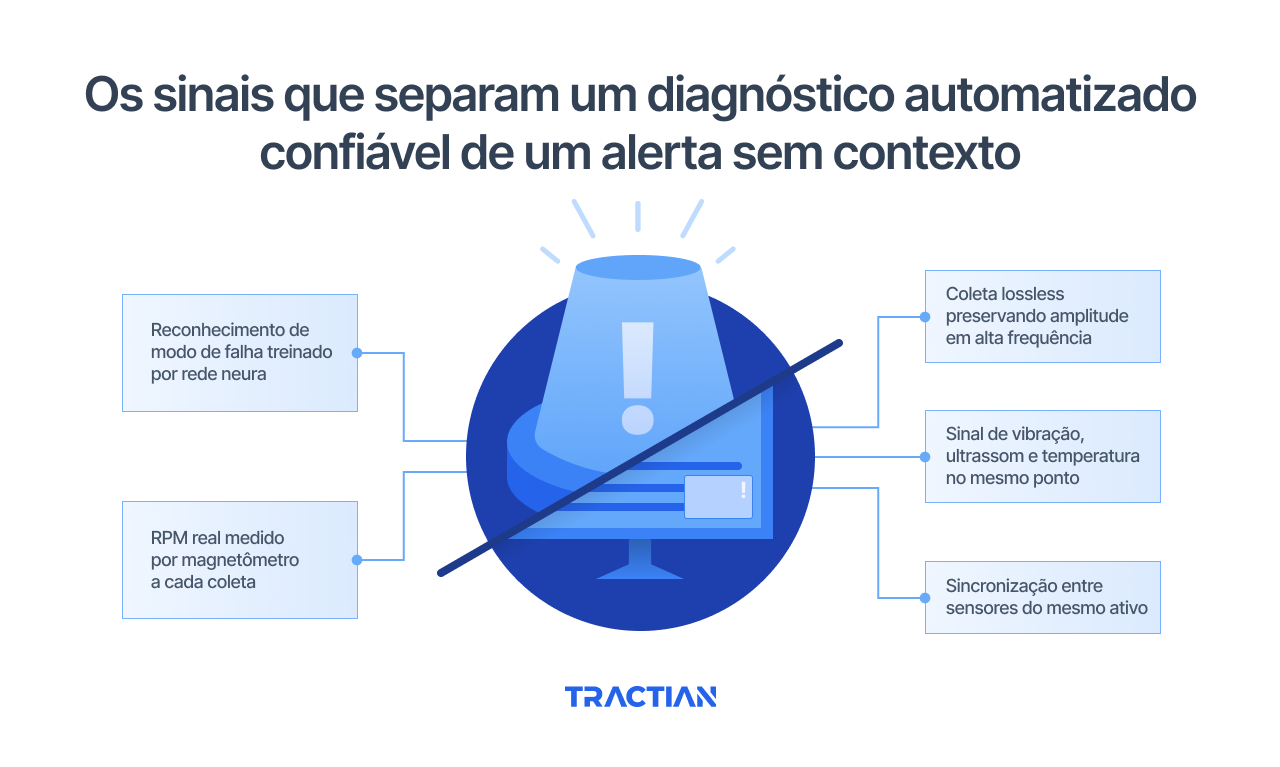
Reconhecimento de modo de falha treinado por rede neural
Um sistema que compara amplitude contra threshold avisa que há algo errado, mas não diagnostica. Já modelos de rede neural treinados com grandes bases de dados validados em campo, como o da Tractian, conseguem associar a assinatura espectral observada a uma causa raiz provável.
O alerta muda de "vibração acima do normal" para algo como "provável defeito em pista externa de rolamento (BPFO), severidade moderada, progressão estimada em duas semanas".
RPM real medido por magnetômetro a cada coleta
Sem RPM real, qualquer cálculo de frequência de defeito fica errado em ativos com velocidade variável. Quando o sensor traz magnetômetro embarcado, a frequência de rotação é extraída diretamente do campo magnético do motor, sem necessidade de tacômetro externo, e cada coleta fica ancorada ao regime de operação do momento. Sem isso, a análise espectral em ativos com VFD vira só um chute com números mentirosos.
Coleta lossless preservando amplitude em alta frequência
Sensores que aplicam compressão ou filtragem agressiva ao sinal antes de transmitir perdem justamente o que antecipa falhas.
