

Key Points
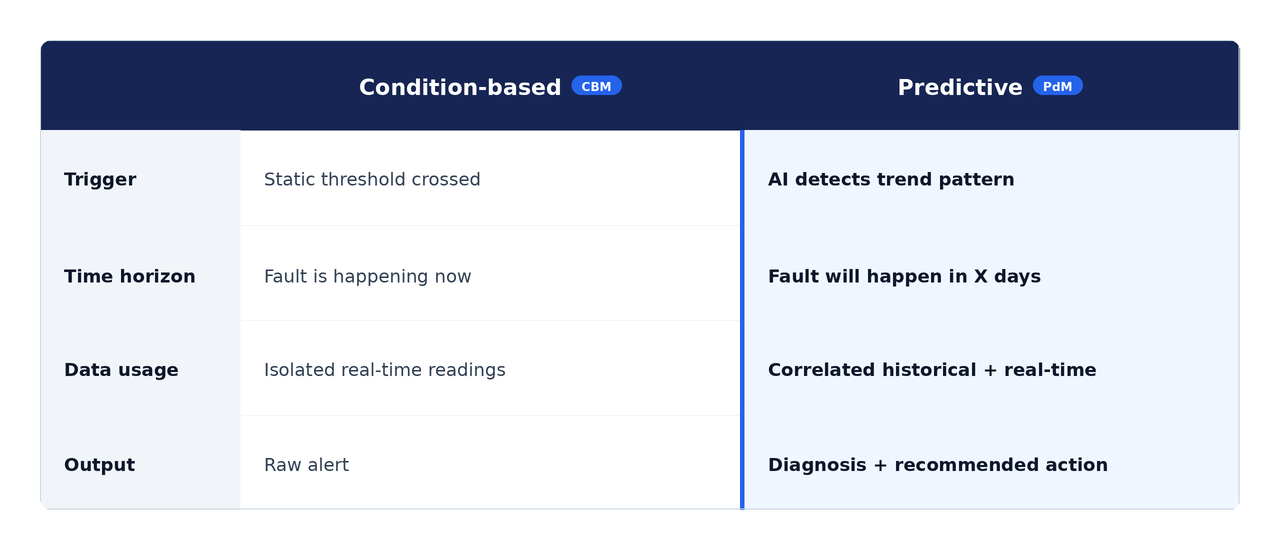
- Condition-based maintenance (CBM) reacts when a real-time signal crosses a threshold. Predictive maintenance (PdM) forecasts failure before any threshold is reached.
- Collecting vibration and temperature data is only step one. Without correlation, context, and prioritization, raw signals produce alert fatigue - not decisions.
- The real gap isn't in the hardware. It's between detection and action. Teams need systems that diagnose, prescribe, and generate work orders automatically.
Facilities today collect more equipment data than at any point in industrial history. Sensors stream vibration, temperature, and runtime metrics around the clock. Yet unplanned downtime keeps draining profitability. According to Siemens' True Cost of Downtime 2024 report, the world's 500 largest companies lose $1.4 trillion annually to unplanned downtime - 11% of their total revenues.
The problem isn't a lack of monitoring. It's condition monitoring that doesn't translate into action.
For maintenance and reliability leaders trying to close that gap, the discussion always comes back to the same two strategies. Understanding the real difference between condition-based maintenance vs. predictive maintenance is the foundation of any program that reduces risk rather than just documenting it.
But the real question isn't which one is better - it's understanding where each strategy ends and where execution has to begin.
The debate around condition-based maintenance vs. predictive maintenance usually starts here.
What is condition-based maintenance (CBM)?
Condition-based maintenance is a proactive strategy that monitors the real-time state of an asset and triggers maintenance only when specific indicators signal degrading performance or approaching failure. It's the most widely used form of condition monitoring in industrial facilities - and for good reason.
Instead of replacing a bearing on a fixed 90-day calendar, CBM relies on continuous monitoring and a threshold rule: if the sensor reads X, do Y.
In practice, teams establish a baseline of normal operation, then define a threshold. If a motor typically runs at 2.5 mm/s vibration and the warning threshold is set at 4.5 mm/s, an alert fires the moment the sensor reads 4.6 mm/s.
Common CBM parameters:
- Vibration - detects imbalance, misalignment, and bearing wear in rotating equipment
- Temperature - flags friction points and electrical hotspots
- Oil analysis - tracks lubricant degradation
Where CBM falls short: It catches anomalies but doesn't distinguish between them. A critical production motor and a redundant backup unit trigger the same queue. Without context, maintenance teams manually triage every alert. And with enough false positives, they stop trusting the system altogether.
What is predictive maintenance (PdM)?
Predictive maintenance takes the foundation of CBM and extends it with AI, historical data, and multi-variable trend analysis. Where CBM asks "is a fault happening right now?", PdM asks "when exactly will a fault occur?"
