

Equipos reducidos, objetivos ambiciosos y activos que se desgastan rápido: esta es la realidad de muchos gerentes de mantenimiento. Para intentar resolver esta ecuación, toman decisiones basadas en inspecciones puntuales y en informes que no siempre están actualizados ni resultan útiles.
El problema es que este modelo no puede seguir el ritmo de la velocidad con la que se forman las fallas ni de la presión de confiabilidad que exige el negocio.
No es casualidad que los sistemas de monitoreo industrial en tiempo real estén ganando fuerza en este mercado. Con sensores que recopilan datos de manera continua y análisis que revelan patrones invisibles a simple vista, los responsables de mantenimiento dejan de operar a ciegas y pasan a tener claridad sobre cada activo en el momento de tomar decisiones importantes.
Esto genera una operación más predecible y un camino mucho más sostenible para aumentar la confiabilidad sin incrementar la carga de trabajo del equipo.
Este artículo explora las posibilidades que el monitoreo en tiempo real ofrece, además de casos reales de éxito en su implementación y estrategias para convertir esos resultados en realidad dentro de tu operación.
Por qué el modelo tradicional de inspecciones ya no sostiene la confiabilidad
Durante mucho tiempo, el mantenimiento confió en inspecciones presenciales y rutinas de recolección manual de datos para identificar anomalías en el comportamiento de los activos. Pero a medida que los parques industriales se volvieron más complejos y los objetivos de disponibilidad más estrictos, este modelo comenzó a mostrar sus limitaciones.
Este tipo de registro ofrece apenas imágenes estáticas y esporádicas de la condición del activo, casi como “fotografías” de cómo se comportó en un momento aislado. Sin embargo, en la práctica, las fallas evolucionan continuamente y, a menudo, con demasiada rapidez como para ser captadas en visitas mensuales o semanales.
Otro punto crítico es el esfuerzo operativo que implica. Los técnicos necesitan desplazarse hasta áreas aisladas o de difícil acceso para realizar mediciones que, en muchos casos, no indican cambios reales. Esto consume tiempo, aumenta la exposición al riesgo y, en la práctica, no impide que fallas ocultas se desarrollen entre una recopilación de datos y otra. Sin datos de tendencia, las decisiones terminan basándose en suposiciones y no en evidencias.
Existe también un problema estructural: este modelo es, por naturaleza, reactivo. Incluso con equipos calificados, el mantenimiento solo descubre el problema cuando ya es audible, perceptible o lo suficientemente crítico como para alterar el desempeño. Esto reduce la capacidad de planificación, aumenta el número de emergencias y mantiene a los equipos atrapados en un ciclo de apagar incendios.
No es falta de competencia del equipo. Lo que falta es visibilidad continua. Sin ella, ninguna estrategia de confiabilidad se sostiene a largo plazo.
Pero ¿cómo garantizar esa visibilidad?
Qué cambia cuando la industria adopta el monitoreo en tiempo real
La principal transformación que trae el monitoreo en tiempo real es el cambio de enfoque: el mantenimiento deja de reaccionar a eventos y pasa a actuar con anticipación. Cuando los datos se recopilan de forma continua, el equipo ya no necesita esperar a que un ruido revele una falla avanzada. La propia máquina pasa a señalar, en tiempo real, cualquier desviación relevante en su comportamiento.
Una mayor visibilidad transforma la forma en que los gerentes planean y priorizan las intervenciones. En lugar de seguir rutinas fijas de inspección, el equipo gana la posibilidad de trabajar con base en tendencia, severidad y contexto operativo.
Se vuelve posible intervenir aún en el inicio de la curva PF, cuando la falla es invisible a simple vista, y programar intervenciones con impacto mínimo en la producción, evitando paradas inesperadas y distribuyendo mejor la carga de trabajo.
Esto sin mencionar el aumento en la previsibilidad. Cuando se tiene acceso al estado real de cada activo a lo largo de todo el ciclo de operación, se vuelve más fácil ajustar recursos, negociar ventanas con producción e incluso revisar los planes de mantenimiento con base en datos.
Beneficios técnicos directos del monitoreo continuo
Cuando el monitoreo pasa a realizarse de forma continua, el área de mantenimiento deja de operar en espacios de incertidumbre y pasa a tener visibilidad del estado de los activos en tiempo real. Esto genera una serie de mejoras inmediatas y medibles tanto en la rutina del equipo como en el desempeño de la planta.
Entre los principales beneficios técnicos, se destacan:
Detección temprana de fallas y reducción de emergencias
Con datos recopilados de manera continua, el equipo identifica cambios sutiles en el comportamiento de los activos mucho antes de que se vuelvan audibles o perceptibles en el campo, cuando la corrección aún es simple, rápida y de bajo impacto.