Defeitos em estágio inicial costumam viver nas altas frequências e em amplitudes baixas, onde a compressão tradicional corta primeiro. Sensores com coleta sem perda na transmissão mantém o sinal íntegro e abrem espaço para detecção precoce que sistemas convencionais simplesmente ignoram.
Sinal de vibração, ultrassom e temperatura no mesmo ponto
Cada técnica enxerga um lado da falha. Vibração captura desbalanceamento, desalinhamento, folga e defeito de rolamento. Ultrassom antecipa atrito, problema de lubrificação e vazamento. Temperatura confirma sobrecarga e fricção excessiva.
Quando os três vêm do mesmo ponto físico do ativo, o diagnóstico cruzado passa a ser viável.
Sincronização entre sensores do mesmo ativo
Em conjuntos com motor, redutor e bomba acoplados, a falha em um componente reflete no espectro dos outros.
Quando os sensores coletam de forma sincronizada no tempo, é possível correlacionar leituras simultâneas e identificar a origem real do problema, em vez de tratar cada ponto como se fosse um ativo isolado.
Como a Tractian conecta condição, decisão e execução no mesmo ambiente
A maior parte dos fornecedores entrega o sensor, entrega o dashboard e deixa a integração com o CMMS como dever de casa do cliente. A Tractian opera de outro jeito. Monitoramento, decisão e execução acontecem no mesmo ambiente, com o mesmo dado, sob a mesma governança.
A solução de monitoramento de condição da Tractian combina vibração, ultrassom, temperatura e medição contínua de RPM por magnetômetro em um único sensor, com coleta lossless e sincronização entre pontos do mesmo ativo.
Cada alerta nasce com modo de falha identificado, baseline dinâmico do próprio equipamento, severidade calculada e ação prescritiva sugerida. Esse alerta dispara abertura automática de ordem de serviço no CMMS, já com criticidade classificada, procedimento técnico anexado e responsável definido conforme as regras configuradas para aquele ativo.
Depois da intervenção, o feedback de campo retorna estruturado para o modelo de autodiagnóstico, que reforça ou ajusta seus critérios com base no que foi encontrado.
Esse loop viabiliza uma gestão de manutenção completa, com priorização, investigação, decisão e ação rodando no mesmo lugar, sem transcrição entre sistemas e sem perda de contexto entre o alerta e a OS.
Para a operação, o efeito direto é que escalar para centenas ou milhares de pontos monitorados deixa de demandar aumento proporcional do time de análise, e cada ordem de serviço carrega a rastreabilidade do alerta que a originou.
Não escolha o sensor que faz só uma parte do trabalho e deixa a parte difícil com você. A Tractian entrega o pacote completo com qualidade e confiabilidade.
FAQ
Como escolher um sensor de monitoramento que se conecte com CMMS?Verifique se o fornecedor entrega integração nativa, e não apenas API documentada. Integração nativa significa que o alerta dispara automaticamente a abertura da OS com modo de falha e ação prescritiva já anexados. API documentada significa começar um projeto de TI antes de conseguir tirar valor do primeiro alerta.
Quais os benefícios de centralizar os dados do monitoramento em uma plataforma?Eliminação de transcrição manual entre sistemas, rastreabilidade entre alerta e intervenção, feedback estruturado que retroalimenta o modelo de diagnóstico e visão única de saúde do ativo correlacionada à execução da manutenção. Em escala, é a diferença entre cobrir 50 ou 5.000 pontos com o mesmo time.
Sensor de ultrassom realmente pode ajudar na manutenção industrial?Sim, especialmente para modos de falha que vibração isolada não antecipa cedo o suficiente: problema de lubrificação, atrito incipiente e vazamento em sistemas de ar comprimido e vapor. Combinado com vibração no mesmo ponto, ultrassom melhora significativamente a detecção precoce de falhas de origem tribológica.
Quais sensores de monitoramento industrial são os melhores? Os que combinam múltiplos sinais (vibração, ultrassom, temperatura e RPM medido por magnetômetro), entregam coleta lossless em alta frequência, integram com o CMMS de forma nativa e operam com autodiagnóstico baseado em IA treinada em base ampla de modos de falha. Sensores que medem apenas vibração resolvem parte do problema, mas deixam falhas relevantes escondidas.
