

Key Points
- Most plants underestimate the cost of downtime by two to three times. The repair gets counted. The cascade around it does not.
- The real cost spans four areas: lost production, idle and overtime labor, emergency parts and freight, and systemic losses like scrapped batches, restart defects, and customer penalties.
- Catching a failure early is roughly ten times cheaper than reacting to it. The savings sit outside the maintenance budget.
- A standard cost formula is the starting point. Without one, downtime gets written off as a cost of doing business instead of a number you can actually shrink.
- Real-time visibility plus condition monitoring on critical assets is what turns unplanned stops into planned work.
Before you read further, run Tractian's downtime calculator on your last big stop. The rest of this blog will land harder once you have your own number to compare against.
The Cost of Downtime Your Work Order Will Never Capture
When a critical asset fails, attention goes to the machine first. What broke? How fast can we get it running? That is the right operational reflex, but it is not a financial one.
Here is the problem. A maintenance work order captures the repair: parts, labor hours, the contractor invoice. It does not capture the units that did not get made. It does not capture the twelve people standing around the line on full pay. It does not capture the weekend overtime needed to recover the schedule, or the warmup defects produced in the first hour after restart.
Those losses end up in production reports, finance ledgers, logistics invoices, and customer service tickets. Each one absorbs a slice of the cost as routine variance. None of them call it downtime.
The result is that most plants are carrying two to three times more cost of downtime than their numbers suggest. That undercount is the reason maintenance investments that would pay back in months sit on the shelf for years.
The Four Areas Where the Cost of Downtime Adds Up
The full cost of a single unplanned stop lives in four places, not one. Most plants track the first reliably, the second partially, and the third and fourth almost not at all.
1. Lost production
The most obvious loss. Units you did not make, multiplied by the margin on each unit. On a fast line with healthy margin, a two-hour stop can wipe out the day's profit on its own.
The common mistake is assuming you will make it back later. Sometimes you can, with overtime or a weekend shift. But that recovery production comes at premium labor rates, and on most lines the bottleneck is already running flat out. Output you lose in the original window is usually output you do not get back.
2. Idle and recovery labor
The line stops. The people on the line do not. Operators, material handlers, quality techs, and supervisors stay on the clock with nothing to run. Twelve people standing idle for four hours is forty-eight paid hours of nothing.
Then comes recovery. Overtime at time-and-a-half to catch up the schedule. Emergency contractor rates for specialist work your team cannot do internally. Travel costs if those specialists have to fly in. All of it real, all of it recurring, and almost none of it tied back to the original stop on any internal report.
3. Emergency parts and freight
Reactive repairs need parts you did not plan for. That means rush shipping, premium pricing from backup suppliers when the main one is dry, and occasionally air freight across an ocean because nobody stocks the part locally. A bearing that costs $400 on a normal cycle can cost $1,800 by the time it lands on your dock at 2 a.m.
The same logic applies to lubricants, tooling, and consumables pulled into the repair. Each one has a normal cost and an emergency cost. The gap between them is downtime overhead that nobody attributes back to the failure.
4. Systemic losses
This is where the biggest unrecorded costs live.
- Scrapped work in progress. In food and beverage, chemicals, and any process with temperature- or time-sensitive product, an unplanned stop ruins the batch. Raw material lost, WIP lost, plus disposal cost on top.
- Defects on restart. Lines coming back from an unplanned stop produce more defects during warmup. Some get scrapped. Some make it to the customer, which costs more.
- Late delivery penalties and lost customers. Contractual late fees are direct and easy to see. Losing a customer after one too many missed shipments is harder to see and usually more expensive.
- Safety exposure on restart. A disproportionate share of industrial incidents happen during startup and shutdown. Rushed restarts skip the procedures that exist to prevent them.
- Maintenance team turnover. Teams that live in firefighting mode quit faster than teams working in a planned environment. Replacing an experienced technician costs more than most plants admit, especially when the institutional knowledge walks out with them.
Add it up across all four areas, and the fully loaded cost of an hour of unplanned downtime in a mid-size plant is usually two to five times what the basic revenue calculation shows.
A Working Formula for the Cost of Downtime
This is the formula for the true cost of downtime. Run it on a specific event, then on your annual downtime hours.