Rather than a static threshold, PdM monitors compound patterns across multiple data streams simultaneously. A failure isn't always preceded by a spike. Sometimes it's a subtle, correlated shift in vibration, load, and speed that no human-defined rule would catch.
Back to that same motor: the AI ingests millions of operational hours, notices a gradual increase in high-frequency vibration combined with an ambient temperature trend over three weeks, and recognizes the compound signature of early-stage bearing degradation - even though vibration is still at 3.0 mm/s, well below the CBM threshold of 4.5 mm/s. It predicts failure in 21 days and schedules a work order for day 15.
That's the core value of PdM: prescriptive guidance with a time horizon, delivered before physical damage becomes severe. When weighing condition-based maintenance vs. predictive maintenance, knowing a bearing will fail in 21 days rather than discovering it crossed a threshold today is what turns reactive scrambles into scheduled work orders.
Condition-based maintenance vs. Predictive maintenance: the core differences
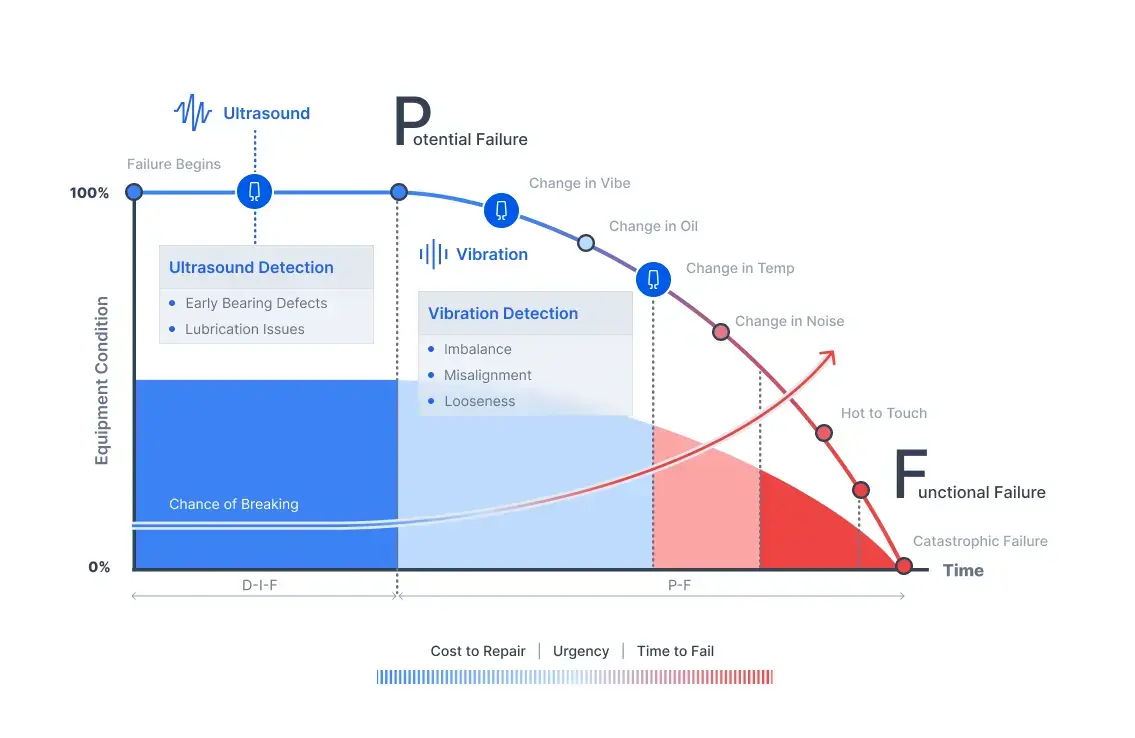
The P-F curve shows where CBM intervenes and where PdM intervenes. Tractian closes what comes after both: the gap between detection and the technician who fixes the problem.
Why CBM and PdM Both Fail Without Execution
CBM and PdM solve different detection problems. When evaluating condition-based maintenance vs. predictive maintenance, most teams focus on detection. Neither solves the execution problem.
CBM tells you a threshold was crossed. PdM tells you a failure is coming. But neither answer the question a maintenance technician actually needs: what do I do right now, and on which asset?
Three gaps consistently prevent monitoring programs, regardless of how sophisticated the detection layer is, from driving outcomes:
- The trust problem. CBM systems with high false-positive rates train teams to distrust alerts. When technicians repeatedly walk to an asset only to find it running normally, they stop treating the system as a source of truth. PdM reduces false positives significantly, but if the diagnosis lacks specificity ("anomaly detected" rather than "early-stage bearing inner race fault, severity moderate"), technicians still need a specialist to validate before acting. Trust isn't just about accuracy. It's about clarity.