Esto provoca una reducción de intervenciones de emergencia y de todas las consecuencias asociadas a ellas, como paradas no planificadas, presión operativa y costos elevados de corrección.
Además, al interpretar tendencias en tiempo real, el equipo deja de depender únicamente de análisis presenciales o de recolección esporádica de datos para identificar fallas. El monitoreo continuo funciona como un “radar” activo, anticipando desviaciones y permitiendo que la planificación reaccione con horas o días de ventaja.
Aumento de la disponibilidad y la confiabilidad
Es un hecho: a medida que las fallas dejan de evolucionar sin supervisión, la disponibilidad aumenta. La operación pasa a sufrir menos interrupciones inesperadas y más intervenciones programadas, ejecutadas en el momento ideal y con los recursos adecuados. Esto reduce el MTTR, extiende el MTBF y estabiliza el comportamiento de los activos a lo largo del tiempo.
Esa previsibilidad también fortalece la planificación entre turnos. Con menos urgencias y más intervenciones planificadas, los gerentes pueden coordinar mejor sus turnos con la producción, logística y seguridad, creando un ciclo continuo de confiabilidad.
Optimización de rutinas de inspección y reducción de desplazamientos
Cuando el análisis es automático y las desviaciones se detectan digitalmente, las inspecciones dejan de ser generales y se vuelven específicas. En lugar de visitar todos los equipos de la ruta, el técnico va únicamente a donde los datos indican un cambio relevante. Esto reduce horas de desplazamiento, elimina visitas improductivas y aumenta la eficiencia general del equipo.
Como consecuencia de la creación de un historial continuo, es posible revisar los planes de inspección basándose en el comportamiento real de los activos, ajustando frecuencia, priorización y recursos.
El resultado es un uso mucho más inteligente de la fuerza de trabajo en toda la operación.
Reducción de la exposición a riesgos (menos visitas a áreas críticas)
Gran parte de los activos críticos se encuentran en áreas de difícil acceso o con alto riesgo operativo, ya sea por altura, calor, ruido, espacios confinados o proximidad a sustancias peligrosas. Con el monitoreo continuo, muchas de esas inspecciones presenciales dejan de ser necesarias, reduciendo drásticamente la exposición del técnico.
El equipo solo necesita acercarse al activo cuando una alerta real indique la necesidad de intervención. Esto aumenta la seguridad operativa, disminuye las horas en áreas sensibles y reduce la probabilidad de incidentes durante las inspecciones rutinarias.
Mayor previsibilidad presupuestaria y planificación anual
Con información precisa sobre tendencias de falla, severidad y comportamiento histórico, el presupuesto de mantenimiento deja de depender únicamente de estimaciones genéricas. Los costos pueden proyectarse con mayor precisión, incluyendo repuestos, mano de obra y tiempo de inactividad de la maquinaria.
Al tener claridad sobre qué activos requerirán intervención a lo largo del año, los gerentes pueden planear compras con anticipación, reducir emergencias financieras y negociar mejor con los proveedores. Esta previsibilidad se refleja directamente en la salud del OPEX y en el control de los costos anuales de mantenimiento.
Qué significa realmente monitorear en tiempo real
Monitorear en tiempo real va mucho más allá de instalar un sensor en la máquina. Implica crear un flujo continuo de recolección, procesamiento e interpretación de datos que transforma el comportamiento del activo en información útil para la gestión.
En lugar de medir el equipo una vez al mes o depender de percepciones subjetivas, el sensor registra vibración, temperatura y otras variables en intervalos de pocos minutos, construyendo un historial robusto que revela cualquier cambio relevante en el patrón de operación.
En la práctica, esto solo es posible porque el sensor funciona como un “estetoscopio digital”. Monitorea el activo las 24 horas del día, capta señales que evolucionan de forma imperceptible y envía esa información automáticamente para su análisis.
Este volumen masivo de datos abrumaría a cualquier equipo, pero con algoritmos de análisis y modelos de comportamiento, el sistema interpreta estas variaciones, identifica anomalías y señala únicamente lo que realmente importa (algo inviable en rutinas de recolección manual).
Este conjunto de recolección continua, análisis automatizado y alertas contextualizados es lo que realmente diferencia el monitoreo en tiempo real. No solo detecta la anomalía más temprano, sino que lo hace con precisión y rapidez reduciendo falsos positivos y entregando al equipo una visión clara de qué hacer, cuándo actuar y por qué.
Paso a paso para aplicar el monitoreo industrial en tiempo real
Implementar el monitoreo en tiempo real implica repensar procesos, prioridades y la forma en la que el equipo interpreta la información del activo. Para garantizar que el sistema entregue resultados desde el primer mes, es necesario seguir algunos pasos que guían la implantación y orientan la evolución de la operación.
