

No hay forma de evitarlo: cuando una máquina se descompone, la producción se detiene. Pero aquí está el punto clave, la mayoría de las fallas en las máquinas no ocurren de repente. Se desarrollan poco a poco, ocultas y sin ser detectadas… hasta que, claro, es demasiado tarde.
Y cuando la confiabilidad no es negociable, cada paro no programado importa. Aun así, muchos equipos de trabajo se ven sorprendidos por emergencias que pudieron evitarse con la estrategia adecuada.
Entender qué causa una falla de equipo es el primer paso para construir una operación más resistente. Pero no basta con conocer la teoría.
También necesitas identificar señales de fallas potenciales en tiempo real, reconociendo puntos débiles antes de que se conviertan en problemas. Además, necesitas contar con sistemas que vuelvan natural la acción preventiva.
Esta guía te muestra exactamente por dónde empezar. Desde los tipos de equipos más propensos a fallar hasta las causas ocultas que generan costosos tiempos muertos, recorreremos las razones principales por las que ocurren las fallas y cómo detenerlas antes de que sucedan.
¿Qué es una falla de equipo?
Una falla de equipo ocurre cuando una máquina o un componente no puede cumplir su función prevista. Puede ser una falla total o un fallo parcial.
En cualquier caso, el resultado es el mismo: el rendimiento cae y los procesos se detienen.
Pero la falla no es solo un evento mecánico, también es una señal importante que merece atención. Estas señales indican que algo dentro del proceso se ha desviado o deteriorado.
Y casi siempre cada falla se relaciona con la forma en que ese equipo fue operado y si recibió mantenimiento (o fue ignorado) con el tiempo.
Desde la perspectiva de confiabilidad, una falla de equipo es un problema técnico y estratégico. No basta con reaccionar cuando algo deja de funcionar. El verdadero objetivo es reducir la probabilidad de fallas mediante monitoreo constante, análisis de datos y decisiones que prioricen el rendimiento a largo plazo sobre soluciones rápidas.
Ese cambio, de reaccionar a anticipar, es lo que distingue a las plantas que persiguen el uptime de aquellas que realmente lo logran.
Tres tipos de equipos que fallan
No todos los activos están construidos o se usan de la misma forma; por eso, distintos tipos de equipo presentan diferentes riesgos de falla. Y si buscas prevenir averías, entender esos riesgos específicos es fundamental.
Estos son los tres tipos de equipos que aparecen con más frecuencia en reportes de fallas en operaciones industriales:
1. Equipos rotativos
Motores, bombas, compresores, ventiladores y cajas de engranes: cualquier equipo con partes móviles que dependan de velocidad y alineación constante tiende a fallar con más frecuencia.
Son activos de alto valor y alta dependencia, pero suelen fallar por desgaste, desbalance, mala lubricación o desalineación. Por operar bajo estrés mecánico continuo, son candidatos ideales para el monitoreo de condición y mantenimiento predictivo.
2. Equipos eléctricos
Paneles, transformadores y componentes similares entran en esta categoría. Las fallas generalmente ocurren por estrés térmico, ruptura de aislamiento, conexiones flojas o contaminación.
Como las fallas eléctricas pueden generar riesgos mayores de seguridad y cumplimiento, aquí las apuestas son más altas, lo que vuelve indispensable el mantenimiento preventivo y predictivo.
3. Sistemas de utilidades y soporte
Chillers, calderas, sistemas HVAC.
Aunque operan en segundo plano, sus fallas generan interrupciones en cadena: variaciones de temperatura, retrasos logísticos y costos inesperados. Con frecuencia, se encuentran atrapados en un ciclo de descuido, ignorados hasta que se descomponen (lo que explica por qué fallan tanto).