- The prioritization void. PdM can forecast failures across dozens of assets simultaneously. That's its strength. And it's liability. A dashboard showing eight assets trending toward failure in the next 30 days doesn't tell a lean team which one to address this week. Without criticality-weighted prioritization built into the system, teams default to the loudest alert or the most familiar asset. Neither is a reliable strategy.
- The workflow disconnect. The gap between insight and action is where most monitoring programs lose value. A PdM system flags a bearing fault predicted in 21 days. Someone exports the alert, opens the CMMS, writes a work order, and assigns a technician… if it doesn't get lost in the queue first. The longer that chain, the more likely the insight expires before it becomes a task.
What Closes the Gap Between CBM, PdM, and Action
Most teams evaluating condition-based maintenance vs. predictive maintenance get stuck choosing between the two. The better question is what needs to be true for either strategy to actually drive action.
Moving from signal detection to confident maintenance execution requires three capabilities that neither CBM nor PdM delivers on its own.
- Correlation. A bearing fault often manifests simultaneously in vibration amplitude, temperature rise, and runtime pattern. Systems that analyze each stream in isolation generate three unrelated alerts instead of one compound failure signature. Multi-variable correlation is what makes the difference.
- Contextualization. A CBM threshold set at 4.5 mm/s doesn't know whether the motor is running at 40% load or full capacity. Effective monitoring must account for load state, ambient environment, and historical baselines - not just the current reading. Without context, even accurate alerts require manual verification to trust.
- Prioritization. A pump feeding a critical production line and a redundant backup unit can produce identical fault signatures. One warrants immediate action; the other can wait for the next scheduled window. Criticality-weighted prioritization is what converts a list of anomalies into a ranked work queue.
Tractian: From Threshold to Work Order in One Platform
Most teams run CBM and PdM as separate condition monitoring layers: one system for real-time alerting, another for trend analysis, and a third for maintenance execution. Every handoff between them is a point where insights get delayed, misinterpreted, or lost.
Tractian eliminates those handoffs by connecting detection, diagnosis, and execution in a single platform.
The Smart Trac Ultra sensor mounts directly on equipment and continuously measures vibration, temperature, runtime, and RPM. It works across more than 100 asset types and samples fast enough to catch faults in their earliest stages - not just once a failure is already underway. It's designed for harsh industrial environments where missing a fault carries real consequences.
That data feeds into Auto Diagnosis, Tractian’s AI engine trained on over 3.5 billion real-world operational samples. It automatically identifies what's wrong - bearing defects, misalignment, imbalance, cavitation, lubrication issues - without anyone manually setting thresholds or configuring models. Think of it as the point where CBM and PdM meet: the system recognizes both active fault signatures and early degradation patterns that haven't crossed a threshold yet.
Every diagnosis comes with a severity rating, a trend direction, and the Tractian Health Score: a single ranked view of your assets by criticality. Instead of a flat list of alerts, teams see exactly which asset needs attention first and why.
And when a fault is confirmed, it doesn't stop at the dashboard. Tractian automatically generates a work order in its native CMMS - or pushes it directly into whichever platform your team already runs - complete with diagnostic context, recommended procedures, and AI-generated SOPs. Technicians receive instructions, not alerts. The mobile app works fully offline, so execution continues even without connectivity.
Frequently asked questions
What's the main difference between condition-based maintenance vs. predictive maintenance?
CBM uses static thresholds to alert when an asset's real-time condition starts degrading. Predictive maintenance uses AI and historical trend analysis to forecast failure well before any CBM threshold is crossed.
How do I know if my current setup is CBM or PdM?
If your system generates alerts when a reading crosses a pre-set threshold, it's CBM. If it analyzes trends across multiple variables over time and forecasts when a failure will occur, it's PdM. Many facilities run both - CBM as a safety net for active faults, PdM for forward-looking scheduling.
Can CBM and PdM run on the same assets at the same time?
Yes, and they should. CBM catches faults that cross a threshold quickly, while PdM tracks slower degradation patterns that may never trigger a traditional alert. Running both together closes the detection gaps that either strategy leaves on its own.
What's the biggest reason predictive maintenance programs fail?
Detection without execution. Teams invest in sensors and analytics but leave a manual gap between the insight and the work order. When a reliability engineer still has to interpret an alert, open a CMMS, and write the task by hand, the speed advantage of PdM disappears.
Does Tractian integrate with our existing CMMS like SAP or IBM Maximo?
Yes. Tractian connects directly with the CMMS platforms teams are already running - including SAP, IBM Maximo, and others. When Auto Diagnosis confirms an anomaly, the work order flows automatically into whichever system your team already uses for execution. No rip-and-replace, no duplicate data entry. The diagnostic intelligence sits on top of your existing workflow, so technicians receive prioritized, context-rich tasks inside the tools they already know.
How long does it take to see value from a predictive maintenance program?
With a platform that provides prescriptive guidance out of the box - like Auto Diagnosis - teams typically catch their first actionable fault within the first few weeks of deployment, before any historical baseline has fully developed.