A continuación, una guía práctica para poner el monitoreo continuo en funcionamiento en tu planta:
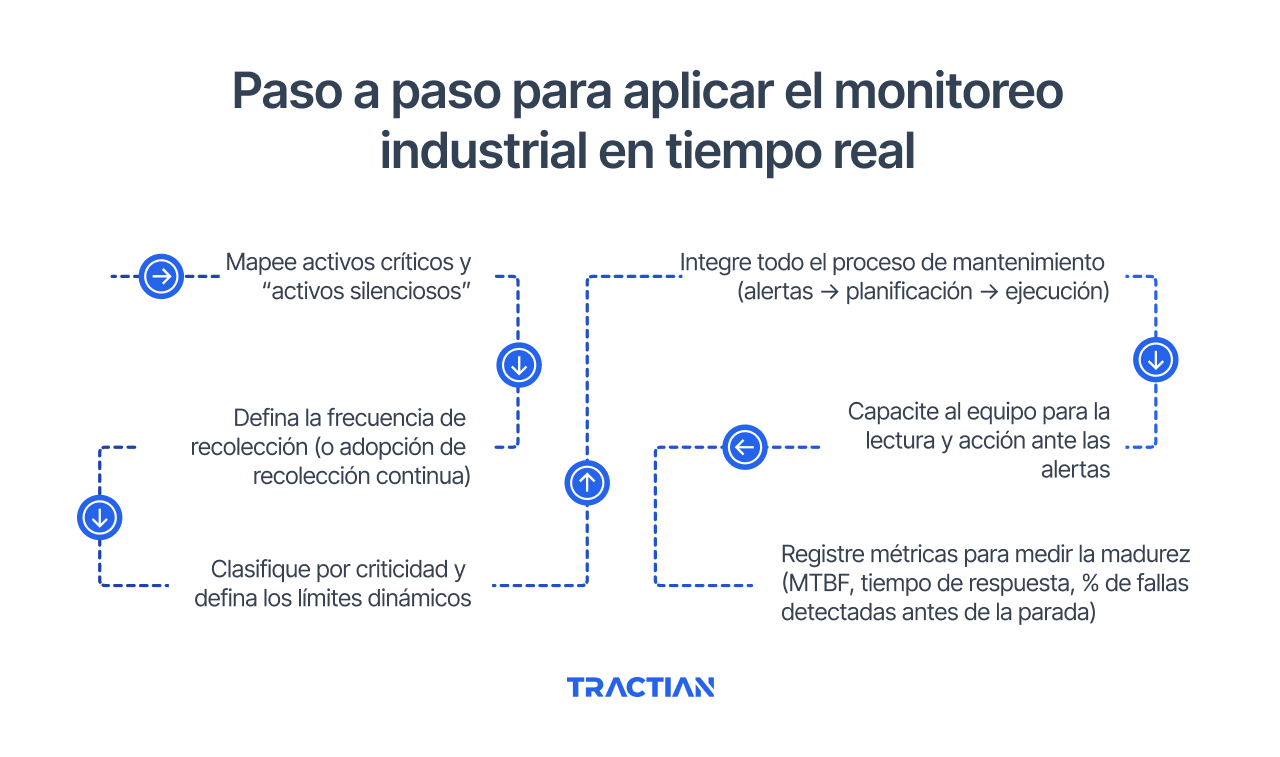
1. Mapea los activos críticos y los “activos silenciosos”
El primer paso es entender dónde están los riesgos reales de la operación. Se deben priorizar los activos críticos que impactan directamente la producción, la seguridad o el medio ambiente.
Pero los “activos silenciosos” merecen la misma atención: equipos que rara vez fallan, que están aislados o que no reciben inspecciones frecuentes, pero cuyo impacto sería alto si dejaran de funcionar. Este mapeo indica dónde el monitoreo continuo generará el mayor retorno inmediato.
2. Define la frecuencia de recolección (o adopta la recolección continua)
En los modelos tradicionales, se debe definir la periodicidad de las inspecciones con base en el historial y en la carga operativa. En el monitoreo en línea, esta etapa se transforma: en lugar de decidir entre 15, 30 o 60 días, la recolección de datos pasa a realizarse automáticamente cada pocos minutos.
Este cambio elimina puntos ciegos y garantiza que desviaciones rápidas o intermitentes se detecten temprano, antes de convertirse en fallas perceptibles o críticas.
3. Clasifica por criticidad y define los límites dinámicos
No tiene sentido tratar todos los activos de la misma forma. Los equipos de criticidad de clase A necesitan alertas más sensibles, que se activan en las primeras etapas de una falla. Los activos B y C, en cambio, pueden operar con mayor tolerancia.