Total Downtime Cost = LP + IL + RL + EP + SL
- LP (Lost Production) = Units per hour × Gross margin per unit × Downtime hours
- IL (Idle Labor) = Affected staff × Loaded hourly rate × Downtime hours
- RL (Recovery Labor) = Overtime hours to recover schedule × Overtime rate
- EP (Emergency Parts and Freight) = Premium pricing + Expedited shipping + Specialist fees
- SL (Systemic Losses) = Scrapped WIP + Restart defect cost + Delivery penalties + Allocated turnover and safety risk
The first three are usually quick to pull together. The fourth takes a procurement pull. The fifth takes the longest to estimate, but it is also where the biggest numbers usually hide.
If you want a faster baseline across multiple events, Tractian's downtime calculator handles the first three components automatically and lets you compare totals across machines, lines, and time periods. It is the quickest way to move from anecdotal estimates to a number you can defend.
A Worksheet for Your Last Major Stop
Pick the last unplanned event longer than two hours and fill this in. The total almost always exceeds what the work order shows.
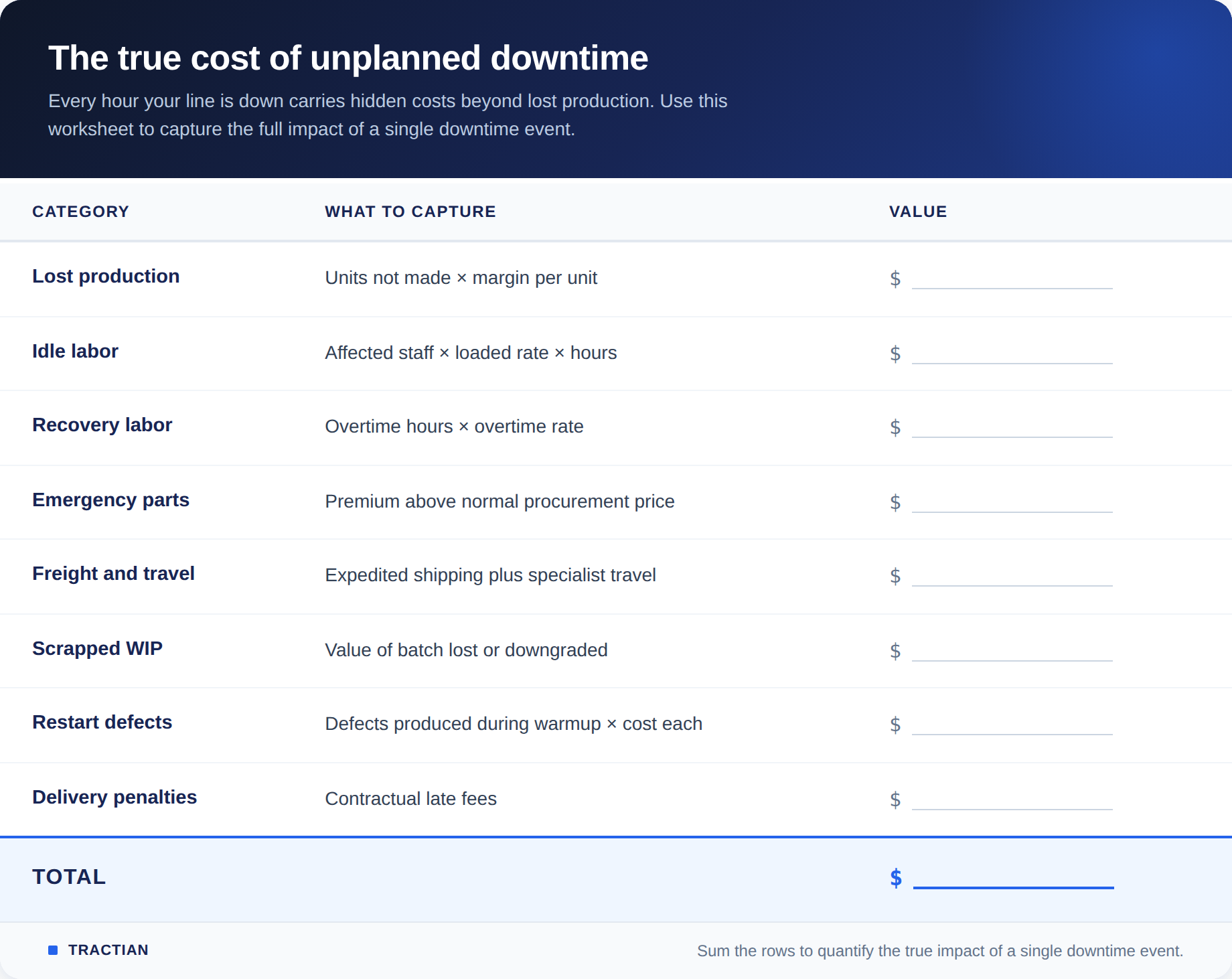
If the total is bigger than you expected, that is the point. The gap between what the work order recorded and what this worksheet shows is the cost that has been hiding inside operating variance the whole time.