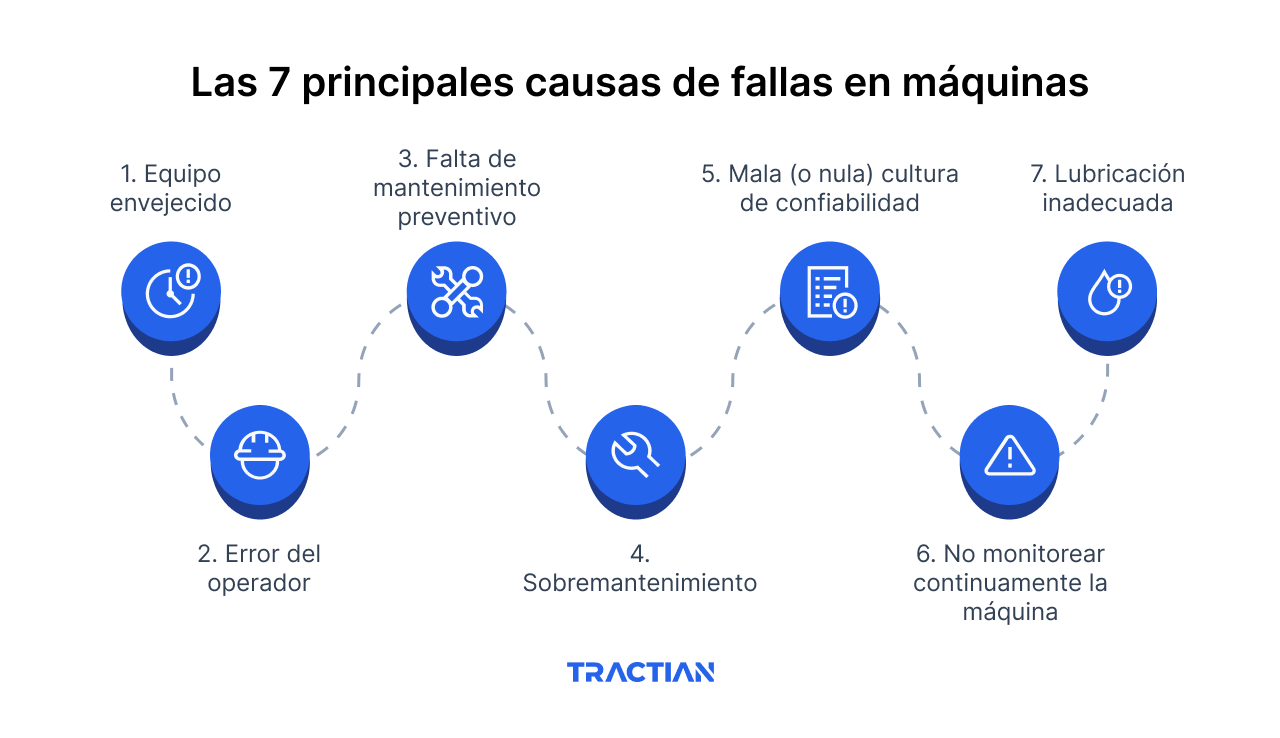
Las 7 causas más comunes de fallas de equipo
Si revisas cualquier falla a profundidad, verás un patrón. La mayoría se puede rastrear a una de estas siete causas:
1. Equipo envejecido (equipo viejo)
Cada activo tiene una vida útil. Con el tiempo, el desgaste se acumula y los sistemas salen de especificación.
Estos equipos envejecidos se vuelven menos tolerantes al estrés y más propensos a fallar, especialmente si se han usado por encima de sus límites de diseño o no recibieron el mantenimiento adecuado durante su ciclo de vida.
El problema no es la edad, es tratarlos como si siguieran operando en condiciones óptimas. Sin monitoreo de condición, la degradación avanza silenciosamente hasta que un componente falla.
Para evitarlo, se necesita mayor visibilidad, inspecciones frecuentes y, cuando sea necesario, planes de reemplazo programado.
2. Error del operador
La forma en la que se opera una máquina determina cuánto tiempo durará. Arranques incorrectos, cargas excesivas o malos hábitos pueden causar fallas prematuras.
La raíz del problema suele ser la falta de procedimientos claros y la presión del tiempo que lleva a errores repetitivos.
La solución: actualizar SOPs, realizar check-ins de operación y usar sistemas digitales que vinculen historial de uso con condición del activo.
3. Falta de mantenimiento preventivo
Sin mantenimiento regular, los problemas pequeños se vuelven grandes. La corrosión avanza, los filtros se tapan y un descuido genera una cadena de fallas.
Aquí aparece el debate clásico: “¿Por qué no dejar que el equipo falle y arreglarlo después?”
Eso es run-to-failure, un enfoque reactivo válido solo para componentes de bajo costo y baja criticidad.
Pero en activos críticos puede provocar:
- Tiempos muertos largos
- Reparaciones costosas
- Cero control sobre cuándo ocurrirá la falla
El mantenimiento preventivo programa tareas por tiempo o uso, reduciendo la probabilidad de fallas. No es perfecto, pero crea una capa de protección.
4. Mantenimiento excesivo
Sorprendentemente, demasiado mantenimiento también puede generar fallas.
Sucede cuando sistemas obsoletos o checklists rígidos no consideran la condición real del activo.
Cambiar un componente antes de tiempo introduce riesgos innecesarios.
El mantenimiento basado en condición (CBM) y el análisis predictivo permiten intervenir solo cuando realmente es necesario.
5. Mala cultura de confiabilidad
La confiabilidad es un resultado cultural, no sólo técnico. Cuando la cultura es débil, las fallas se vuelven un problema recurrente.
Señales de mala cultura:
- Equipos en modo “apagafuegos”
- Planificadores saturados
- Liderazgo que prioriza producción inmediata sobre estabilidad
Lo bueno: sí se puede corregir. Todo comienza con alinear a todos en lo mismo: que los activos operen como deben.