Los sistemas con análisis automatizado e inteligencia adaptativa ajustan estos límites según el comportamiento real de la máquina, reduciendo falsas alarmas y haciendo el monitoreo más preciso.
4. Integra todo el proceso de mantenimiento
El monitoreo solo genera valor cuando se convierte en acción. Por eso, el flujo de trabajo debe estar integrado: una alerta relevante debe generar automáticamente una orientación en la planificación, que luego se convierte en una orden de trabajo clara para la ejecución.
Alerta → Planificación → Ejecución de la intervención
Cuanto menor sea la distancia entre alerta e intervención, mayor será la eficacia del sistema. Esta integración evita la pérdida de información, reduce el retrabajo y garantiza que el mantenimiento predictivo se comunique directamente con las acciones preventivas y correctivas.
5. Capacita al equipo para interpretar y actuar sobre las alertas
La tecnología no sustituye al equipo, sino que lo fortalece. Para eso, técnicos y gerentes deben entender cómo interpretar tendencias, qué significa cada tipo de alerta y cómo priorizar las intervenciones.
Las capacitaciones enfocadas en patrones de falla y análisis de severidad aceleran la adopción y aumentan la precisión de las decisiones. Cuanto más familiarizado esté el equipo con el flujo de trabajo, más eficaz será el mantenimiento.
6. Registra métricas para medir la madurez
La implementación es solo el comienzo. Monitorear los resultados es lo que garantiza la mejora continua. Indicadores como MTBF, MTTR, el tiempo entre alerta e intervención y el porcentaje de fallas detectadas tempranamente revelan la efectividad del monitoreo.
Con estas métricas, los gerentes pueden ajustar el plan, revisar los límites de alerta e identificar oportunidades para ampliar la cobertura.
Caso real: qué cambia cuando la IA entra en el monitoreo
ICONIC, líder en el mercado de lubricantes, operaba con baja visibilidad sobre los activos críticos y con un ciclo constante de emergencias. Sin datos continuos, las decisiones se tomaban bajo presión y las fallas ocultas evolucionaban hasta generar paradas de alto impacto.
Con el monitoreo en línea y el análisis automatizado, la empresa revirtió este escenario rápidamente. En tres meses, el 63% de la planta ya estaba cubierta, incluyendo el 100% de las bombas primarias de los 56 tanques. El área de mantenimiento comenzó a monitorear la vibración y temperatura en tiempo real, identificar desvíos en el inicio de la curva PF y transformar las alertas en órdenes de trabajo priorizadas.
En 18 meses, ICONIC detectó 70 fallas críticas antes de que se convirtieran en emergencias, aumentó la disponibilidad del 70–80% al 95–98% y redujo las largas intervenciones a reparaciones completadas en 24 a 48 horas. En una única parada evitada, la empresa evitó 9 millones de litros y más de un mes de indisponibilidad en una línea crítica gracias al monitoreo continuo.
Con el uso de inteligencia artificial para ajustar alertas al contexto operativo e indicar causas probables, la empresa consolidó una rutina predecible, con menos sorpresas y decisiones basadas en datos, demostrando en la práctica el impacto real del monitoreo inteligente a escala industrial.
Cómo los sensores de Tractian transforman el monitoreo de tu mantenimiento
El monitoreo en tiempo real solo marca la diferencia cuando ofrece precisión, velocidad y capacidad real de interpretar lo que sucede dentro de la máquina.
La solución de monitoreo continuo de Tractian es altamente eficiente en cada una de estas necesidades. Captura vibración, temperatura y patrones operativos en intervalos de minutos, creando un historial detallado que revela cualquier cambio, por menor que sea, antes de que se convierta en una falla perceptible.
Los sensores funcionan como una extensión técnica del equipo, operando las 24 horas del día, incluso en áreas remotas, de difícil acceso o con alto riesgo operativo. Y no entregan solo números en bruto: cada lectura es procesada por modelos matemáticos e inteligencia artificial que aprenden el comportamiento natural del activo, ajustan automáticamente los límites de alerta y reducen los falsos positivos.
Esto significa que el equipo recibe únicamente lo que importa: alertas claras, contextualizadas y orientadas a la acción. Con este nivel de visibilidad, el mantenimiento deja de depender de inspecciones puntuales y comienza a actuar de forma planificada, con bajo costo y mínimo impacto en la operación.
Además, en pocos días de implementación, el sensor proporciona informes iniciales de salud, comparando cada activo con una amplia base de datos industrial y ofreciendo información precisas sobre tendencias, gravedad y posibles modos de falla, una ventaja que ninguna recopilación manual es capaz de ofrecer.