Why Reactive Always Costs More
Catching a developing failure early versus reacting to it after the fact is roughly a ten-to-one cost difference. But that gap only becomes obvious when the cost of downtime is calculated honestly.
Take a bearing showing early-stage wear. Caught early, it gets replaced during a planned shift change at standard labor rates. The part is ordered on a normal procurement cycle. There is no production impact.
Now run the same bearing to failure. The line goes down without warning, at the worst possible time. All five cost categories above light up at once. The failure damages adjacent components, so the repair scope expands. Recovery drags on. The bill is a lot bigger, and that does not even count the customer relationship damage if a shipment slips.
This is why condition-based and predictive maintenance generate the returns they do. The savings are not in the maintenance budget. They live in the four cost areas above, which shrink when failures get caught early and converted from emergencies into planned work.
What It Takes to Convert Unplanned Stops Into Planned Work
Three things, in this order:
Real-time machine state data. You cannot reduce downtime you cannot see. Shift logs reconstructed from operator memory miss the short stops that, added together, are often the biggest source of lost availability. Continuous monitoring captures every transition automatically and timestamps it. Stops become measurable in minutes, not reconstructed hours later.
Condition monitoring on critical assets. Vibration, temperature, and current signature analysis spot the early stages of mechanical failure weeks before the line stops. That lead time is what makes the conversion from unplanned to planned possible. Without it, you are reacting. With it, you are scheduling.
A reliability process that actually closes the loop. Detection alone does not reduce downtime. Every unplanned event needs a structured root cause analysis. Every recurring cause needs a fix that prevents the next one. Without that discipline, the same failures repeat and your data becomes a reporting tool instead of an improvement tool.
Plants that put all three in place consistently move unplanned downtime from 80 to 90 percent of total downtime, where most reactive operations sit, down to 30 to 40 percent. At that point, the operation plans around the work instead of being controlled by it.
A Step-by-Step Plan to Reduce Downtime Cost
- Set your baseline. Use the formula above on the last twelve months. Break it down by line and by asset. The pattern will be sharper than you expect. In most plants, a handful of assets drive the majority of cost.
- Agree on what counts as downtime. Get production, maintenance, and finance on the same page. Micro-stops under five minutes add up fast. They should be in the definition, not excluded for convenience.
- Put machine state monitoring on the bottleneck and your most critical assets first. Real-time visibility is the foundation. Everything else builds on it.
- Add condition monitoring and predictive maintenance to your highest-cost assets. Target the ones where a single failure event drives a big fully loaded cost. That is not always the same as the ones that fail most often. Cost is the deciding factor, not frequency.
- Run a root cause process on every event over a set threshold. Pick a threshold that triggers structured analysis without burying the team. Two hours is a common place to start.
- Track unplanned downtime as a percentage of total downtime. This is the cleanest sign that the program is working. Push that ratio down, and total hours follow.
For the operational side of this, including OEE breakdown, MTTR reduction, SMED, and TPM, our guide on how to reduce downtime in manufacturing covers the system-level strategies that pair with the cost framework here.
Stop Paying for Downtime You Cannot See
Unplanned downtime is not a fixed cost of doing business. It is a measurable loss that compounds across production, labor, parts, and customer relationships. Most plants are carrying two to five times more of it than their books show, because the cost lives in places the maintenance system was never designed to track.
The way out is not a bigger maintenance budget. It is visibility. The moment machine state is captured in real time and critical assets are under condition monitoring, downtime stops being a quarterly surprise and starts being something you can plan around.
That is what Tractian's Sensor + Software solution is built to do. Vibration, temperature, and current monitoring detect failures weeks before they stop the line. Production monitoring captures every state change automatically, so stops are measured in minutes instead of reconstructed from memory at the end of the shift. The dashboard ties it together: availability by machine, line, and shift, with the cost of each event tracked against the work order it generated.
If you have not run the numbers on your last major event, start there. Use the calculator to determine cost of downtime, pull the data from the last twelve months, and bring the total to the next budget conversation. The case for predictive maintenance is rarely about technology. It is about a number that, once you calculate it honestly, is hard to argue with.