6. No monitorizar continuamente
La mayoría de las fallas muestra señales antes de ocurrir: temperatura, vibración, presión.
Sin monitoreo continuo, esas señales pasan desapercibidas.
Con sensores IoT y plataformas CMMS integradas, los equipos pueden detectar anomalías y resolver problemas antes de que escalen.
7. Lubricación inadecuada
Una de las formas más rápidas de destruir un equipo es una lubricación deficiente o incorrecta.
Muy poca lubricación → fricción y calor.Demasiada → arrastra contaminación.
Incluso usar el lubricante equivocado puede desgastar componentes enteros.
Para evitarlo, cada tarea de lubricación debe estar claramente programada y verificada durante inspecciones.
¿Cómo prevenir las fallas de equipo?
Saber qué causa las fallas es sólo la mitad del trabajo. La otra mitad ,donde realmente se construye una operación confiable, es aprender a prevenirlas de manera constante y rentable.
Esto no significa renovar toda la operación de golpe. Significa fortalecer la conexión entre personas, procesos y tecnología.
Así puedes hacerlo:
Plan de acción
Conoce cómo estructurar un plan de mantenimiento efectivo y hacer tu gestión más eficiente y libre de errores, usando datos reales de tu operación.
1. Proporciona capacitación integral al operador y mantén el cumplimiento normativo
Los operadores son la primera línea de defensa en la confiabilidad de activos. Si no están completamente capacitados, el riesgo de daños involuntarios aumenta considerablemente.
La capacitación no debe terminar con el onboarding.
Sesiones de actualización, recordatorios, y acceso rápido a procedimientos ,especialmente cuando se hacen cambios, mantienen los estándares operativos altos.
Además, conforme crecen las exigencias regulatorias, la capacitación continua asegura el cumplimiento normativo, reduciendo riesgos de violaciones de seguridad o fallas en auditorías.
2. Monitorea y analiza el equipo de forma digital
Los programas de mantenimiento basados en calendarios ya no pueden seguir el ritmo de entornos productivos dinámicos. Por eso, el monitoreo digital es esencial: no sólo para registrar el rendimiento en tiempo real, sino para entender tendencias a largo plazo.
Sensores conectados y plataformas CMMS permiten monitorear de forma continua vibración, temperatura, presión y otros indicadores críticos.
Así es como los equipos pasan de “arreglar” a pronosticar.
3. Equilibra el mantenimiento preventivo con el mantenimiento basado en condición
El mantenimiento preventivo mantiene los activos funcionando. Pero ejecutarlo en intervalos fijos, sin considerar el desgaste real, puede causar sobre mantenimiento o fallas no detectadas.
El mantenimiento basado en condición (CBM) llena ese vacío. Activa intervenciones según datos en tiempo real, no solo por fechas o horas de operación.
El objetivo no es reemplazar el mantenimiento preventivo, sino optimizarlo.
4. Adjunta SOPs a cada orden de trabajo
Cuando un técnico recibe una orden de trabajo, no debería adivinar qué implica “reemplazar rodamiento”. Cada tarea debe incluir un Procedimiento Operativo Estándar (o SOP, por sus siglas) claro y actualizado.
Incorporar SOPs en órdenes de trabajo digitales estandariza los flujos de mantenimiento, reduce errores y acorta el tiempo de capacitación para nuevos técnicos.
5. Realiza inspecciones de mantenimiento de rutina
Las inspecciones de rutina son tus ojos y oídos en el piso de producción. No tienen que ser complicadas.
Revisiones visuales, detección de ruidos anormales o escaneos térmicos pueden revelar problemas temprano.
La clave es la consistencia.
Las inspecciones aleatorias detectan poco. Recorridos estructurados y programados permiten a los técnicos identificar desviaciones. Y cuando los hallazgos se documentan en un CMMS, construyen un historial del equipo que mejora futuras decisiones.
6. Implementa estrategias de mantenimiento preventivo
El mantenimiento preventivo es una estrategia fundamental ,y con razón, porque estandariza tareas antes de que ocurra la falla.
Pero para ser realmente efectivo debe adaptarse a:
- Criticidad del activo
- Patrones de uso
- Historial de fallas
Aquí es donde los datos del activo son clave.
Los equipos que analizan esta información pueden diseñar planes de PM que se ajusten a las necesidades reales de su operación, no sólo a las recomendaciones del fabricante.
¿Por qué el análisis de causa raíz es fundamental para prevenir fallas?
Reparar una pieza dañada es una cosa. Entender por qué falló en primer lugar es donde ocurre la verdadera transformación.
El Root Cause Analysis (RCA) es el proceso de rastrear una falla hasta su origen. No se enfoca solo en el síntoma: identifica el detonante real detrás del problema. Saltarse este paso mantiene a los equipos atrapados en un ciclo constante de averías repetidas.
Toda falla puede vincularse a una causa raíz: desalineación, malas prácticas de lubricación, procedimientos inconsistentes, problemas en la cadena de suministro o incluso software mal configurado.
Sin un RCA, esos patrones permanecen sin atender, y los mismos problemas vuelven a ocurrir una y otra vez.
Cuando se hace correctamente, el RCA impulsa mejoras en los procesos y transforma las estrategias de mantenimiento. También alimenta datos valiosos a tu CMMS, volviendo tu sistema más inteligente con el tiempo.
El RCA no es solo para fallas mayores. Incluso problemas pequeños y recurrentes pueden revelar brechas ocultas en procesos, componentes o coordinación del equipo. Cuanto antes se identifiquen esas brechas, más fácil será resolverlas.
Indicadores clave para evitar las fallas de equipo
Monitorear KPIs críticos es esencial para anticipar fallas en el equipo.
Al analizar métricas específicas, los equipos de mantenimiento pueden detectar señales tempranas y tomar acciones correctivas antes de que un problema menor se convierta en una falla mayor.
Aquí tienes los KPI más importantes:
1. Tiempo promedio entre fallas (MTBF)
El MTBF mide el tiempo promedio de operación entre fallas de un equipo. Un MTBF alto indica que el activo opera por más tiempo sin fallas, reflejando mayor confiabilidad.
Cálculo:
Tiempo total de operación ÷ número de fallas.
Monitorear el MTBF ayuda a detectar patrones y programar mejor el mantenimiento preventivo.
2. Tiempo promedio de reparación (MTTR)
El MTTR mide el tiempo promedio necesario para reparar un equipo y devolverlo a funcionamiento total. Un MTTR bajo indica que el equipo de mantenimiento atiende fallas de forma rápida y eficiente.
Cálculo:
Tiempo total de mantenimiento ÷ número de reparaciones
Monitorear el MTTR permite evaluar qué tan eficiente es tu proceso de mantenimiento y dónde mejorar.
3. Disponibilidad del equipo
Este KPI indica el porcentaje de tiempo que el equipo está disponible y operacional. Una disponibilidad alta significa mínimo tiempo muerto.
Fórmula estándar:
Disponibilidad = (Tiempo de operación real ÷ Tiempo total) × 100
4. Confiabilidad del equipo
La confiabilidad mide la probabilidad de que el equipo opere sin fallar durante un periodo específico bajo condiciones definidas.
Incluye factores como MTBF, tasa de fallas y desempeño histórico. Mejorar procesos y resolver fallas rápido aumenta la confiabilidad.
5. Backlog de mantenimiento
Este indicador rastrea las tareas de mantenimiento programadas pero no completadas.
Un backlog creciente indica:
- Falta de recursos.
- Procesos ineficientes.
- Mala priorización.
Administrarlo evita que actividades críticas se retrasen.
6. Tiempo de inactividad
Registrar el tiempo total en que un equipo está fuera de operación ayuda a:
- Detectar problemas repetitivos.
- Evaluar la efectividad del mantenimiento.
- Justificar inversiones.
7. Costo de mantenimiento como porcentaje del valor de reemplazo (MC/ERV)
Mide la relación entre el costo de mantenimiento y el valor de reemplazo del equipo (Estimated Replacement Value).
Un MC/ERV alto indica un gasto excesivo que puede sugerir que:
- El equipo necesita renovación.
- El plan de mantenimiento es ineficiente.
8. Distribución por tipos de mantenimiento
Analiza la proporción entre:
- Mantenimiento preventivo
- Mantenimiento predictivo
- Mantenimiento correctivo
Una distribución equilibrada evita desperdicio de recursos y mejora la estrategia global.
¿Cómo anticipar fallas de equipo con monitoreo de condición?
Las fallas no ocurren de la nada. Generalmente son resultado de:
- Desgaste ignorado
- Procesos inconsistentes
- Señales de alerta pasadas por alto
- Estrategias desactualizadas
Desde activos envejecidos hasta falta de información en tiempo real, las causas son claras, pero también las oportunidades de prevenirlas.
Aquí es donde el monitoreo de condición hace toda la diferencia.
Monitorear datos críticos del equipo en tiempo real permite anticipar fallas antes de que sucedan. Cambios sutiles en temperatura, vibración o consumo energético se vuelven indicadores tempranos que muestran cuándo intervenir.
Esto es exactamente lo que hace la solución de monitoreo de condición de Tractian: Detecta anomalías temprano y las conecta con patrones históricos, generando insights accionables.
¿Quieres evitar fallas y reducir costos?
Descubre cómo la solución de monitoreo de condición de Tractian ayuda a los equipos a tomar control total de sus activos.
